论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别、文字检测、文字识别、单元格和文字框对齐。其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识别用到的是Master模型。
本文分享自华为云社区《论文解读二十八:表格识别模型TableMaster》,作者: cver。

1. 概述
在表格识别中,模型一般先回归出单元格的坐标,然后再根据单元格的坐标得到表格的行列信息。对于有表格线的场景,模型可以比较准确地获取单元格坐标,进而可以利用单元格坐标后处理得到行列信息。对于无表格线情况,通常难以直接得到单元格位置或表格线信息,这时通常需要利用模型训练的方式获取文字块的空间布局。例如在图模型中,常见的识别流程是先由OCR模型获取文字框的坐标和文字内容,然后结合视觉、位置、语义等多模态信息,并利用图网络来预测文字节点的行列属性,进而恢复出表格的结构。
在平安科技最新发布的表格识别模型TableMaster中,提出了另外一种解决思路,即同时训练得到单元格内的文字块位置和表格结构。这里涉及到表格的另一种表达形式,这种形式在网页中经常被用到,也即用超文本标记语言来定义表格(如图1)。

图1 表格的超文本标记符和对应的表格
根据超文本标记语言的语法规则,表格是由 <table> 标签来定义,每个表格均有若干行(由 <tr> 标签定义),每行被分割为若干单元格(由 <td> 标签定义)。从图1可以看出,一个表格被表示成了一段文本字符序列,这样就可以用序列化的模型(seq2seq或transformer)来进行表格结构预测。
2.TableMaster
2.1 表格结构识别流程
TableMaster采用多任务的学习模式,它有两个分支,一个分支进行表格结构序列预测,一个分支进行单元格位置回归。在TableMaster识别结束后,识别结果经过后处理匹配算法,融合表格结构序列和单元格文本内容,得到表格最终的html(如图2)。

图2 TableMaster表格识别流程 2.2 TableMaster原理
2.2 TableMaster原理
2.2.1 网络架构
TableMaster基于Master[2]模型进行了修改。Master是平安自研的文本识别模型, 其网络结构分为编码和解码两个部分。编码的网络结构借鉴ResNet的残差连接结构。和ResNet不同的是,Master的编码网络在每一个残差连接块之后接了一个多头通道注意力模块(Multi-Aspect GCAttention):
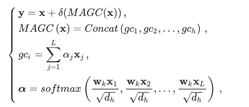
其中h是多头注意力的个数。
编码阶段是整个Master网络的关键,其把一张图片转换成序列,使得可以用Transformer进行解码。在编码阶段输入的图片维度为:48*160*1,输出的维度为6*40*512,其中512就是模型的序列长度。编码阶段输出的序列特征再经过位置编码,输入到解码阶段。解码部分是由三个常规的Transformer 解码层组成(如图3)。
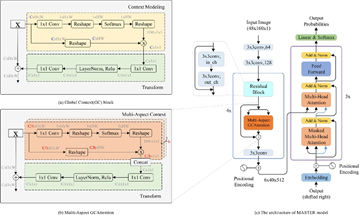
图3 Master模型结构,图片来源[2]
TableMaster特征提取模型也即编码结构和Master一致,和Master结构不同的地方在解码部分。TableMaster的解码部分相对于Master增加了一个分支:在经过一个Transformer层之后,TableMaster的解码部分分成两个分支。之后每个分支再接两个Transformer层,分别对应两个学习任务:单元格文字框的回归以及表格结构序列的预测。
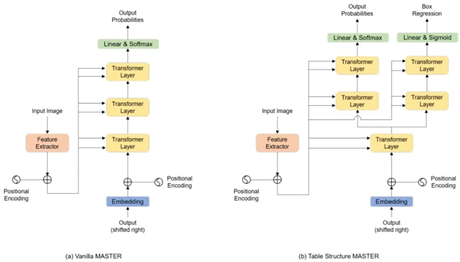
图4 TableMaster和Master模型结构对比,图片来源[1]
2.2.2 输入和输出
TableMaster特征提取阶段输入图片的维度为480*480*3,输出的维度为7*7*500,然后把输出的序列特征reshape到49*500,输入到解码阶段。其中500是模型的序列长度,49为每个位置序列特征的维度。表格的类别标签有38个(如图5),再加上开始和结束两个标签,模型中用到的类别标签一共是41个。

