

如何使用io_uring构建快速响应的I/O密集型应用?
本文分享自华为云社区《如何使用io_uring构建快速响应的I/O密集型应用》,作者: Lion Long 。
当涉及构建快速响应的I/O密集型应用时,io_uring技术展现出了其卓越的潜力。本文摘要将深入探讨如何充分利用io_uring的特性来优化应用程序性能。通过异步I/O操作和高效事件处理,io_uring为开发人员提供了一种强大工具,能够显著减少I/O等待时间并实现更高的吞吐量。
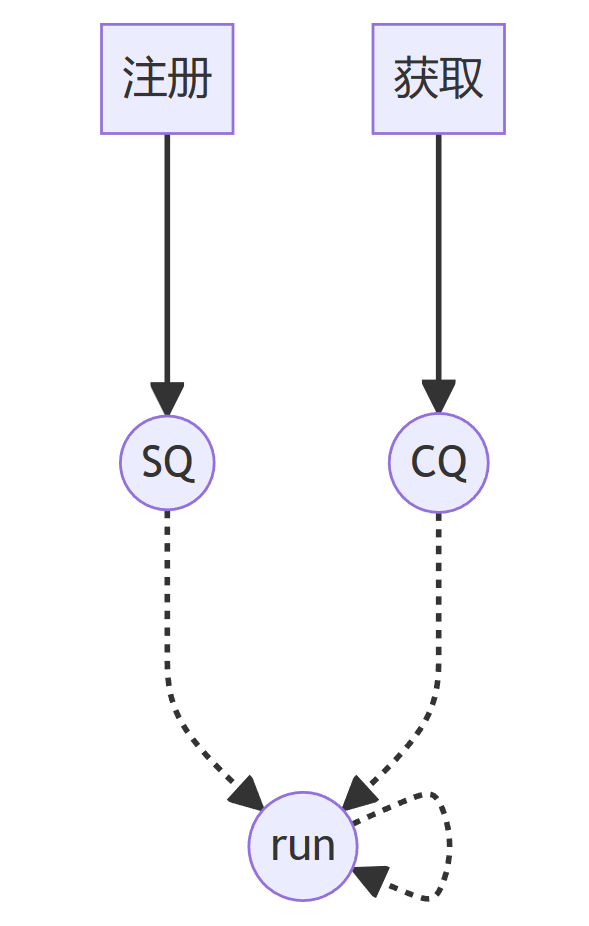
一、同步与异步
用于形容两者的关系,是同时存在的参考物。
同步: 所谓同步,就是发起一个请求时,在返回结果前,该调用不会返回。类似串行的概念。
异步: 异步的概念和同步相对,当发起一个请求时,该调用立刻返回,不等待结果,实际返回的结果由另外的线程 / 进程处理。类似并行的概念。
二、io_uring系统调用
io_uring从linix 5.1内核开始支持,但是到linix5.10后才达到比较好的支持,所以使用io_uring编程时,最好使用linix 5.10版本之后。升级linux内核可以参考ubuntu升级Linux内核版本_ubuntu 升级内核_Lion Long的博客-CSDN博客。
内核提供三个接口,函数原型:
#include <linux/io_uring.h> int io_uring_setup(u32 entries,struct io_uring_params *p); int io_uring_register(unsigned int fd,unsigned int opcode,void *arg,unsigned int nr_args); int io_uring_entry(unsigned int fd,unsigned int to_submit, unsigned int min_complete,unsigned int flags,sigset_t *sig);
2.1、io_uring_setup
函数原型:
#include <linux/io_uring.h> int io_uring_setup(u32 entries,struct io_uring_params *params);
系统调用,设置提交队列(SQ)和完成队列(CQ),其中至少包含entries条目,并返回一个文件描述符,可用于对io_urine实例执行后续操作。SQ和CQ在用户空间和内核之间共享,这减少了在启动和完成I/O时复制数据的消耗。
|
参数 |
含义 |
|
entries |
队列元素个数 |
|
params |
配置io_uring,向内核传递选项,内核使用params传递有关环形缓冲区的信息。 |
成功时返回新的文件描述符。然后,应用程序可以在随后的mmap系统调用中提供文件描述符,以映射提交队列(submission queues)和完成队列(completion queues),或者传给io_uring_register() / io_uring_enter()系统调用。
出现错误时,返回负错误代码。调用方不应依赖errno变量。
|
错误码 |
含义 |
|
EFAULT |
参数超出了您的可访问地址空间。 |
|
EINVAL |
resv数组包含非零数据,p.flags包含非零支持标志,条目超出界限。 |
|
EMFILE |
已达到每个进程打开文件描述符数量的限制。 |
|
ENFILE |
已达到系统范围内打开文件总数的限制。 |
|
ENOMEM |
可用的内核资源不足。 |
|
EPERM |
已指定IORING_SETUP_SQPOLL,但调用方的有效用户ID没有足够的权限。 |
2.2、io_uring_register
函数原型:
#include <linux/io_uring.h> int io_uring_register(unsigned int fd,unsigned int opcode,void *arg,unsigned int nr_args);
注册用于异步 I/O 的文件或用户缓冲区,使内核能长时间持有对该文件在内核内部的数据结构引用, 或创建应用内存的长期映射, 这个操作只会在注册时执行一次,而不是每个 I/O 请求都会处理,因此大大减少了每个IO的开销。
|
参数 |
含义 |
|
fd |
文件描述符 ,是io_uring_setup返回的fd |
|
opcode |
操作代码 |
成功时返回0。
出现错误时,返回负错误代码。调用方不应依赖errno变量。
2.3、io_uring_enter
#include <linux/io_uring.h> int io_uring_enter(unsigned int fd,unsigned int to_submit, unsigned int min_complete,unsigned int flags,sigset_t *sig);
这个系统调用使用共享的 SQ 和 CQ初始化和完成(initiate and complete)I/O。
单次调用同时执行:提交新的 I/O 请求;等待 I/O 完成。
参数:
- fd:io_uring_setup返回的文件描述符。
