3天上手Ascend C编程丨带你认识Ascend C基本概念及常用接口
本文分享自《 【2023 · CANN训练营第一季】——Ascend C算子开发入门——第一次课(核函数的定义及实现)》,作者:dayao。
Ascend C是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。
时间充足的小伙伴推荐去看官方教程:Ascend C官方教程
想省时省力快速入门可以看这篇文章,为你系统化梳理AscendC编程最重要的知识点,3天快速上手不迷路!
第1天学习要点:

一、使用Ascend C有哪些优势
-
C/C++原语编程
-
编程模型屏蔽硬件差异,编程范式提高开发效率
-
多层级API封装,从简单到灵活,兼顾易用与高效
-
孪生调试,CPU侧模拟NPU侧的行为,可先在CPU侧调试
二、核函数
核函数(Kernel Function)是Ascend C算子kernel侧实现的入口。Ascend C允许用户使用核函数这种C/C++函数的语法扩展来管理设备端的运行代码,用户在核函数中进行算子类对象的创建和其成员函数的调用,由此实现该算子的所有功能。核函数是主机端和设备端连接的桥梁。
1、核函数定义
核函数是直接在设备端执行的代码。在核函数中,需要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核将并行执行同一个计算任务。核函数需要按照如下规则进行编写。

1、函数类型限定符

2、必须具有void返回类型
3、变量类型限定符

为了方便:指针入参变量统一的类型定义为__gm__ uint8_t*。用户统一使用uint8_t类型的指针,并在使用时转换为实际的指针类型;亦可直接传入实际的指针类型。
2、核函数调用
核函数的调用语句是C/C++函数调用语句的一种扩展。不同于常见的function_name(argument list)函数调用方式,核函数使用内核调用符<<<...>>>这种语法形式,来规定核函数的执行配置:

