

详解集群级备份恢复:物理细粒度备份恢复
摘要:在实际使用过程中,数据库集群级的故障并非高概率事件,如何安全高效地帮助客户备份恢复一部分数据库元素,才是更加实际的需求,这也是细粒度备份恢复的意义所在。
本文分享自华为云社区《GaussDB(DWS)之物理细粒度备份恢复》,作者:我的橘子呢 。
1. 认识物理细粒度备份恢复
相对于集群级备份恢复海量的文件备份恢复操作,物理细粒度备份能够从更小的粒度、以更少的数据文件操作,对单库、单表进行备份与恢复。在实际使用过程中,数据库集群级的故障并非高概率事件,如何安全高效地帮助客户备份恢复一部分数据库元素,如schema或部分表,才是更加实际的需求,这也是细粒度备份恢复的意义所在。
物理细粒度备份以小粒度如database级、schema级、表级等为单位,对数据库文件进行物理备份,由于相对于集群级粒度更小,因此也更加高效实用。目前Roach工具支持的物理细粒度备份恢复功能主要包括:schema级全量备份、schema级增量备份、从细粒度备份集恢复单表/多表、从集群级备份集(带细粒度参数)恢复单表或多表。这些功能基本上满足了实际使用过程中对细粒度备份恢复的要求。物理细粒度备份恢复功能图如图1所示。
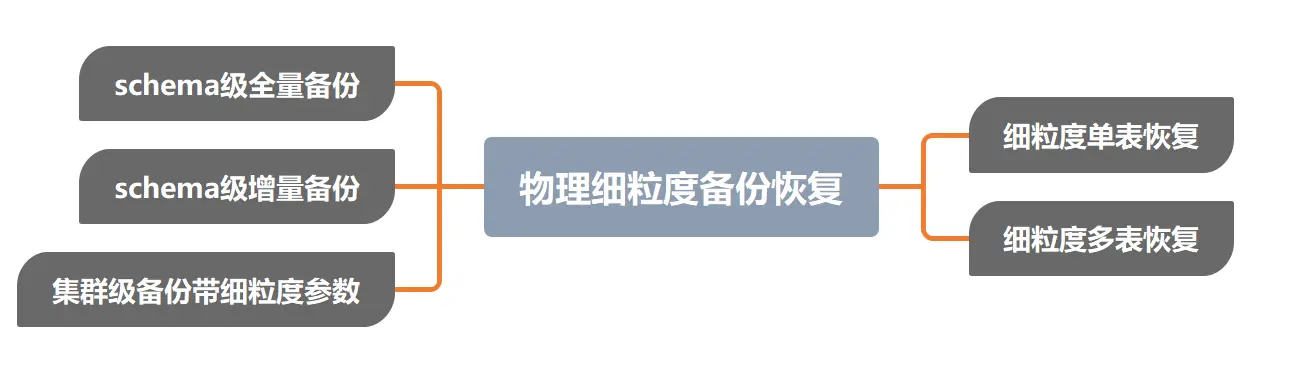
图1 细粒度备份恢复功能示意图
2. 了解物理细粒度备份
物理细粒度的备份能力是从Roach的基线版本继承而来的,大部分沿用了集群级备份的设计思路,即基本的备份流程是备份行存文件,创建一致性点,备份xlog、clog等文件,最后备份列存文件。物理细粒度备份在此基础上需要进一步考虑以下几个问题。
2.1 备份的数据内容
给定对应粒度备份任务如一张表,如何在备份最少数据的情况下保证恢复该表时数据的完整性?考虑该问题需要同时从备份数据小和数据完整性两个方面考虑。备份数据量最小最理想的情况是只备份数据库中该表以及相关表对应的物理文件,同时不考虑数据的拷贝文件,也就是只备份节点中主DN对应的数据文件。然而从数据的完整性角度来说,只备份表对应的物理文件是不够的,为了保证恢复阶段能恢复到一致性点,需要依赖xlog、clog等日志文件,而这些文件不能以更小的粒度划分,因此需要全部备份。图2列出了细粒度备份在保证数据完整性的情况下所必须备份的文件示意图。
