
多主架构:VLDB技术论文《Taurus MM: bringing multi-master to the cloud》解读
本文分享自华为云社区《多主创新,让云数据库性能更卓越》,作者: GaussDB 数据库。
华为《Taurus MM: bringing multi-master to the cloud》论文被国际数据库顶会VLDB 2023录用,这篇论文里讲述了符合云原生数据库特点的超燃技术。介绍了如何通过各种黑科技减少云原生数据库的网络消耗,进而提升云原生数据库的性能和稳定性。下面就让我们抽丝剥茧,细细品味技术的魅力,揭开华为云数据库多主技术的面纱。
说明:技术论文中的Taurus在华为云商用的产品名是GaussDB(for MySQL),是GaussDB(for MySQL)的云原生架构技术版本。
引言
现下,大型高性能数据库通常采用一写(主)多读(副本)这种标准部署方式来提高业务吞吐量。。然而,单主会导致单点故障,同时限制了写扩展性,也就是说带来了可用性和性能的双重挑战。而性能和可用性是衡量一个企业级数据库是否优秀最关键的两个方面。由此多主数据库应运而生。
多主数据库有Shared-nothing和Shared-storage两种架构。谷歌Spanner、亚马逊DynamoDB、CockroachDB、OceanBase及其他一些数据库采用了Shared-nothing架构。亚马逊Aurora多主数据库、Oracle RAC和IBM DB2 pureScale采用了Shared-storage架构。
对于Shared-nothing架构的多主,每个节点对一个小数据子集执行计算和存储。在高度分区的工作负载场景下,这类架构可以提供非常高的可扩展性。但在如下不均衡的工作负载场景中,其优势受限——节点数越多可能意味着节点间数据交换越多:
- 数据无明显分区特征;
- 工作负载随时间变化;
- 存在热点数据场景。
同时,Shared-nothing架构使用分布式提交协议,信息同步多轮交换,降低了多主系统的性能。
对于传统的Shared-storage架构,计算层与存储层分离。这类架构由于其高度集成及密集网络通信的特点,需要高端和专用的网络硬件,更适用于对成本不敏感的线下数据中心部署,不适用于云原生数据库。云的最核心特点是通过多用户共享基础设施平摊成本(包括网络硬件)来实现高成本收益。
云数据库性能的关键是对共享网络的优化。华为云数据库多主(Multi-Master)专注于从消息的数量和大小两方面减少网络流量,这一目标的达成并不容易,很多公司尝试过,但目前还没有看到成功案例。
华为云数据库多主黑科技解析
那究竟如何实现多主上云呢?华为云数据库多主有哪些硬核技术突破呢?
通过对网络流量消耗进行分析和归类后,我们发现主要的网络消耗是由于主节点写页面、时钟同步和锁信息交互三个方面。华为云数据库在如上三个方面进行了探索和尝试,并取得了可喜成绩。下面详细讨论在每类开销上,华为云数据库是如何尽最大可能减少网络计算开销的。
减少直接页面写入带来的网络消耗
此问题已有解决方案——2020年SIGMOD会议上我们向会议研究团体介绍了华为云原生数据库单主解决方案:“Log As Database”(日志即数据库)。