- to_submit:指定要从提交队列提交的I/O数。
成功返回使用的I/O数量。如果to_submit为零或提交队列为空,则该值可以为零。注意,如果创建环时指定了IORING_SETUP_SQPOLL,则返回值通常与to_submit相同,因为提交发生在系统调用的上下文之外。
与提交队列条目相关的错误将通过完成队列条目返回,而不是通过系统调用本身返回。
不代表提交队列条目发生的错误将通过系统调用直接返回。在出现这种错误时,返回负错误代码。调用方不应依赖errno变量。
更多信息可以执行 man io_uring_enter查看
2.4、执行流程
三、io_uring相关结构体
3.1、struct io_uring_params 结构体
struct io_uring_params { __u32 sq_entries; __u32 cq_entries; __u32 flags; __u32 sq_thread_cpu; __u32 sq_thread_idle; __u32 features; __u32 wq_fd; __u32 resv[3]; struct io_sqring_offsets sq_off; struct io_cqring_offsets cq_off; };
flags、sq_thread_cpu和sq_ thread_idle字段用于配置io_uring实例。flags是一个位掩码,其中0个或多个以下值一起或:
|
标志 |
含义 |
|
IORING_SETUP_IOPOLL |
执行繁忙等待I/O完成,而不是获取通过异步IRQ(中断请求)发送通知。 |
|
IORING_SETUP_SQPOLL |
创建一个内核线程来执行提交队列轮询 |
|
IORING_SETUP_SQ_AFF |
轮询线程将绑定到结构io_uring_params的sq_thread_cpu字段中设置的cpu。 |
|
IORING_SETUP_CQSIZE |
使用struct io_uring_params创建完成队列 |
|
IORING_SETUP_CLAMP |
如果指定了此标志,并且如果条目超过IORING_MAX_ENTERIES,则条目将被钳制在IORING_MAX_ENTERIES。如果设置了标志IORING _SETUP_SQPOLL,并且如果struct io_uring_params的值cq_entries超过IORING_MAX_ENTERIES,则它将被箝位在IORING_MAX_ENTERIES。 |
|
IORING_SETUP_ATTACH_WQ |
此标志应与struct io_uring_params一起设置 |
|
IORING_SETUP_R_DISABLED |
如果指定了该标志,io_uring环将以禁用状态启动。 |
3.2、struct io_cqring_offsets 结构体
struct io_cqring_offsets { __u32 head; __u32 tail; __u32 ring_mask; __u32 ring_entries; __u32 overflow; __u32 cqes; __u32 flags; __u32 resv[3]; };
3.3、struct io_uring_sqe 结构体
struct io_uring_sqe { __u8 opcode; /* type of operation for this sqe */ __u8 flags; /* IOSQE_ flags */ __u16 ioprio; /* ioprio for the request */ __s32 fd; /* file descriptor to do IO on */ union { __u64 off; /* offset into file */ __u64 addr2; }; union { __u64 addr; /* pointer to buffer or iovecs */ __u64 splice_off_in; } __u32 len; /* buffer size or number of iovecs */ union { __kernel_rwf_t rw_flags; __u32 fsync_flags; __u16 poll_events; /* compatibility */ __u32 poll32_events; /* word-reversed for BE */ __u32 sync_range_flags; __u32 msg_flags; __u32 timeout_flags; __u32 accept_flags; __u32 cancel_flags; __u32 open_flags; __u32 statx_flags; __u32 fadvise_advice; __u32 splice_flags; __u32 rename_flags; __u32 unlink_flags; __u32 hardlink_flags; }; __u64 user_data; /* data to be passed back at completion time */ union { struct { /* index into fixed buffers, if used */ union { /* index into fixed buffers, if used */ __u16 buf_index; /* for grouped buffer selection */ __u16 buf_group; } /* personality to use, if used */ __u16 personality; union { __s32 splice_fd_in; __u32 file_index; }; }; __u64 __pad2[3]; }; };