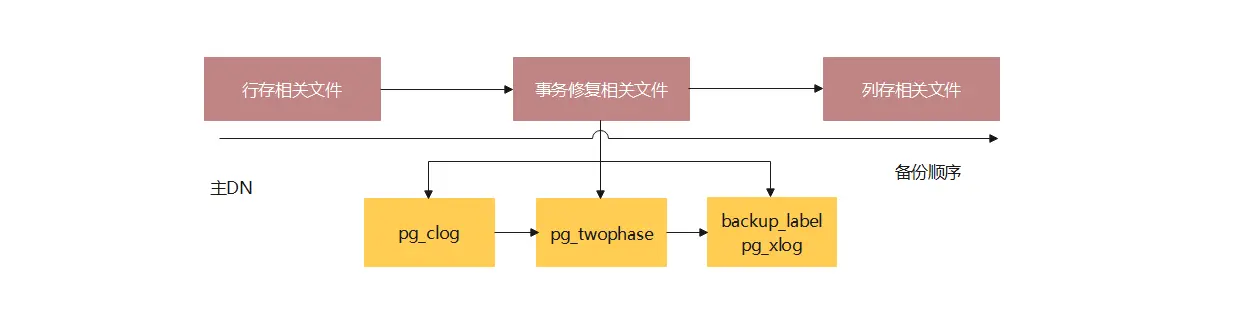
图2 物理细粒度备份数据内容示意图
2.2 备份集的存储结构
现阶段集群级备份时会将数据文件和配置文件等压缩进同一个备份的rch文件中,在恢复单表时需要一起获取回来并过滤,逻辑较为混乱。因此,为了恢复时能够更精确地获取文件,细粒度备份对数据备份结构进行了进一步改造,将不同类型的文件存储在不同的rch文件中,以更小的粒度对存储结构进行了划分。如图3所示,行列存相关的文件存储在data目录下,以database为单位进行了划分,每个database目录下存在row目录和col目录,分别对应存储行存文件和列存文件。archive文件夹保存xlog相关文件,xact文件存储clog相关文件,gloabal文件夹保存数据目录下其他文件。
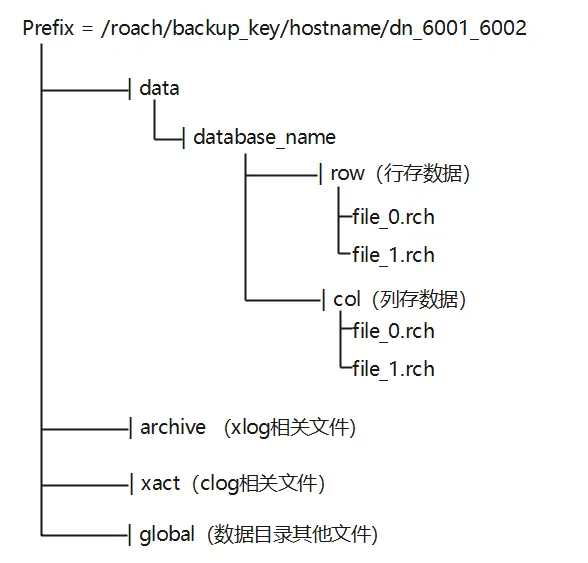
图3 物理细粒度备份存储结构示意图
2.3 备份数据相关文件的组织形式
考虑这样一个问题,当备份一张表时,除了备份这张表本身对应的数据文件,我们还应该备份与这张表关联的一些辅助表,比如列存表的cudesc表、存在变长字段对应的toast表等,只有这样才能保证恢复后这张表的可用性,那么备份的时候怎么知道该表存在哪些关联表呢?细粒度备份采用Map文件对表关系进行组织,对表所有的关联表及文件进行统一收集记录。该信息对于细粒度备份恢复至关重要,主要有以下两个方面的作用:
(1)备份时:得到一张表的Map信息,在备份行列存文件时,按照Map中记录的信息,将表需要备份的相关文件加入到需要备份的file_list中,后续备份时就可以按照该file_list进行文件的备份,省去了文件的扫描动作。
(2)恢复时:恢复时根据Map信息,得到目标表相关的文件记录,就可以对应获取所需的数据文件,并根据表的元信息建立恢复时的路径映射关系。
Map文件的生成是在备份行存文件之前,各节点以主DN个数为单位,并行获取Map信息,分别生成自己的Map文件。Map信息的获取,需要从多个level进行:
Agent –> Instance –> Database –> Schema –>Table –> RelatedRelations
