从源码分析快速实现对新开源软件的检测
摘要:本文简单阐述如何基于源码来生成二进制SCA特征。
本文分享自华为云社区《基于源码的二进制SCA特征生成技术》,作者: 安全技术猿。
在二进制SCA检测原理中提到对于常量字符串、部分类名称、函数名称、以及一些配置信息还是存在的,并且这些信息具备一定的不变性;因此二进制SCA工具其中的一部分特征来源就包含这些信息。因此在特征库保存有每个开源软件的特征,二进制SCA工具在检测时会从待检测二进制文件中提取出特征,通过算法和特征库的保存的开源软件特征进行相似度计算,从而判断该二进制文件中引用了哪些开源软件及对应的版本号。
二进制SCA检测处理流程:
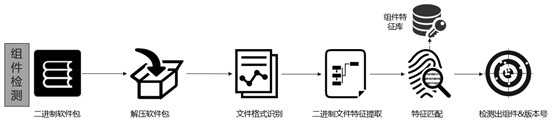
从检测流程和方法中可以看出特征库中保存的特征来源并没有规定一定从二进制文件中生成,而是只要满足特征库中的特征必须和二进制中生成的特征要一致,因为计算相似度时其中一个输入的特征是从二进制文件中提取到的。很明显特征库中特征来源无非就2条路径:一条来自二进制文件,另外一条那就是来自生成二进制的源代码。
不同特征来源优缺点比较:
1. 二进制文件特征提取优点:
基于二进制文件来提取特征具有提取方便,和检测时提取方法一致,不需要额外开发提取工具和提取算法。
2. 二进制文件特征提取缺点:
- a. 二进制文件首先需要由源代码编译出来,而搭建构建编译环境可能会很复杂,需要很多额外的工作量,效率低;
- b.由于编译宏的原因,由源代码生成的二进制文件并不一定是全量源代码都包含中其中的,可能只有部分源代码参与生成最终的二进制文件;
- c.由于构建依赖的原因,二进制文件中包含有依赖对象的信息,也就是说包含有源代码之外对象的信息,这会导致提取到的特征纯度不足,直接影响到检测结果的准确性;
3. 源码特征提取优点:
正好可以解决从二进制文件中生成特征的短板问题,不需要编译可以大大提升自动化出来水平和提取效率,提取到的特征只限于源代码中的特征和其他无关,提取到的特征纯度很高。
4. 源码特征提取缺点:
针对不同语言类型需要额外开发相应的特征提取工具来实现特征提取,开发工作量大,且不同语言的特征提取工具开的发难度也不一样,对开发者是一个挑战。
基于源码的特征生成方法:
不同语言具有不同的特点,在考虑基于源码的特征生成方法时需要考虑到语言特点来采用针对性的方法来解决,这样可以起到事半功倍的作用。下面针对不同语言分别来说明对应的解决方法:
- C语言:没有类的复杂性,在构建时只要用到的源码文件,该文件中的所有函数信息都会被一起编译进二进制文件中。
- C++语言:引入了类的复杂性,在构建时只要引用了类的实例,该类信息才会被编译到二进制文件中,而不像C语言一个源代码文件是一个整体来处理的。另外类中的构造函数和析构函数会被编译器自动引入在二进制文件中,从而出现源代码和二进制文件不一致情况。
- Java语言:也存在类的复杂性,特别是嵌套类和内部类的情况,这也导致源代码特征和二进制特征之间的处理难点。
- Go语言:具备依赖管理机制,但编译出来的二进制文件却和C、C++一样具有PE、ELF格式,go语言的模块特性也带来了源码提取的特征和二进制之间的差别,此外go语言相比C、C++来说更容易生成对应源代码的抽象语法树AST。
- Python语言:也具备依赖管理机制,但pyc和pyd之间差别很大,pyc是字节码格式可以很方便的进行反编译,但pyd则像C、C++一样是指令码式文件,因此特征提取方法完全不一样,同样也带来了源代码提取特征和二进制提取特征之间的不一致问题需要解决,比如:1. python源码在编译成pyc时有一些编译优化,在源码提取特征时要加入编译优化,且不同版本编译优化有差异,统一使用最多的编译优化提取源码特征并且pyc文件提取特征时也需要进行适当的优化;2. python不同版本同一代码翻译成的指令序列不一样,pyc提取特征时要兼容多个版本;3. py2、py3的pyc中字符串的编码方式不一样,而且unicode的支持范围不一样,需要保证字符串特征提取一致;同样Python源代码也相对容易的可以生成对应源代码的抽象语法树AST。
- 另外对于C、C++源代码由于存在依赖和构建环境的原因而导致源代码无法编译,而很多工具需要能编译成功才能获取到AST的,比如CDT、Clang等,在这种情况下就没法使用了,必须使用具备词法分析和语法分析能力的工具来获取特征相关一些数据,比如cppcheck工具。不管是基于AST还是词法、语法分析输出数据,都需要自己在此数据的基础上开发相应的数据分析工具来提取到最终的开源软件特征,并且该特征数据和从二进制文件中提取到的特征数据具有很好的一致性要求。
总结:
只有具备从源码中生成上述特征,才能充分利用源码特征提取优点,进行自动化的特征提取,提升特征提取效率,快速实现对新出现开源软件的检测能力。
