教你1分钟搞定2小时字幕
摘要:本文将介绍如何使用录音文件识别极速版给无字幕视频自动生成字幕。
本文分享自华为云社区《利用录音文件极速版为视频生成字幕》,作者:戈兀。
引言
越来越多的人们使用抖音、B站等视频app,记录、分享日常生活,随之互联网上产生了大量的长、短视频。字幕是影响视频观看体验的重要因素。以日常分享为主的视频创作者往往没有时间为视频制作字幕,在创作者发音不清楚的前提下,没有字幕的视频可能会让观众困惑甚至产生理解偏差。而带字幕的视频让观众有更好的观看体验,“一气呵成”顺畅地看完。
语音识别技术(Automatic Speech Recognition)是一种将人的语音转换为文本的技术。随着深度学习的发展,端到端语音识别技术也取得了巨大的突破。将原始的音频数据,经过分帧、加窗、FFT等操作后,得到描述音频在时、频域信息的梅尔特征或是Fbank特征。将特征送入transformer等神经网络,输出对应的文本信息。此外,由大量文本训练的语言模型(language model)能够纠正语音识别输出文本不通顺的问题,改善阅读体验。而热词技术也被用来解决语音识别的领域适配问题,如同音不同字。
本文将介绍如何使用录音文件识别极速版给无字幕视频自动生成字幕。
录音文件识别极速版采用同步接口,利用GPU加速模型的推理过程。对于两个小时内的音、视频文件,可以在1分钟内返回识别结果,满足准实时字幕、音频质检等对识别速度有要求的场景。感兴趣的读者可以点击录音文件识别极速版文档,了解详情。
注:本文同步发布至华为云AI Gallery Notebook,可以在AI Gallery上运行:利用录音文件极速版为视频生成字幕
原理讲解
给无字幕视频生成字幕,就是从视频中的提取音频流,将音频流送入录音文件识别极速版,得到识别文字,和对应的时间戳信息。然后将其转换为视频字幕文件格式,如srt文件。得到srt字幕文件后,在播放视频时,载入字幕文件,就可以看到字幕了。
因此,整个流程如下:
1、利用ffmpeg工具,从视频中提取音频流
2、设置适合的参数,使用录音文件识别极速版,催音频文件进行识别
3、对识别结果,包括文字和时间戳信息,进行处理,得到视频字幕文件
4、将命名相同的视频文件与 srt 文件放在同一目录下,用播放器打开,即可得到有字幕的视频。或者利用ffmpeg,以硬字幕的形式,将字幕嵌入到视频中。
注:SRT(SubRip 文件格式)是以 SubRip 文件格式保存的简单字幕文件,扩展名为 .srt。每个字幕在 SRT 文件中有四个部分:
- 指示字幕编号或位置的数字计数器;
- 字幕的开始和结束时间;
- 一行或多行的字幕文本;
- 表示字幕结束的空行。
代码开发
步骤一:提取音频流
采用ffmpeg从视频文件中提取音频流,并保存为音频文件output.wav
ffmpeg -i input.mp4 -ar 16000 -ac 1 output.wav
-ar指定保存音频文件的采样率,这里16000表示1秒钟,保存16000个采样点数据;-ac指定保存音频的通道数,这里1表示保存为单通道音频。
步骤二:安装语音识别python SDK
在安装python3后,用pip安装其他依赖依赖包
pip install setuptools
pip install requests
pip install websocket-client
下载最新版python sdk源码:https://sis-sdk-repository.obs.cn-north-1.myhuaweicloud.com/python/huaweicloud-python-sdk-sis-1.8.1.zip
进入下载的Python SDK目录,在setup.py所在层目录执行 python setup.py install 命令,完成SDK安装。
步骤三:调用录音文件极速版
- 导入依赖包
from huaweicloud_sis.client.flash_lasr_client import FlashLasrClient from huaweicloud_sis.bean.flash_lasr_request import FlashLasrRequest from huaweicloud_sis.exception.exceptions import ClientException from huaweicloud_sis.exception.exceptions import ServerException from huaweicloud_sis.bean.sis_config import SisConfig import json
- 初始化客户端
config = SisConfig() config.set_connect_timeout(50) config.set_read_timeout(50) client = FlashLasrClient(ak=ak, sk=sk, region=region, project_id=project_id, sis_config=config)
- 构造请求
asr_request = FlashLasrRequest() asr_request.set_obs_bucket_name(obs_bucket_name) # 设置存放音频的桶名,必选 asr_request.set_obs_object_key(obs_object_key) # 设置OBS桶中的对象的键值,必选 asr_request.set_audio_format(audio_format) # 音频格式,必选 asr_request.set_property(property) # property,比如:chinese_16k_conversation asr_request.set_add_punc('yes') asr_request.set_digit_norm('no') asr_request.set_need_word_info('yes') asr_request.set_first_channel_only('yes')