在得到各表对应的Map信息后,会按照一定的格式框架组织多层的json格式,并将对应的json信息以schema为单位写入到schemaname.map中,最终持久化存储到介质下元数据目录对应的节点级根路径中:
/roach/backup_key/map/dn_6001_6002/databasename/schemaname.map
Map文件对应的json存储内容如图4所示。

图4 Map文件Json格式
2.4 备份压缩文件与数据文件的映射关系
考虑细粒度恢复一张表时,如何在备份集大量的rch压缩文件中挑选出我们想要的表在哪些rch文件里。细粒度备份恢复在备份过程中会生成额外的fine_file_list信息,每张rch文件都有一个fine_file_list文件与之相对应。该fine_file_list文件记录了对应rch文件中保存了哪些表,在恢复时就可以根据fine_file_list找到待恢复表涉及哪些rch文件,精准获取必要的rch文件,这样就可以大幅提升细粒度恢复的性能。
只有行列存数据的rch文件存在对应的fine_file_list文件。fine_file_list保存在节点元信息目录下对应的文件夹中:
/roach/backup_key/fine_file_list/dn_6001_6002/row/file_0_fine_list
/roach/backup_key/fine_file_list/dn_6001_6002/col/file_0_fine_list
2.5 备份表定义导出文件
细粒度恢复是在线进行的,在进行单表或多表恢复时需要创建出与原表定义相同的表,再进行表物理文件的替换,这就必须知道原表的DDL元信息。因此,在备份过程中需要同时导出各个表的DDL元信息。物理细粒度备份恢复利用的GaussDB(DWS)自带的gs_dump工具对表定义进行导出。由于该信息只用于恢复过程,因此在细粒度备份刚开始时会启动gs_dump去导出所有的表的DDL信息,并让备份过程与DDL导出并行,不需要阻塞等待,减少整体物理细粒度的备份时间。DDL导出流程如图5所示。
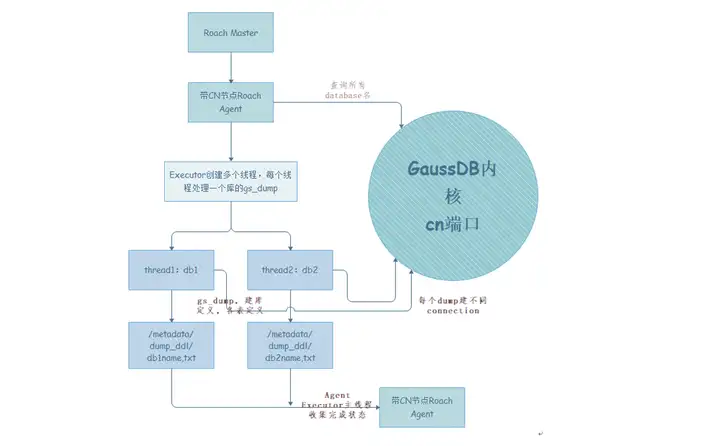
图5 导出DDL流程图
导出的DDL信息以schema为单位存储在节点元信息目录下对应的文件夹中:
/roach/backup_key/dumped_ddl/databasename.schemaname
