

带您了解昇腾模型压缩工具
摘要:昇腾模型压缩工具是一个针对昇腾芯片亲和的深度学习模型压缩工具包,提供量化、张量分解等多种模型压缩特性,致力于帮助用户高效实现模型的小型化。
本文分享自华为云社区《【CANN文档速递11期】带您了解昇腾模型压缩工具》,作者: 昇腾CANN 。
什么是AMCT,它能做什么?
昇腾模型压缩工具(Ascend Model Compression Toolkit,简称AMCT)是一个针对昇腾芯片亲和的深度学习模型压缩工具包,提供量化、张量分解等多种模型压缩特性,致力于帮助用户高效实现模型的小型化。
它实现了神经网络模型中数据与权重8比特量化、张量分解、模型部署优化(主要为BN融合)的功能,该工具将量化和模型转换分开,实现对模型中可量化算子的独立量化,最终输出量化后的模型。
其中,量化后的仿真模型可以在CPU或者GPU上运行,完成精度仿真;量化后的部署模型可以部署在昇腾AI处理器上运行,达到提升推理性能的目的。
AMCT功能介绍
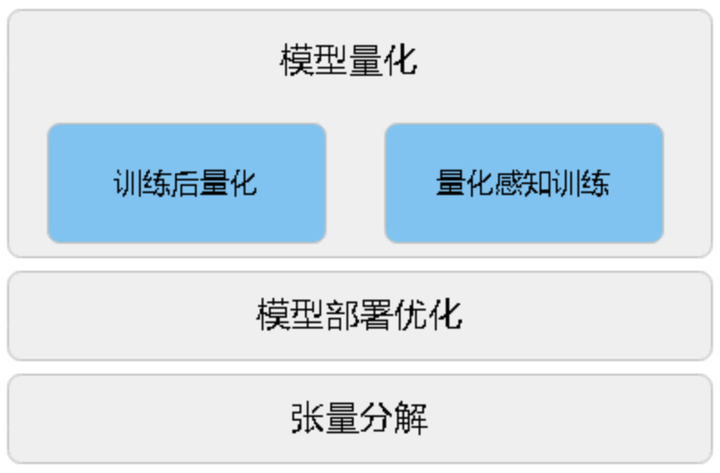
AMCT使用的模型压缩方法有:量化、张量分解、模型部署优化(主要为BN融合)。
量化:指对模型的权重(weight)和数据(activation)进行低比特处理,让最终生成的网络模型更加轻量化,从而达到节省网络模型存储空间、降低传输时延、提高计算效率,达到性能提升与优化的目标。其原理如下图所示:
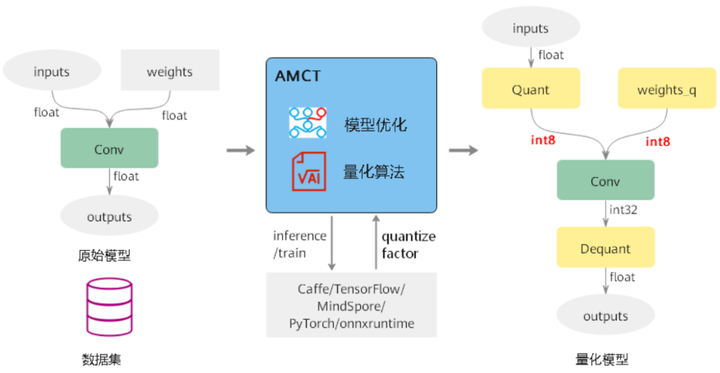
量化根据是否需要重训练,分为训练后量化和量化感知训练。
训练后量化(Post-Training Quantization,简称PTQ)
在模型训练结束之后进行的量化,再对训练好的模型进行权重和数据的量化,进而加速模型推理速度。
量化感知训练(Quantization-Aware Training,简称QAT)
在量化过程中,对模型进行训练的一种量化。QAT会在训练过程中引入伪量化的操作(从浮点量化到定点,再还原到浮点的操作),用来模拟前向推理时量化带来的误差,并借助训练让模型权重能更好地适应这种量化的信息损失,从而提升量化精度。