3.4、struct io_uring_cqe 结构体
struct io_uring_cqe { __u64 user_data; /* sqe->data submission passed back */ __s32 res; /* result code for this event */ __u32 flags; };
四、liburing库安装
(1)下载源码。
git clone https://github.com/axboe/liburing.git
(2)进入liburing。
cd liburing
(3)配置。
./configure
(4)编译和安装。
make && sudo make install
(5)编译应用程序,一定要指定库 -luring -D_GUN_SOURCE。
gcc -o io_uring_test io_uring_test.c -luring -D_GUN_SOURCE
五、liburing提供的接口
5.1、io_uring_queue_init_params
函数原型:
#include <liburing.h> int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags); int io_uring_queue_init_params(unsigned entries, struct io_uring *ring, struct io_uring_params *params);
io_uring_queue_init()函数执行io_uring_setup()系统调用来初始化内核中的提交队列和完成队列,其中至少包含提交队列中的条目,然后将生成的文件描述符映射到应用程序和内核之间共享的内存中。
默认情况下,CQ环的条目数将是SQ环条目指定的条目数的两倍。这对于常规文件或存储工作负载足够,但对于网络工作负载可能太小。SQ环条目并没有限制环可以支持的进程中请求的数量,它只是限制了一次(批)提交给内核的数量。如果CQ环溢出,例如,在应用程序可以获取它们之前,生成的条目比环中的条目多,则环进入CQ环溢流状态。这通过在SQ环标志中设置IORING_SQ_CQ_OVERFLOW来指示。除非内核耗尽可用内存,否则不会删除条目,但这是一条慢得多的完成路径,会减慢请求处理速度。因此,应该避免这种情况,并且CQ环的大小适合于工作负载。在struct io_uring_params中设置cq_entries将告诉内核为cq环分配这么多条目,与给定条目中的SQ环大小无关。如果该值不是2的幂,则将四舍五入到最接近的2的幂。
成功时,io_uring_queue_init返回0,ring将指向包含io_RUING队列的共享内存。失败时返回-errno。flags将传递给io_uring_setup系统调用。
如果使用io_uring_queue_init_params(),则params指示的参数将直接传递到io_uring_setup系统调用。成功后返回0,应通过对io_uring_queue_exit的相应调用释放ring持有的资源。失败时返回-errno。
5.2、io_uring_get_sqe
函数原型:
#include <liburing.h> struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring);
- 从属于ring参数的提交队列中获取下一个可用的提交队列条目。
- 成功时返回一个指向提交队列条目的指针。
- 失败时返回NULL。
如果返回了提交队列条目,则应通过io_uring_prep_read()等准备函数之一填写该条目,并通过io_ uring_submit()提交。
如果返回NULL,则SQ环当前已满,必须提交条目进行处理,然后才能分配新条目。
5.3、io_uring_prep_accept
函数原型:
#include <sys/socket.h> #include <liburing.h> void io_uring_prep_accept(struct io_uring_sqe *sqe, int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags); void io_uring_prep_accept_direct(struct io_uring_sqe *sqe, int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags, unsigned int file_index); void io_uring_prep_multishot_accept(struct io_uring_sqe *sqe, int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags); void io_uring_prep_multishot_accept_direct(struct io_uring_sqe *sqe, int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags);