1、内核调用符这种调用方式,仅可在NPU侧编译时调用,CPU侧编译无法识别该符号。
2、核函数的调用是异步的,核函数的调用结束后,控制权立刻返回给主机端,可以调用aclrtSynchronizeStream函数来强制主机端程序等待所有核函数执行完毕。
3、算子运行验证
Ascend C算子可用CPU模式或NPU模式执行
CPU模式:算子功能调试用,可以模拟在NPU上的计算行为,不需要依赖昇腾设备
NPU模式:算子功能/性能调试,可以使用NPU的强大算力进行运算加速
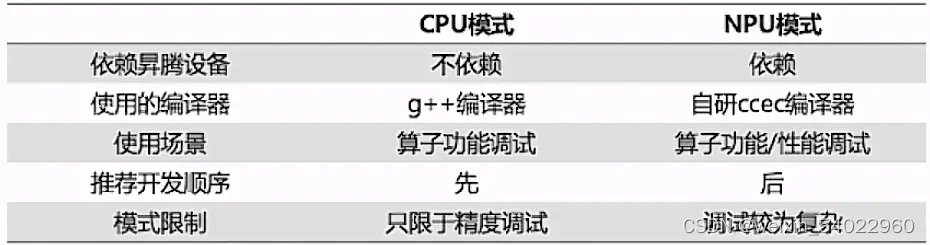
4、代码里使用内置宏 __CCE_KT_TEST__标识被宏包括的代码在CPU或NPU模式下编译。
#ifdef __CCE_KT_TEST__ //表示在CPU模式下会编译该段代码 #ifndef __CCE_KT_TEST__ //表示在NPU模式下会编译该段代码
三、helloworld样例演示
1、代码
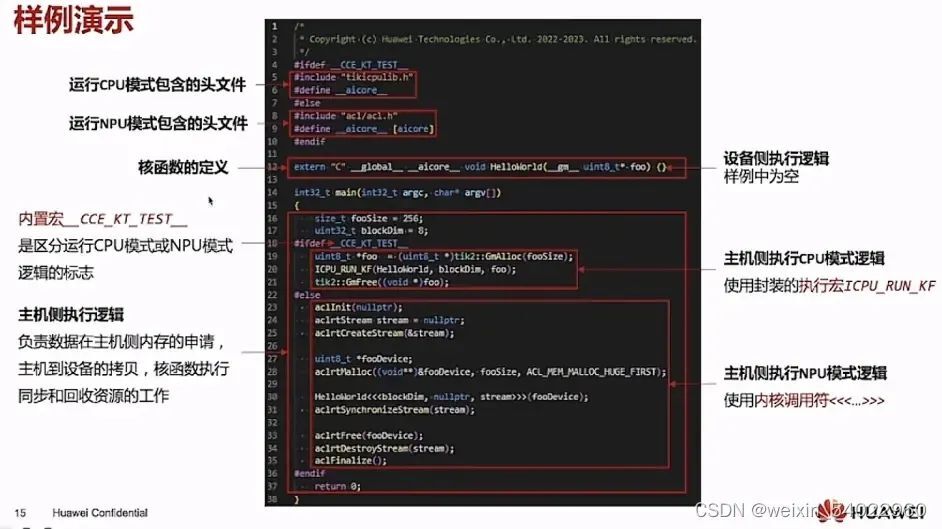
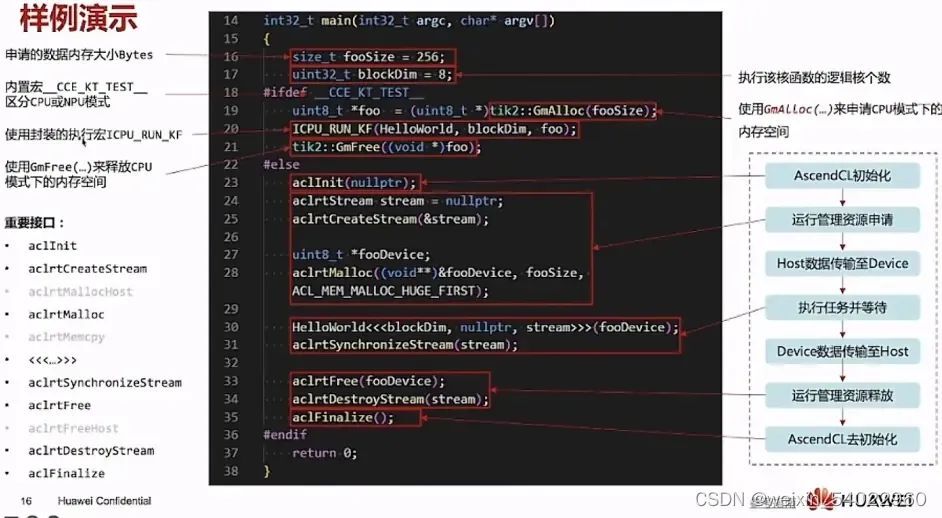
2、编译与运行


四、常用数据定义
1、GlobalTensor
GlobalTensor用来存放Global Memory(外部存储)的全局数据。
template <typename T> class GlobalTensor { void SetGlobalBuffer(__gm__ T* buffer, uint32_t bufferSize); // 传入全局数据的指针,并手动设置一个buffer size,初始化GlobalTensor }
buffer:主机侧传入的全局数据指针
bufferSize:所包含的类型为T的数据个数,单位为 element,需自行保证不会超出实际数据的长度
类型T支持所有数据类型,但需要遵循使用此GlobalTensor的指令的数据类型支持情况。
SetGlobalBuffer用于设置GlobalTensor的存储位置:buffer指向外部存储的起始地址,bufferSize为Tensor所占外部存储的大小,如指向的外部存储有连续256个int32_t,则其dataSize为256。代码示例:
void Init(__gm__ uint8_t *__restrict__ src_gm, __gm__ uint8_t *__restrict__ dst_gm) { uint32_t dataSize = 256; //设置input_global的大小为256 GlobalTensor<int32_t> inputGlobal; // 类型为int32_t inputGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ int32_t *>(src_gm), dataSize); // 设置源操作数在Global Memmory上的起始地址为src_gm,所占外部存储的大小为256个int32_t LocalTensor<int32_t> inputLocal = inQueueX.AllocTensor<int32_t>(); DataCopy(inoutLocal, inputGlobal, dataSize); // 将Global Memmory上的inputGlobal拷贝到Local Memmory的inputLocal上 ... }
2、LocalTensor
用于存放AI Core中Local Memory(内部存储)的数据,支持QuePosition为VECIN、VECOUT、A1、A2、B1、B2、CO1、CO2。
template <typename T> class LocalTensor { T GetValue(const uint32_t offset) const; template <typename T1> void SetValue(const uint32_t offset, const T1 value) const; LocalTensor operator[](const uint32_t offset) const; uint32_t GetSize() const; }
函数说明:类型T支持所有数据类型,但需要遵循使用此LocalTensor的指令的数据类型支持情况。