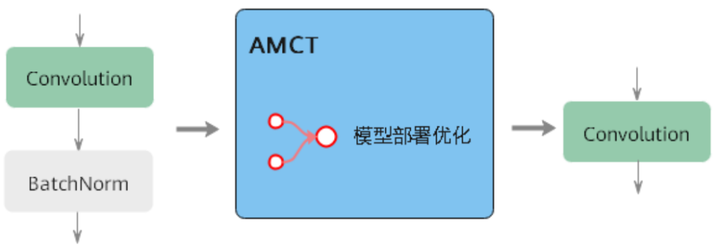
模型部署优化:主要为算子融合功能,指通过数学等价,将模型中的多个算子运算融合为单算子运算,以减少实际前向过程中的运算量,如将卷积层和BN层融合为一个卷积层。该功能在量化过程中实现,当前仅支持BN融合。其原理如下图所示:
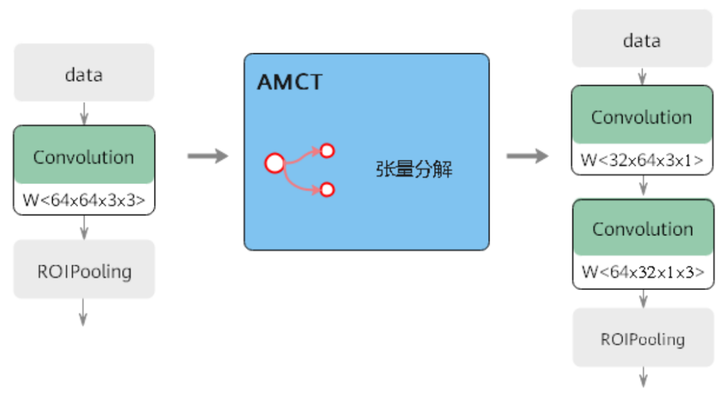
张量分解:通过分解卷积核的张量,可以将一个大卷积核分解为两个小卷积核的连乘,即将卷积核分解为低秩的张量,从而降低存储空间和计算量,降低推理开销。其原理如下图所示:
AMCT量化方式
AMCT支持两种方式的量化:命令行方式和Python API接口方式,区别如下:
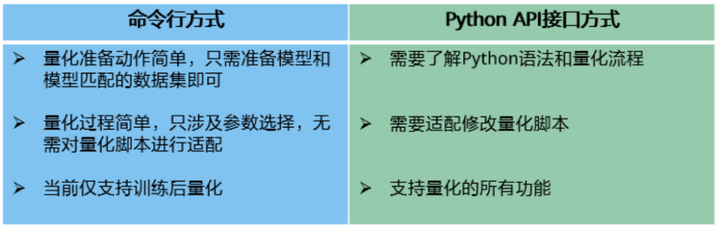
如果用户想快速体验AMCT,则可以使用命令行方式进行训练后量化 ,如果想体验更多功能,比如量化感知训练,则必须使用Python API接口方式实现。
如何使用AMCT
下图展示了使用AMCT进行量化的简单流程,用于需要先在符合版本要求的Linux服务器部署AMCT,完成模型量化操作,输出可部署的量化模型;然后借助ATC工具转成适配昇腾AI处理器的.om离线模型;最后使用.om离线模型,在昇腾AI处理器完成推理业务。
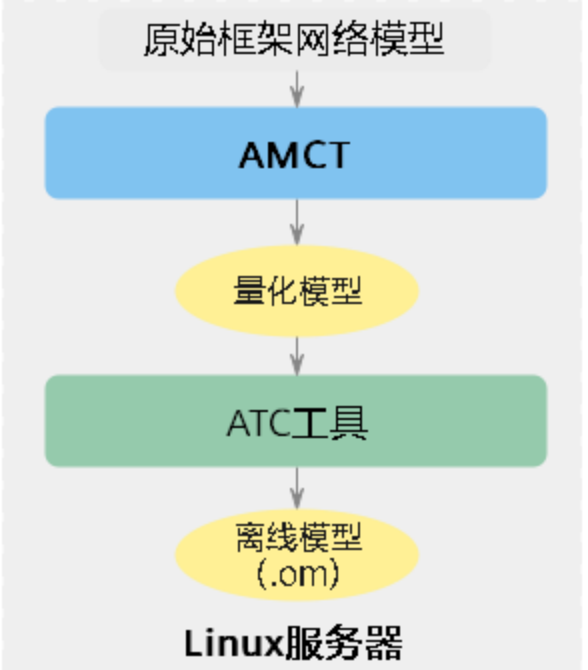
下面以Caffe框架ResNet-50网络模型为例,为您演示如何借助AMCT进行命令行方式的量化。
- 通过昇腾社区获取AMCT软件包,并完成安装。
在任意路径执行amct_caffe calibration --help命令,若回显参数信息,则说明AMCT能正常使用。 - 准备要进行量化的模型文件*.prototxt、权重文件*.caffemodel、以及与模型匹配的二进制数据集上传到AMCT所在Linux服务器。
- 执行如下命令进行训练后量化。