简单说就是华为云数据库计算与存储分离,计算层包含一写(主)多读(副本)。计算层的作用是执行数据库的修改,主要功能有:接入连接、执行查询、管理事务以及生成WAL日志记录(日志用于描述对数据库页所做的修改)。事务更新时先生成日志记录,主节点将这些日志记录传送到存储层的Log Stores中进行存储,通过日志回放生成数据,从而无需通过网络执行整个数据页面的写入,节省了所需的网络带宽。详细见图1。
图1:华为云数据库组件及分层架构
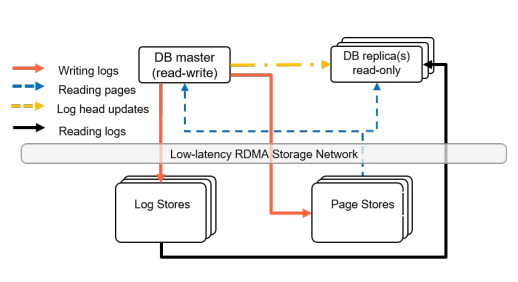
华为云数据库多主重用了一主多读架构中的思想,采用Shared-storage体系结构,所有Master之间共享日志存储和页面存储,继续沿用悲观并发控制,且引入了全局锁管理器GLM(Global Lock Manager)。
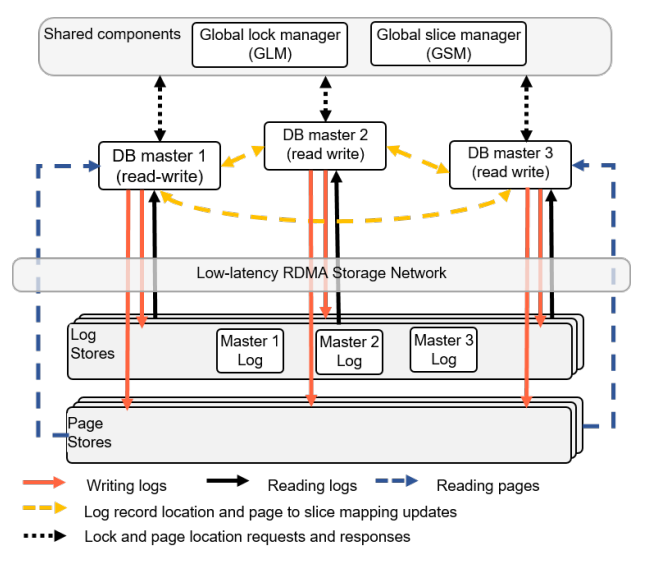
各Master维护自己的预写日志(WAL)。用户事务在单主上执行——没有分布式事务。日志记录写入执行事务的主机中。每个Master会定期将带有位置信息标识(哪个Master生成的)的新生成日志提交给所有其他Master。通过位置信息,各Master读取其他所有Master上生成的日志记录,并更新进自己的缓冲池页面中。详细如图2所示。
图2:华为云数据库多主组件及分层架构
减少时钟同步带来的网络消耗
多主数据库特有的第二个网络开销来源是时钟同步。在单主数据库上,事务时钟信息可以直接使用本地物理时钟。然而,在分布式系统中,不同节点上的物理时钟很难精确保持一致。而通过网络连接同步和获取时间戳,会带来无法容忍的时间延迟。因此,对于分布式数据库物理时钟这种方法不再适用。
这在业界不是一个新近才提出的问题。早在20世纪70年代,莱斯利·兰伯特就为了解决此问题,提出并发明了标量时钟(常称为逻辑时钟,或兰伯特时钟)。此标量时钟由一个数字组成时间戳,仅在消息交换期间进行不同计算机间的时钟同步。兰伯特时钟的算法简单而优雅,但要通过它创建数据库的分布式快照基本不可能,而分布式快照对分布式数据库的性能又是非常重要的。同时,逻辑时钟无法保存事务间的因果关系。简单说,就是假设𝑇𝑆 (𝑎) < 𝑇𝑆 (𝑏),也就是事务a早于事务b,使用逻辑时钟,无法识别是a导致了b,还是a和b间仅是并发无因果关系。
逻辑时钟之后又出现了矢量时钟,用于解决逻辑时钟的局限性。然而,虽然矢量时钟能够创建分布式快照,但是,矢量时钟有一个很大的缺点——加大了消息的大小。数据库之间的消息本来很小,矢量时间戳的加入使消息的大小增大为原来的两至三倍,从而加大了网络开销。
华为云数据库团队发明了一种新型的时钟——VS时钟(VECTOR-SCALAR CLOCKS)。其关键的创新是,它既可以产生矢量时间戳,又可以产生标量时间戳,实现优势互补。VS时钟的应用,既达成了较小的网络消耗又保证了数据库全局快照的创建能力。例如,由于每个节点对同一页面的修改必须是串行的,无需关注因果(先后)关系,因此对单个页面修改的日志记录添加时间戳时,发放标量时间戳即可;当为全局快照的创建发放时间戳时,需要使用完整的矢量时间戳以便理清各主节点事务间的先后关系。由于全局快照这一类事件的数量级远小于日志记录,故而全局快照矢量时间戳所带来的空间开销可以忽略不计。