代码示例:
// srcLen = 256, num = 100, M=50 // 示例1 for (int32_t i = 0; i < srcLen; ++i) { input_local.SetValue(i, num); // 对input_local中第i个位置进行赋值为num } // 示例1结果如下: // 数据(input_local): [100 100 100 ... 100] // 示例2 for (int32_t i = 0; i < srcLen; ++i) { auto element = input_local.GetValue(i); // 获取input_local中第i个位置的数值 } // 示例2结果如下: // element 为100 // 示例3 auto size = input_local.GetSize(); // 获取input_local的长度,size大小为input_local有多少个element // 示例3结果如下: // size大小为srcLen,256。 // 示例4 Add(output_local[M], input_local[M], input_local2[M], M); // operator[]使用方法,output_local[M]为从起始地址开始偏移量为M的新tensor // 示例4结果如下: // 输入数据(input_local): [100 100 100 ... 100] // 输入数据(input_local2): [1 2 3 ... 50] // 输出数据(output_local): [101 102 103 ... 150]
五、多层级API接口
Ascend C提供了多层级的0-3级API,随着级别增高,API使用的自由度降低,易用性增强。开发者可以根据需要选择合适的API,使用最通俗易懂的高级接口快速搭建算子逻辑,使用自由灵活的低级接口进行复杂的逻辑实现和性能调优。这样做的主要作用是:
-
降低复杂指令的使用难度
-
跨代兼容性保障
-
保留最大灵活度的可能
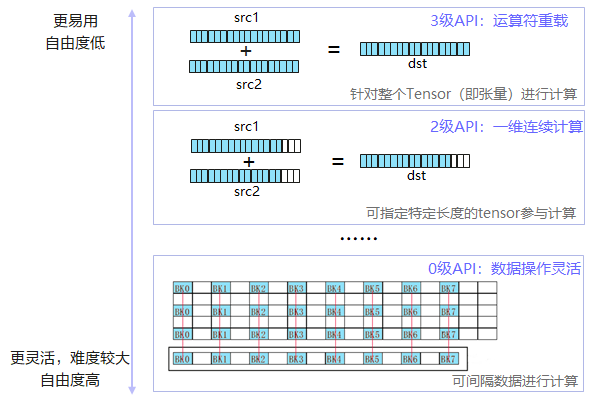

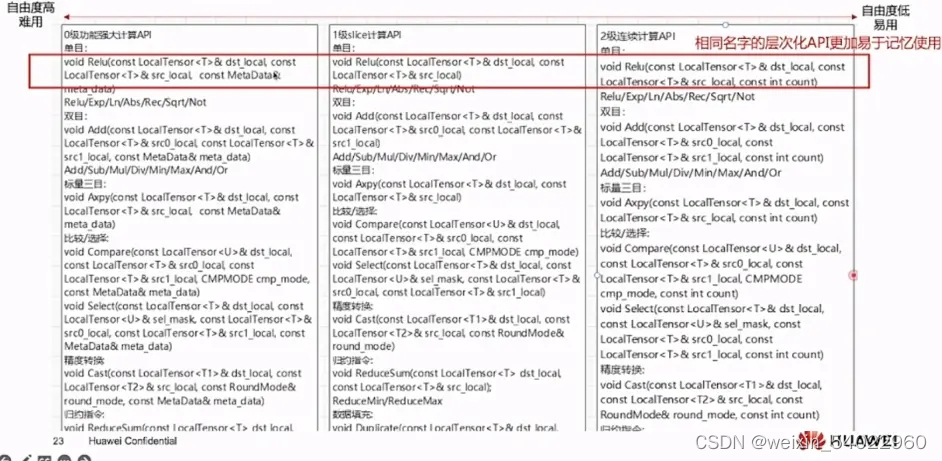
1、3级接口
运算符重载,支持+, -, *, /, |, &, <, >, <=, >=, ==, !=,实现1级指令的简化表达。允许用户使用形如:dst = src0 * src1,针对整个Tensor进行计算,以下指令API拥有3级接口:

2、2级接口
针对源操作数srcLocal的连续COUNT个数据进行计算,并连续写入目的操作数dstLocal,解决一维tensor的连续计算问题。


3、0级接口
0级功能灵活计算接口,是最底层的开发接口,可以完整发回硬件优势的计算API,可以进行非连续计算,该功能可以充分发回CANN系列芯片的强大功能指令,支持对每个操作数的Block stride,Repeat stride,MASK的操作,允许用户使用诸多的通用参数来定制化所需要的操作:

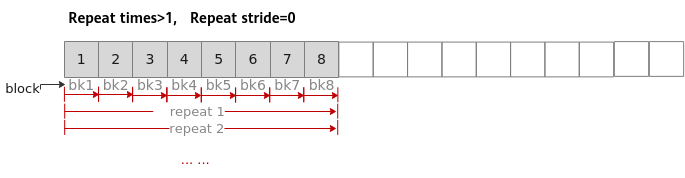
1、重复迭代次数-Repeat times
矢量计算单元,每次读取连续的8个block(每个block32 Bytes,共256 Bytes)数据进行计算,为完成对输入数据的处理,必须通过多次迭代(repeat)才能完成所有数据的读取与计算。Repeat times表示迭代的次数。
如下图所示,待处理数据大小为16个block(512Bytes),每次迭代处理8个block(256Bytes),需要两次迭代完成计算,Repeat times应设置为2。

2、相邻迭代间相同block的地址步长
当Repeat times大于1,需要多次迭代完成矢量计算时,您可以根据不同的使用场景合理设置相邻迭代间相同block的地址步长Repeat stride的值。
连续计算场景:假设定义一个Tensor供目的操作数和源操作数同时使用(即地址重叠),Repeat stride取值为8。此时,矢量计算单元第一次迭代读取连续8个block,第二轮迭代读取下一个连续的8个block,通过多次迭代即可完成所有输入数据的计算。

非连续计算场景:Repeat stride取值大于8(如取10)时,则相邻迭代间矢量计算单元读取的数据在地址上不连续,出现2个block的间隔。

反复计算场景:Repeat stride取值为0时,矢量计算单元会对首个连续的8个block进行反复读取和计算。
部分重复计算:Repeat stride取值大于0且小于8时,相邻迭代间部分数据会被矢量计算单元重复读取和计算,此种情形一般场景不涉及。
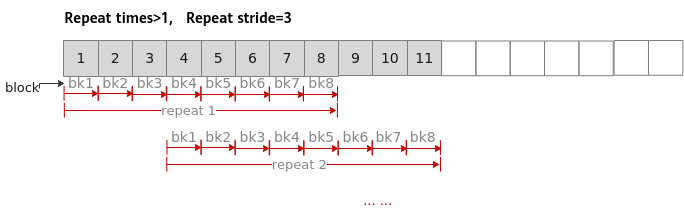
3、同一迭代内不同block的地址步长
如果需要控制单次迭代内,数据处理的步长,可以通过设置同一迭代内不同block的地址步长Block stride来实现。
-
连续计算,Block stride 设置为1,对同一迭代内的8个block数据连续进行处理。
-
非连续计算,Block stride值大于1(如取2),同一迭代内不同block之间在读取数据时出现一个block的间隔,如下图所示。
4、Mask参数
mask用于控制每次迭代内参与计算的元素。可通过连续模式和逐比特模式两种方式进行设置。
连续模式:表示前面连续的多少个元素参与计算。数据类型为uint64_t。取值范围和操作数的数据类型有关,数据类型不同,每次迭代内能够处理的元素个数最大值不同(当前数据类型单次迭代时能处理的元素个数最大值为:256 / sizeof(数据类型))。当操作数的数据类型占比特位16位时(如half,uint16_t),mask∈[1, 128];当操作数为32位时(如float, int32_t),mask∈[1, 64]。