参数解释如下:
--model:原始网络模型文件路径与文件名。
--weight:原始网络模型权重文件路径与文件名。
--save_path:量化后模型的存放路径。
--input_shape:指定模型输入数据的shape。
--data_dir:二进制数据集路径。
--data_types:输入数据的类型。
- 量化完成后,在{save_path}参数指定路径下可以查看量化后的模型。
- (后续处理)用户使用上述量化后的模型,借助ATC工具转成适配昇腾AI处理器的.om离线模型,然后在安装昇腾AI处理器的服务器完成推理业务。
AMCT更多功能
下面介绍Caffe框架下通过Python API接口方式实现的各种功能。
训练后量化
接口调用流程
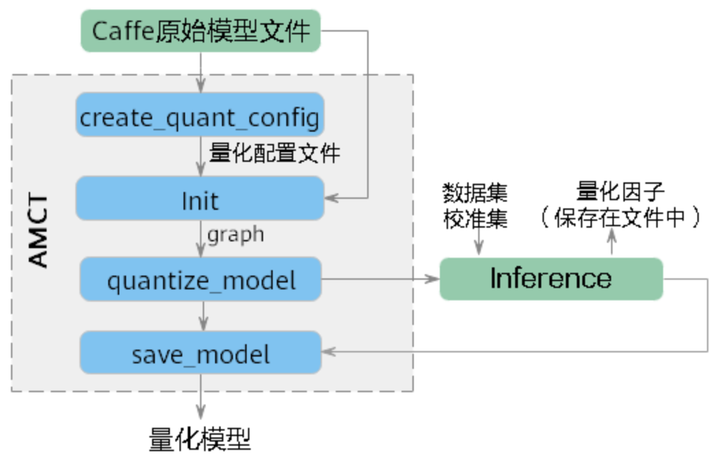
代码示例
- 导入AMCT包。