2.6 物理细粒度备份整体流程
经过以上介绍,细粒度备份的关键步骤都已经清楚了,下面给出细粒度备份的整体流程图,如图6所示。
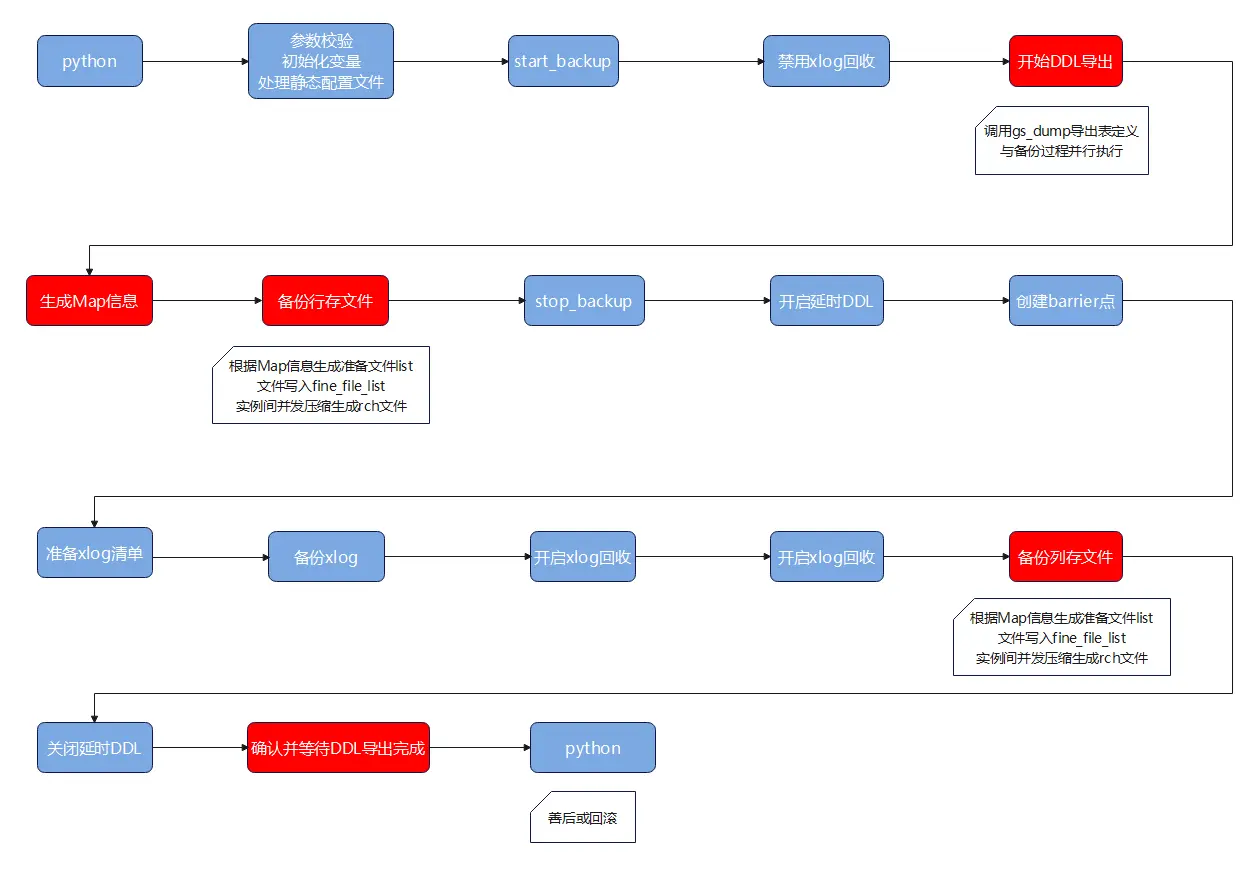
图6 物理细粒度备份流程图
3. 了解物理细粒度恢复
与集群级恢复停止集群进行数据覆盖的方式不同,细粒度恢复采用在线恢复的方式,该方法的核心思想就是在当前集群中创建与原表定义完全相同的目标表,再将两张表相关的物理文件进行一一替换。细粒度恢复的方法能够在线进行,对现有集群影响较小,但同时也对恢复过程数据的控制有了更高的要求。
物理细粒度恢复的大致流程如图7所示。
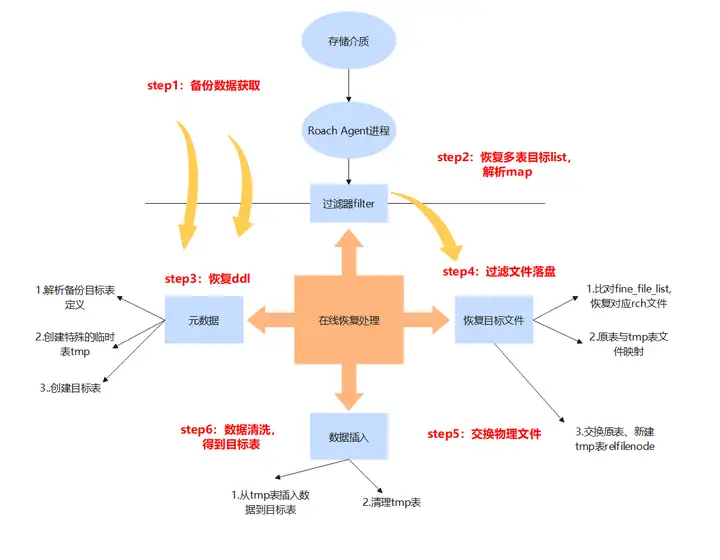
图7 物理细粒度恢复流程图
4. 使用物理细粒度备份恢复
GaussDB(DWS)的Roach工具现阶段支持schema级的物理细粒度备份,下面介绍如何发起物理细粒度备份以及如何从细粒度备份集中恢复一张表。
4.1 获取物理细粒度备份集
Roach工具现支持schema级的细粒度备份,如下为命令行中发起schema级物理细粒度备份的命令:

图8 发起schema级备份
以下参数为必选参数:
- –master-port : 进程端口号
- –media-type : 存储介质
- –media-destination : 压缩数据存储路径
- –metadata-destination : 元数据存储路径
- –dbname : 数据库名称
- –schema-list : 多schema清单文件名,内容格式为每行一个schema名
- –physical-fine-grained : 物理细粒度参数
其中指定schema清单时如果只有一个schema,也可以直接使用–schemaname参数直接指定需要备份的schema名称,此外,同时备份多个schema时,schema需要在同一个database下。
除了schema级别备份,为支持从集群级备份集中细粒度恢复单表或多表,可以通过在集群级命令中加入物理细粒度参数:–physical-fine-grained来生成细粒度恢复需要的Map文件、fine_file_list信息。如下为集群级带细粒度参数的命令:

图9 集群级备份带细粒度参数