这些函数准备一个异步accept()请求。
io_uring_prep_accept()函数准备接受请求。提交队列条目sqe被设置为使用文件描述符sockfd开始接受由addr处的套接字地址和结构长度addrlen描述的连接请求,并在标志中使用修饰符标志。
注意:io_uring_prep_accept()与在结构中传递数据的任何请求一样,在成功提交请求之前,该数据必须保持有效。它不需要在完成之前保持有效。一旦请求被提交,内核状态就稳定了。
5.4、io_uring_prep_recv
函数原型:
#include <liburing.h> void io_uring_prep_recv(struct io_uring_sqe *sqe, int sockfd, void *buf, size_t len, int flags); void io_uring_prep_recv_multishot(struct io_uring_sqe *sqe, int sockfd, void *buf, size_t len, int flags);
描述:
io_uring_prep_recv()函数准备recv请求。提交队列条目sqe被设置为使用文件描述符sockfd来开始将数据接收到大小为size且具有修改标志flags的缓冲区目的地buf中。
此函数用于准备异步recv()请求。
multishot版本允许应用程序发出单个接收请求,当数据可用时,该请求会重复发布CQI。
5.5、io_uring_prep_send
函数原型:
#include <liburing.h> void io_uring_prep_send(struct io_uring_sqe *sqe, int sockfd, const void *buf, size_t len, int flags);
描述:
io_uring_prep_send()函数准备发送请求。提交队列条目sqe被设置为使用文件描述符sockfd开始从buf发送大小为size的数据,并带有修改标志flags。
此函数用于准备异步send()请求。
5.6、io_uring_submit (重要)
函数原型:
#include <liburing.h> int io_uring_submit(struct io_uring *ring);
描述:
- 将下一个事件提交到属于ring的提交队列。
- 调用者使用io_uring_get_sqe()检索提交队列条目(SQE)并使用提供的帮助程序之一准备SQE后,可以使用io_ uring_ submit()提交。
返回值:
- 成功时返回提交的提交队列条目数。
- 失败时返回-errno。
5.7、io_uring_submit_and_wait (重要)
函数原型:
#include <liburing.h> int io_uring_submit_and_wait(struct io_uring *ring,unsigned wait_nr);
描述:
- 将下一个事件提交到属于环的提交队列,并等待wait_nr完成事件。
- 在调用方使用io_uring_get_sqe()检索提交队列条目(SQE)并准备SQE之后,可以使用io_ uring_ submit_and_wait()提交它。
返回值:
- 成功时返回提交的提交队列条目数。
- 失败时返回-errno。
5.8、io_uring_wait_cqe
函数原型:
#include <liburing.h> int io_uring_wait_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr);
描述:
- 等待来自属于环参数的队列的io完成,必要时等待。如果调用时环中已有事件可用,则不会发生等待。成功时填写cqe_ptr参数。
- 在呼叫者提交了具有io_uring_submit()的请求之后,应用程序可以使用io_uring_wait_cqe检索完成。
返回值:
- 成功时返回0,并填写cqe_ptr参数。失败时返回-errno。返回值指示等待CQE的结果,并且与CQE结果本身无关。
5.9、io_uring_peek_batch_cqe
#include <liburing.h> int io_uring_peek_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr); int io_uring_peek_batch_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr, int count);