优化锁协议减少网络消耗
多主数据库的第三个主要网络开销是锁信息交互带来的开销。
对数据库的某些更改需要被视为原子更改,例如对内部数据库页的修改,或事务对记录行的修改。通常,数据库使用锁来实现原子性。通过观察我们得到一个重要结论:鉴于所有行都是存储在页面上的,因此要修改或读取对应行,就意味着必须修改或读取此行所在的页面。
由此,我们提出了,对于数据库最底层的行页混合锁定,行锁信息不再作为单独的消息进行传递,而是作为页锁的一部分来传递。这种方案,会将锁信息的数量显著减少,从而进一步降低了网络负载。
数据库系统的行锁类型有:(普通)共享和独占行锁、间隙锁、next-key锁和意向锁,在华为云数据库多主中讨论的“行锁”包括了所有这些类型的锁。行锁可以以不同的方式管理,我们在分析和对比了下面的三种不同方法后,选择了行锁跟随页锁的方法。
GLM管理行锁:让全局锁管理器GLM同时管理页锁和行锁。这种方法每次行锁获取时都需要走GLM,因而会增加网络负载。DB2 pureScale采用了这种方法,并进行了各种优化。GLM管理行锁的方案,网络流量很高,即使在工作负载大部分是分区的场景下,也依然很高;此外,GLM还必须要能支持底层系统使用的所有行锁类型及这些锁之间的复杂交互。
在页面上存储行锁:将页面的行锁信息存储在本身所在的页面上。Oracle RAC采用这种方法。华为云数据库未采用这种方法,有两个原因:1)它需要将行锁获取/释放记录写入日志,从而增加了网络负载;2)它需要更改磁盘上的页面格式,华为云数据库由单主升级到多主时必须做这种数据库格式转换,将损失华为云数据库的原有优势。
行锁跟随页锁:当Master获取页面锁时,一并获取该页面上的行锁列表,包括持有的锁和挂起的锁请求。之后,Master可以在页面上授予额外的行锁,当然前提是这些行锁要与其页锁兼容。当Master向GLM释放页锁时,同时会将页面上当前行锁的信息发送给GLM。需要说明的是,锁请求挂起的信息虽不是很关键,但它对GLM和Master上的锁调度决策很有用,因此也会传递给GLM。华为云数据库最终选择了这种方法。
在华为云数据库中,GLM只管理页锁,不授予或释放行锁,但页锁信息中跟随有行锁信息。GLM将页面上的锁授予Master时,会将页的版本号(如果有)发给Master,从而该Master将拥有页的最新版本,以及页上的行锁列表。接收了页锁的Master会将行锁信息添加到其本地锁管理器LLM中。当Master释放页锁(自愿或响应请求)时,它向GLM递交页面版本号和页面上的行锁列表。
在不涉及数据一致性的前提下,Master上的行锁更改不需要立即与其他Master同步。除非另外的Master要请求锁定的页面与当前Master是有锁冲突的同一个页面。这种情况下页锁释放和回收流程将被启用,行锁信息被一并发送到GLM,将很好地避免行锁授予或等待时频繁联系GLM,可以显著减少行锁网络流量。以下是更详细的流程:
• 释放页锁时(自愿或被动响应回收):
–Master上:有关页面上所有行锁的信息将发送到GLM。
–GLM上:接收到的行锁信息缓存在内存中。