逐bit模式:可以按位控制哪些元素参与计算,bit位的值为1表示参与计算,0表示不参与。参数类型为长度为2的uint64_t类型数组。参数取值范围和操作数的数据类型有关,数据类型不同,每次迭代内能够处理的元素个数最大值不同。当操作数为16位时,mask[0]、mask[1]∈[0, 264-1];当dst/src为32位时,mask[1]为0,mask[0]∈[0, 264-1]。
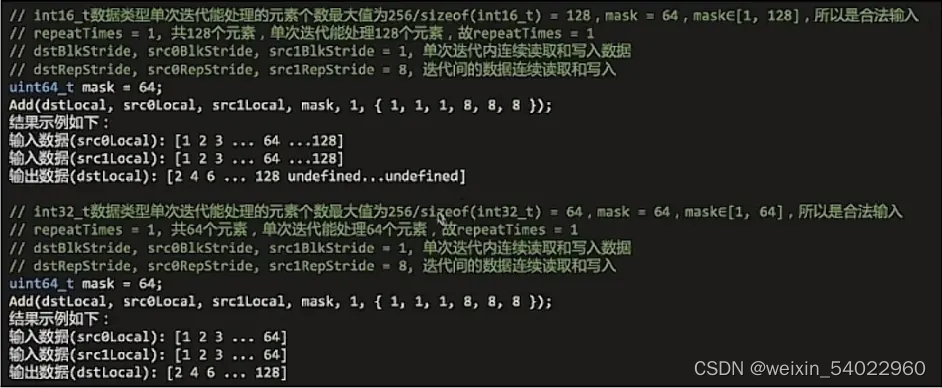
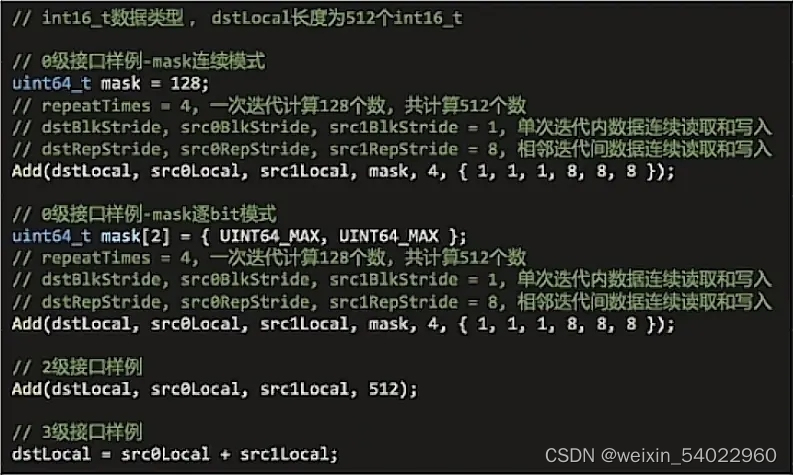
512个int16相加分别用0,2,3级接口实现对比,大家可以根据自己的实际需要选择对应的接口。
六、更多学习资源
好啦,本次分享结束啦,Ascend C的学习资源还有很多,想深入学习的可以参考官网教程:Ascend C官方教程。
号外!

华为将于2023年9月20-22日,在上海世博展览馆和上海世博中心举办第八届华为全联接大会(HUAWEICONNECT 2023)。本次大会以“加速行业智能化”为主题,邀请思想领袖、商业精英、技术专家、合作伙伴、开发者等业界同仁,从商业、产业、生态等方面探讨如何加速行业智能化。
我们诚邀您莅临现场,分享智能化的机遇和挑战,共商智能化的关键举措,体验智能化技术的创新和应用。您可以:
-
在100+场主题演讲、峰会、论坛中,碰撞加速行业智能化的观点
-
参观17000平米展区,近距离感受智能化技术在行业中的创新和应用
-
与技术专家面对面交流,了解最新的解决方案、开发工具并动手实践
-
与客户和伙伴共寻商机
感谢您一如既往的支持和信赖,我们热忱期待与您在上海见面。
大会官网:https://www.huawei.com/cn/events/huaweiconnect
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号