描述:
- io_uring_peek_cqe()函数从属于ring参数的队列返回IO完成(如果有)。成功返回后,cqe_ptr参数将填充有效的cqe条目。
- 此函数不进入内核等待事件,只有在CQ环中已经可用时才返回事件。
- io_uring_peek_batch_cqe是对io_uring_peek_cqe的封装,表示一次最多从ring参数获取count个IO完成。
返回值:
- 成功时io_uring_peek_cqe()返回0,并填写cqe_ptr参数。
- 失败时返回-EAGAIN。
- 成功时io_uring_peek_cqe()返回IO完成数量,并填写cqe_ptr参数。
- 失败时返回-EAGAIN。
5.10、io_uring_cq_advance
#include <liburing.h> void io_uring_cq_advance(struct io_uring *ring, unsigned nr);
描述:
io_uring_cq_advance()函数将属于ring参数的nr个io完成标记为消耗。
在呼叫者已经使用io_uring_submit()提交请求之后,应用程序可以使用io_ uring_ wait_cqe()、io_uring_peek_cqe()或任何其他cqe检索帮助器检索完成,并使用io_uring_cqe_seen()将其标记为。
函数io_uring_cqe_seen()调用io_ uring_cq_advance()函数。
完成必须标记为可见,以便可以重用它们的插槽。否则将导致在下一次调用时返回相同的完成。
5.11、更多接口
除了bind没有异步接口,其他基本都有。比如io_uring_prep_connect()、io_uring_prep_close()等等。
六、基于liburing的TCP服务器实现
在应用层使用io_uring,主要使用liburing库,它提供丰富的用户接口,底层调用的是三个内核io_uring系统调用。
基于liburing的TCP服务器实现示例代码:
#include <stdio.h> #include <unistd.h> #include <sys/socket.h> #include <netinet/in.h> #include <string.h> #include <liburing.h> #define ENTRIES_LENGTH 4096 #define RING_CQE_NUMBER 10 #define BUFFER_SIZE 1024 struct conninfo { int connfd; int type; }; enum { READ, WRITE, ACCPT, }; void set_accept_event(struct io_uring *ring,int fd, struct sockaddr* clientaddr, socklen_t *len,unsigned flags) { struct io_uring_sqe *sqe = io_uring_get_sqe(ring);//·µ»Ø¶ÓÁÐÊ×µØÖ· io_uring_prep_accept(sqe, fd, clientaddr, len, flags); struct conninfo ci = { .connfd = fd, .type = ACCPT }; memcpy(&sqe->user_data, &ci, sizeof(struct conninfo)); } void set_read_event(struct io_uring *ring, int fd, void *buf, size_t len, int flags) { struct io_uring_sqe *sqe = io_uring_get_sqe(ring);//·µ»Ø¶ÓÁÐÊ×µØÖ· io_uring_prep_recv(sqe, fd, buf, len, flags); struct conninfo ci = { .connfd = fd, .type = READ }; memcpy(&sqe->user_data, &ci, sizeof(struct conninfo)); } void set_write_event(struct io_uring *ring, int fd, void *buf, size_t len, int flags) { struct io_uring_sqe *sqe = io_uring_get_sqe(ring);//·µ»Ø¶ÓÁÐÊ×µØÖ· io_uring_prep_send(sqe, fd, buf, len, flags); struct conninfo ci = { .connfd = fd, .type = WRITE }; memcpy(&sqe->user_data, &ci, sizeof(struct conninfo)); } int main() { int listenfd = socket(AF_INET, SOCK_STREAM, 0); if (listenfd == -1) return -1; struct sockaddr_in