为视频产生字幕文件时,不仅需要文字,也需要文字对应的时间戳信息。当一句话过长,屏幕无法完整显示时,就需要对这句话进行切分。因此,仅仅根据每个句子的起始和截止时间,无法准确的确定切分后两句话的起始和截止时间。因此我们需要字级别的时间信息。而将need_word_info配置为‘yes’,就可以输出字级别的时间戳信息。如下:
"word_info": [ { "start_time": 590, "word": "哎", "end_time": 630 }, { "start_time": 830, "word": "大", "end_time": 870 }, { "start_time": 950, "word": "家", "end_time": 990 }, { "start_time": 1110, "word": "好", "end_time": 1150 }, ]
- 接下里发送识别请求
result = client.get_flash_lasr_result(asr_request)
- 拿到带有详细时间戳信息的识别结果result:
"result": { "score": 0.9358551502227783, "word_info": [ { "start_time": 590, "word": "哎", "end_time": 630 }, { "start_time": 830, "word": "大", "end_time": 870 }, { "start_time": 950, "word": "家", "end_time": 990 }, { "start_time": 1110, "word": "好", "end_time": 1150 }, { "start_time": 1750, "word": "我", "end_time": 1790 }, { "start_time": 1910, "word": "是", "end_time": 1950 }, { "start_time": 2070, "word": "你", "end_time": 2110 }, { "start_time": 2190, "word": "们", "end_time": 2230 }, { "start_time": 2350, "word": "的", "end_time": 2390 }, { "start_time": 2870, "word": "音", "end_time": 2910 }, { "start_time": 3030, "word": "乐", "end_time": 3070 }, { "start_time": 3190, "word": "老", "end_time": 3230 }, { "start_time": 3350, "word": "师", "end_time": 3390 }, { "start_time": 3590, "word": "康", "end_time": 3630 }, { "start_time": 3750, "word": "老", "end_time": 3790 }, { "start_time": 3950, "word": "师", "end_time": 3990 }, { "start_time": 4830, "word": "那", "end_time": 4870 }, { "start_time": 4990, "word": "么", "end_time": 5030 }, { "start_time": 5350, "word": "这", "end_time": 5390 }, { "start_time": 5550, "word": "几", "end_time": 5590 }, { "start_time": 5750, "word": "系", "end_time": 5790 }, { "start_time": 5870, "word": "列", "end_time": 5910 }, { "start_time": 6070, "word": "呢", "end_time": 6110 }, { "start_time": 6310, "word": "我", "end_time": 6350 }, { "start_time": 6390, "word": "们", "end_time": 6470 }, { "start_time": 6510, "word": "来", "end_time": 6550 }, { "start_time": 6670, "word": "到", "end_time": 6710 }, { "start_time": 6830, "word": "了", "end_time": 6870 }, { "start_time": 7430, "word": "发", "end_time": 7470 }, { "start_time": 7630, "word": "声", "end_time": 7670 }, { "start_time": 7830, "word": "练", "end_time": 7870 }, { "start_time": 8030, "word": "习", "end_time": 8070 }, { "start_time": 8950, "word": "三", "end_time": 8990 }, { "start_time": 9190, "word": "十", "end_time": 9230 }, { "start_time": 9350, "word": "五", "end_time": 9390 }, { "start_time": 9470, "word": "讲", "end_time": 9510 } ], "text": "哎,大家好,我是你们的音乐老师康老师。