- 调用AMCT,量化模型。
- 解析用户模型,生成量化配置文件。

- 初始化AMCT,读取用户量化配置文件、解析用户模型文件、生成用户内部修改模型的Graph IR。

- 执行图融合、执行权重离线量化以及插入数据量化层得到校准模型,从而在后续校准推理过程中执行数据量化动作。

- 执行校准模型推理,完成数据量化(借助用户原始Caffe环境) 。

- 执行量化后图优化动作,并保存得到最终的量化部署模型(deploy)和量化仿真模型(fake_quant)。

量化感知训练
接口调用流程
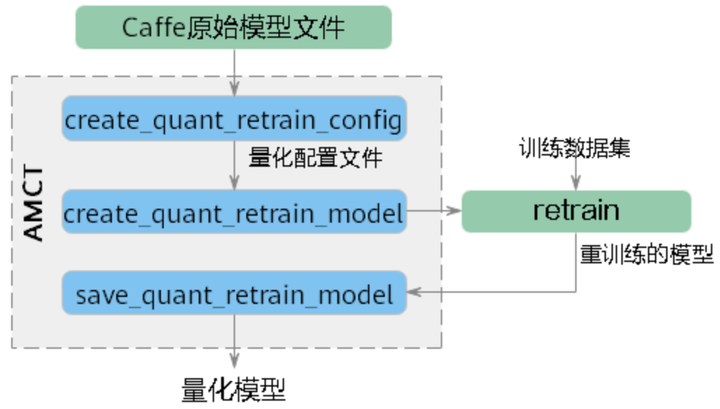
代码示例
- 导入AMCT包。

- 调用AMCT,量化模型。
- 解析用户模型,生成量化配置文件。

- 修改模型,插入伪量化层并存为新的模型文件。

- 使用修改后的模型,创建反向梯度,在训练集上做训练,训练量化因子(借助用户原始Caffe环境)。

- 保存模型。

张量分解
接口调用流程
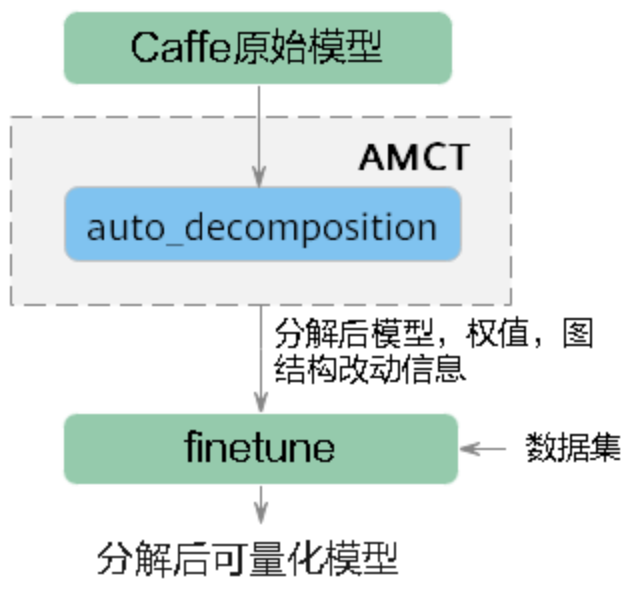
代码示例
- 导入AMCT相关模块。

- 调用接口执行张量分解。

- 对分解后的模型进行finetune,输出最终分解后的模型。
更多介绍
关于文中命令行方式更多参数、Python API方式接口介绍以及TensorFlow、ONNX、PyTorch、MindSpore等框架的AMCT用法介绍,请登录昇腾社区,阅读相关文档:https://www.hiascend.com/document。


· 全网最简单!3分钟用满血DeepSeek R1开发一款AI智能客服,零代码轻松接入微信、公众号、小程
· .NET 10 首个预览版发布,跨平台开发与性能全面提升
· 《HelloGitHub》第 107 期
· 全程使用 AI 从 0 到 1 写了个小工具
· 从文本到图像:SSE 如何助力 AI 内容实时呈现?(Typescript篇)
2021-09-15 鲲鹏BoostKit虚拟化使能套件,让数据加密更安全
2021-09-15 我用MRS-ClickHouse构建的用户画像系统,让老板拍手称赞
2021-09-15 DBA:介里有你没有用过的“CHUAN”新社区版本Redis6.0
2021-09-15 GaussDB(for MySQL)如何快速创建索引?华为云数据库资深架构师为您揭秘
2020-09-15 如何让知识图谱告诉你“故障根因”
2020-09-15 SpringBoot写后端接口,看这一篇就够了!
2020-09-15 我敢说,这个版本的斗地主你肯定没玩过?