• 请求和授予页锁时:
–Master上:为了响应本地事务的行锁请求,Master必须持有行所在页上的锁。如果Master没有拿到所需的页锁,它会首先向GLM发送页锁请求。
–GLM上:当页面锁请求到达时,GLM会判断同一页面是否有其他冲突锁或者挂起的其他Master锁请求,如果有,新的Master所请求需要等待。当GLM准备好授予页锁时,它首先回收页面上的冲突锁(如果有),并捕获新接收到的行锁信息;之后将页面锁授予Master,并将响应消息、行锁信息及页面的最新版本号一并发给Master。
–Master上:收到页锁授权响应消息后,将行锁信息添加到LLM(Local Lock Manager)中,并刷新页面版本号。本地事务再次尝试后可以成功获取所需的行锁。
华为云数据库多主架构效果验证。
我们首先测试了华为云数据库多主架构自身的性能和可扩展性。同时,我们将华为云数据库多主与亚马逊的Aurora 多主(我们所知的唯一一个云原生Shared-storage数据库)进行了对比。最后,我们还将华为云数据库多主与Shared-nothing架构的CockroachDB进行了对比。
测试环境说明
实验验证运行在一个最多8个主节点的集群上,并在4个具有相同硬件配置的节点上部署了存储层(数据存储和日志存储)。详细见表1。
表1:测试环境规格
|
配置项 |
规格 |
说明 |
|
集群规模 |
4存储节点&最多8个主节点 |
存储节点和主节点的硬件配置相同。 |
|
CPU |
Intel Xeon Gold 6278C 2.6GHz CPU 28核*2 |
在每个节点上,主Master独用一个CPU,工作负载驱动程序使用第二个CPU。 |
|
操作系统 |
CentOS 7.0 |
- |
|
Buffer Pool |
128GB |
- |
|
网络 |
25Gbps |
- |
在所有实验中均使用了两个标准工作负载:Sysbench和Percona TPC-C。
Sysbench是一个流行的基准测试,它可以生成插入、删除、更新、点查、范围查询及这些类型的各种组合。我们扩展了Sysbench,以便控制数据共享的程度。
在一个由N个主节点组成的集群上,实验将表逻辑上分为N+1组。前N组中的表是私有表,即每个组被分配给一个单独的主节点,只有指定的主节点可以访问对应组中的表。最后一个组是共享的,即任何主节点都可以访问此组中的表。
当实验指定共享程度为X%时,表示X%的数据库读写访问是针对共享表进行的,其余的读写访问是针对私有表进行的。完全分区的工作负载对应于X=0%,完全共享的工作负载对应于X=100%。实验设置中,对于共享工作负载场景,每个组包括100个表,每个主节点访问100个私有表以及100个共享表。对于完全分区的工作负载,每个组包含200个完全分区的表。每个表有2.35M行数据,每行约200字节, 因此对于所有的实验,每个主节点都可以访问约100GB的数据。
TPC-C是评估OLTP系统性能的行业标准性基准。数据按仓库跨主节点分区,但10%的事务访问了远程的数据分区。除非另有说明,我们使用的是1000个仓库配置。
华为云数据库多主性能测试结果
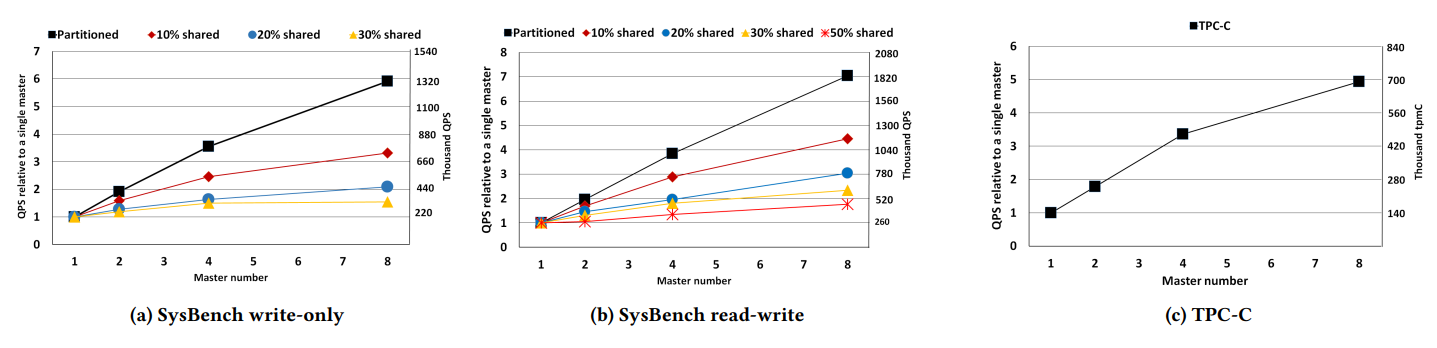