需要说明的是,带细粒度参数的集群级备份依然是集群级的,只是为支持从该备份集细粒度恢复单表生成了额外的细粒度相关文件。
4.2 从物理细粒度备份集恢复表
Roach工具现支持从细粒度备份集或(集群级带细粒度参数备份集)恢复单表或多表,假如当前数据库用户不小心删除了一张表,又不想对停止业务对整个集群进行恢复,如果之前做过物理细粒度相关备份,备份集中有这张表,那么细粒度恢复就是最好的选择。细粒度恢复可以在线进行,不影响集群的正常使用,发起细粒度恢复的命令如下:

图10 细粒度恢复表命令
以下参数为必选参数:
- –clean
- –master-port
- –media-type
- –media-destination
- –metadata-destination
- –backup-key : 恢复基于的备份集
- –physical-fine-grained : 物理细粒度参数
- –dbname : 数据库名称
- –table-list : 待恢复表列表,格式为schemaname.tablename
- –restore-target-list : 恢复后表列表,格式为schemaname.tablename
其中–table-list指定了需要恢复的哪些表,–restore-target-list指定了恢复后表的名称,要求–restore-target-list的表顺序与–table-list的表顺序一一对应。如果要全部恢复到原表,则这两个表清单可以指向相同文件。两个表清单参数对应的文件内容格式是:每个表一行,且必须带schema名。
5. 总结
细粒度备份和恢复以更小的粒度对数据文件进行了备份恢复操作。考虑到备份数据的完整性以及备份恢复的性能,细粒度备份过程增加了ddl导出、Map文件生成等关键步骤,其中从数据目录下的物理文件信息到Map信息、再从Map信息到备份的rch文件对应的fine_file_list信息,形成了对备份数据文件连续的记录链条。恢复过程中如果出现缺少数据的情况,可以通过对备份过程中以上所说信息的互相对比快速定位到出现问题的环节,因此,掌握以上信息十分关键,可以帮助我们更好地使用细粒度备份恢复功能。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步