那么这几系列呢,我们来到了发声练习三十五讲。" }, "start_time": 510, "end_time": 9640 }
步骤四:将识别结果转为srt字幕格式文件
由于视频播放界面的宽度有限,当一句话包含的文字数过多时,会存在一行放不下的问题。因此我们在生成srt文件时,需要将文字数量过长的一句话切分为两句话,分别在不同的时间段显示。企切分后的第一句话的起始时间不变,截止时间为最后一个字的截止时间;第二句话的起始时间为第一个字的起始时间,截止时间不变。这样就保证切分后两句话的时间戳也是正确的,进而在合适的视频帧中显示正确的文本内容。
def json2srt(json_result): results = "" count = 1 max_word_in_line = 15 min_word_in_line = 3 punc = ["。", "?", "!", ","] segments = json_result['flash_result'][0]['sentences'] for i in range(len(segments)): current_result = segments[i] current_sentence = current_result["result"]["text"] if len(current_result["result"]["word_info"]) > max_word_in_line: srt_result = "" srt_result_len = 0 current_segment = "" cnt = 0 start = True for i in range(len(current_sentence)): if current_sentence[i] not in punc: if start: start_time = current_result["result"]["word_info"][cnt]['start_time'] start = False else: end_time = current_result["result"]["word_info"][cnt]['end_time'] current_segment += current_sentence[i] srt_result_len += 1 cnt += 1 else: if srt_result_len < min_word_in_line: srt_result += current_segment + current_sentence[i] current_segment = "" else: srt_result += current_segment + current_sentence[i] current_segment = "" start_time = time_format(start_time) end_time = time_format(end_time) if srt_result[-1] == ",": srt_result = srt_result[:-1] results += str(count) + "\n" + start_time + "-->" + end_time + "\n" + srt_result + "\n" + "\n" count += 1 start = True srt_result = "" else: start_time = time_format(current_result["start_time"]) end_time = time_format(current_result["end_time"]) if current_sentence[-1] == ",": current_sentence = current_sentence[:-1] results += str(count) + "\n" + start_time + "-->" + end_time + "\n" + current_sentence + "\n" + "\n" count += 1 return results
得到srt格式的字幕文件
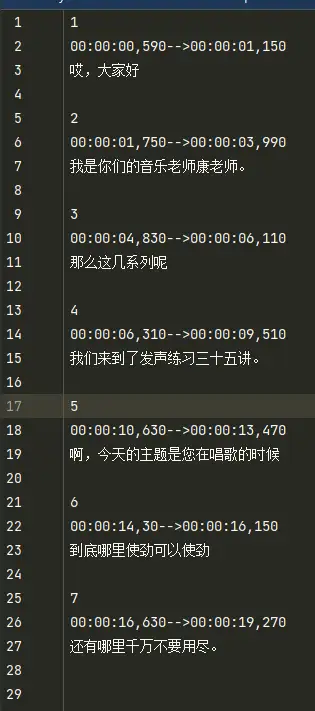
步骤五:播放视频,载入字幕
修改文件名,保证srt文件和原始视频文件命名相同,然后用播放器播放视频:
步骤六:使用ffmpeg给视频添加硬字幕(可选)
ffmpeg -i input.mp4 -vf subtitles=subtitle.srt output_srt.mp4
注: 硬字幕是将字幕渲染到视频的纹理上,然后将其编码成独立于视频格式的一个完整视频。硬字幕与视频是一个整体,不能更改或删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号