华为云数据库多主在Sysbench只写、Sysbench读写(80%读取,20%写入)和TPC-C基准测试上的性能表现如图3所示,3(a-c)。
- 在X轴上,集群大小从1个主节点到8个主节点。
- 在Y轴上,显示了绝对吞吐量以及相对于单个主节点的吞吐量。
- Sysbench测试结果的每条线对应不同程度的数据共享。TPC-C使用的是固定的10%共享查询。
- 对于只读工作负载,由于多版本的存在,其可以完美地扩展,因此这里略去不显示
从图中可以看出,对于完全分区的工作负载,随着主节点数量的增加其性能几乎线性扩展。8个主节点集群规模下,10%共享的Sysbench只写和读写场景,相较单个主节点,分别实现了3.5倍、4.5倍的加速; TPC-C工作负载下,相较单个主节点,实现了5倍的加速。
正如预期的一样,可扩展性受数据共享程度的影响较大。同样8个主节点集群上,30%共享负载下的只写和50%共享负载下的读写,相较单个主节点,均实现了不到2倍的加速。
由于可用的硬件有限,我们未验证16个主节点集群的结果,但从图中不难看出,8个主节点的可扩展性已接近线性。
图3. 华为云数据库多主Sysbench和TPC-C性能测试结果
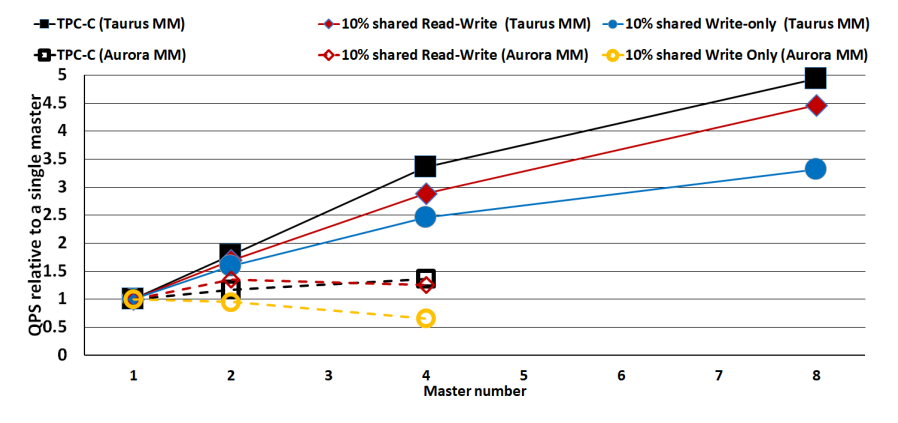
与Aurora多主的性能对比
图4对比了基于相同CPU核数和内存缓冲池情况下华为云数据库多主和Aurora多主的性能。在所有测试中,我们观察到单主情况下,华为云数据库的性能超过了Aurora。由于Aurora多主除了计算层之外,未暴露其他硬件细节,因此我们只测试对比了各自相对于其单主的性能数据。鉴于Aurora不允许超过4个主节点,因此8个主节点性能测试仅在华为云数据库多主上进行。对于完全分区的工作负载,两个数据库的扩展几乎相同,故测试时省略了不同分区负载的差异对比,而是选取了具有代表性的10%共享负载做性能对比测试。在此较小的共享负载场景下,华为云数据库处理工作负载的能力要好得多。在共享写入工作负载场景下,我们发现Aurora中所有主节点上存在大量因冲突导致的被中止事务,从而带来主节点之间的性能不均衡。华为云数据库的多主由于其基于混合行页锁的并发控制,未发生任何事务中止。
图4 华为云数据库多主 VS Aurora多主
与CockroachDB的性能对比
我们还将华为云数据库多主与基于Shared-nothing架构的CockroachDB(简称CRDB)进行了比较。之所以选择CRDB,是因为它是开源的,且根据相关报告分析,其性能比Spanner和TiDB更好。
实验使用两种配置规格,即分别将CRDB和华为云数据库部署在相同的6节点和12节点集群上,从而比较相同硬件条件下双方的性能。
由于华为云数据库专门使用4个节点用于存储层,而CRDB为Shared-nothing架构,每个节点上既有计算层又有存储层,因此将6个和12个节点CRDB分别与2个主节点和8个主节点的华为云数据库多主进行了比较。
对于CRDB和华为云数据库多主,实验时使用了尽可能大的连接数来提高吞吐量。对于华为云数据库多主来说,每个主节点上的连接数为64个;对于CRDB,每个主节点上的连接数从128到512不等。