serveraddr,clientaddr; serveraddr.sin_family = AF_INET; serveraddr.sin_addr.s_addr = htonl(INADDR_ANY); serveraddr.sin_port = htons(9999); if (-1 == bind(listenfd, (struct sockaddr*)&serveraddr, sizeof(serveraddr))) return -2; listen(listenfd, 10); struct io_uring_params params; memset(¶ms,0,sizeof(params)); struct io_uring ring; io_uring_queue_init_params(ENTRIES_LENGTH,&ring,¶ms); socklen_t clientlen = sizeof(clientaddr); set_accept_event(&ring, listenfd, (struct sockaddr*)&clientaddr,&clientlen, 0); char buffer[BUFFER_SIZE] = { 0 }; while (1) { struct io_uring_cqe *cqe; io_uring_submit(&ring); int ret = io_uring_wait_cqe(&ring,&cqe); struct io_uring_cqe *cqes[RING_CQE_NUMBER]; int cqecount=io_uring_peek_batch_cqe(&ring, cqes, RING_CQE_NUMBER); int i = 0; unsigned count =0; for (i = 0; i < cqecount; i++) { count++; cqe = cqes[i]; struct conninfo ci; memcpy(&ci, &cqe->user_data, sizeof(struct conninfo)); if (ci.type == ACCPT) { int connfd = cqe->res; set_read_event(&ring, connfd, buffer, BUFFER_SIZE, 0); set_accept_event(&ring, listenfd, (struct sockaddr*)&clientaddr,&clientlen, 0); } else if (ci.type == READ) { int bufsize = cqe->res; if(bufsize==0) { close(ci.connfd); } else if(bufsize<0) { } else{ //set_read_event(&ring, ci.connfd, buffer, 1024, 0); printf("buff: %s\n",buffer); set_write_event(&ring, ci.connfd, buffer, bufsize, 0); } } else if(ci.type == WRITE) { set_read_event(&ring, ci.connfd, buffer, BUFFER_SIZE, 0); } } io_uring_cq_advance(&ring,count); } return 0; }
总结
- io_uring主要由三部分构成:内核提供的三个系统调用接口(io_uring_setup、io_uring_register、io_uring_enter),内核实现的系统调用,应用层提供的liburing库。
- io_uring_submite会在底层协议栈执行accept、recv、send等功能。从fio测试磁盘IO的测试结果来看,io_uring的IOPS与libaio相同,是psync的两倍。
- io_uring的异步操作在内核下完成,用户态调用api是感觉不到异步操作的。
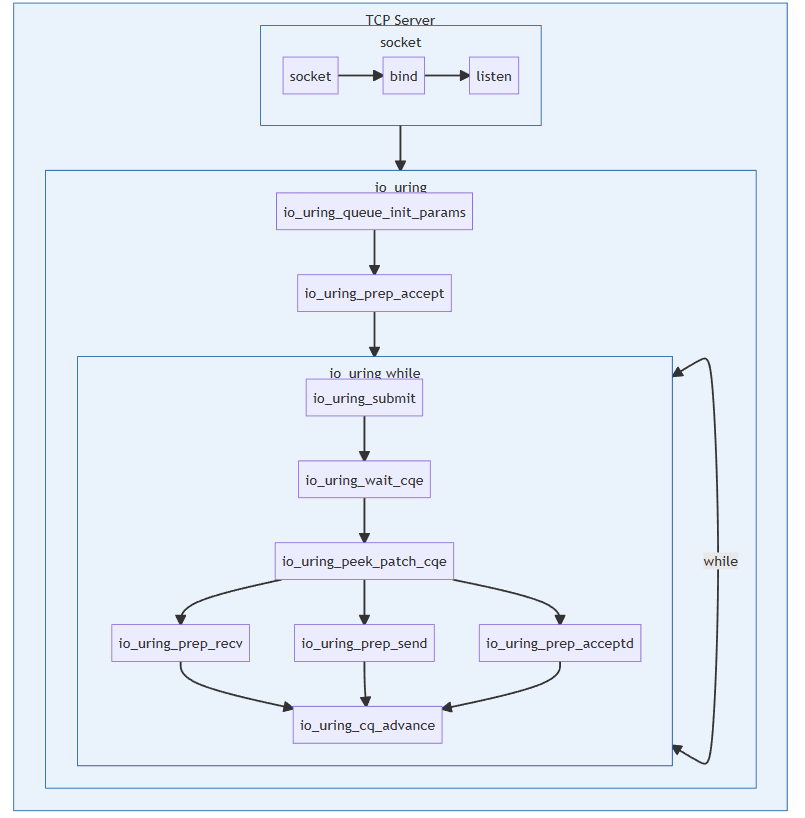
- io_uring实现TCP服务器的函数调用框图:
号外!

华为将于2023年9月20-22日,在上海世博展览馆和上海世博中心举办第八届华为全联接大会(HUAWEICONNECT 2023)。本次大会以“加速行业智能化”为主题,邀请思想领袖、商业精英、技术专家、合作伙伴、开发者等业界同仁,从商业、产业、生态等方面探讨如何加速行业智能化。
我们诚邀您莅临现场,分享智能化的机遇和挑战,共商智能化的关键举措,体验智能化技术的创新和应用。您可以:
- 在100+场主题演讲、峰会、论坛中,碰撞加速行业智能化的观点
- 参观17000平米展区,近距离感受智能化技术在行业中的创新和应用
- 与技术专家面对面交流,了解最新的解决方案、开发工具并动手实践
- 与客户和伙伴共寻商机
感谢您一如既往的支持和信赖,我们热忱期待与您在上海见面。
大会官网:https://www.huawei.com/cn/events/huaweiconnect
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。