在CRDB上,我们运行了CRDB附带的类似TPC-C的基准测试。对于华为云数据库多主,我们运行了Percona TPC-C。在表2中列出了1000和5000个仓库的结果。对于每次运行,我们记录了每秒可处理的新订单事务数(tpmC)、事务平均请求时延和95%事务的请求时延。在所有测试场景下:
- 华为云数据库多主吞吐量都明显更高,从6节点、5000个仓库的吞吐量高出60%,到12个节点、1000个仓库的吞吐量高出320%。
- 华为云数据库双主的交易延迟也要低得多,平均请求时延和95%事务的请求时延均低得多。
- 我们还计算了一个扩展比,即12节点相较6节点其吞吐量的增加比例,华为云数据库多主要优于CRDB。
正如引言中所指出的,Shared-nothing架构的开销受分布式事务提交的影响更明显,分布式事务提交的开销随着事务中涉及的节点数量的增加而增长。对于给定的工作负载,效率受限于事务复杂性。
表2 华为云数据库多主 VS CockroachDB: TPC-C结果
|
华为云数据库MM |
CRDB |
|||
|
1000w |
5000w |
1000w |
5000w |
|
|
6节点 tpmC |
250000 |
216000 |
121000 |
137000 |
|
时延(ms) |
17/48 |
16/35 |
90/150 |
220/620 |
|
12节点 tpmC |
691000 |
734000 |
164000 |
279000 |
|
时延(ms) |
21/106 |
19/80 |
150/300 |
590/1280 |
|
比例因子 |
2.8 |
3.4 |
1.4 |
2 |
|
效率 |
0.7 |
0.8 |
0.7 |
1.0 |
总结
华为云数据库多主是专门为云环境设计的云原生多主OLTP数据库系统。它是一个存算分离的云原生数据库系统,使用全局锁管理器来协调对数据库页和行的读写访问。现实业务中的许多OLTP工作负载大多是可分区的,其中只有一小部分页面在多个主节点之间共享。例如,在TPC-C中,只有10%的访问是对远程仓库的访问。华为云数据库多主设计的一个关键目标是为了在共享程度低的工作负载上实现良好的性能和可扩展性。
华为云数据库多主采用了两个关键创新技术: VS(vector-scalar)时钟和混合行页锁,旨在降低网络负载和提高性能。VS时钟通过对系统中更频繁的消息(日志记录)使用单个标量时间戳,而数量很少的消息使用矢量时间戳来降低网络负载。同时,使用VS时钟,系统保留了查看系统级事务一致性状态的能力。混合行页锁技术通过减少发送到全局锁管理器的锁请求数量来提高事务吞吐量和减少延迟。特别是,如果页面被主节点访问一段时间后,行页锁将自动委托给单一的主节点。我们的实验结果证实了华为云数据库多主系统的性能和可扩展性。在TPC-C基准测试中, 4个主节点的最大扩展效率为84%, 8个主节点的最大扩展效率为62%。在最大8个计算节点的集群上,华为云数据库多主在TPC-C上展示了优于Aurora多主和CRDB的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号