图5 Tablemaster模型中表格的38类标签,图片来源[1]
其中有两个<td></td>,一个表示空单元格,一个表示非空单元格。
标记符中有<tbody>、</tbody>、<tr>、</tr>等表示表格开始和行的标记符以及空单元格的标记符。这些标记符没有对应的文字块坐标。因此标记符序列长度比实际的单元格序列长。为了使得单元格序列和标记符序列一样长,在单元格序列中,对应于<tbody>、</tbody>、<tr>、</tr>标记的位置会填充为0。而这些位置的坐标在回归单元格坐标时不用于参数的更新,会被一个Mask过滤掉。
下图展示了TableMaster识别的表格结构序列和单元格坐标:
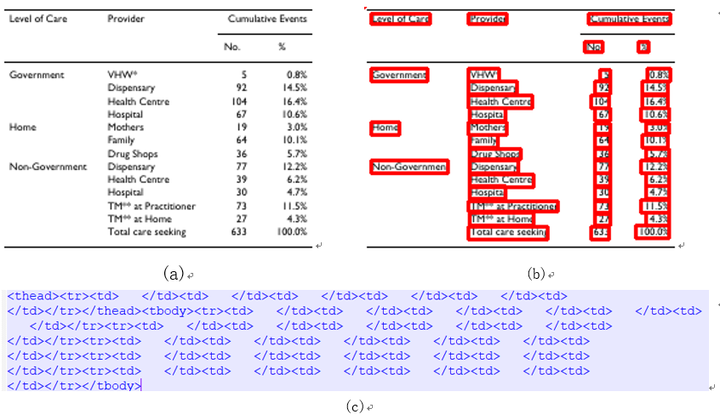
图6 TableMaster预测的结果。(a)原图;(b)预测的文字框;(c)预测的表格结构序列
2.2.3 文字框定位和识别
在文字检测和识别阶段用到的文字检测模型为经典的PSENet[3]。文字识别用到的模型就是上文提到的Master。利用PSENet+Master模型组合,文字端到端的识别精度可以达到0.9885。
2.2.4 还原完整的html
TableMaster网络输出的表格结构序列并不是最终的html序列。为了得到表格最终的html序列还需要在表格结构标记符中填充对应的文字内容,其流程如下:
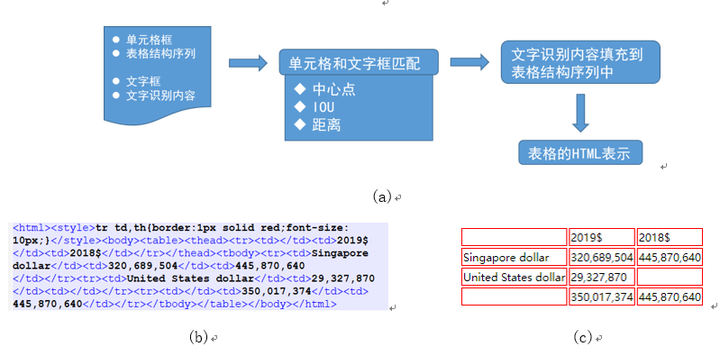
图7 由识别结果到最终的html序列。(a)流程图;(b)最终的html序列;(c)html序列可视化
其中重要的一步就是单元格的匹配:根据单元格坐标和文字框坐标,把文字框坐标和单元格坐标进行对齐,然后就可以把对应文字框的识别内容填充到对应单元格的标记符序列中,从而得到最终的html文本。文字框的对齐主要基于三个规则:1、中心点规则,如果文字框的中心点在单元格框内,则把文字框相应的文字内容填充到对应的<td></td>中;2、IOU规则,在第一点不满足的情况下,计算和文字框具有最大IOU的单元格框作为匹配项;3、距离原则,如果以上两点都不满足,则计算所有单元格和文字框的距离,选取距离最小的单元格框作为匹配项。
通过序列化模型来进行表格结构的还原是一种有效的表格结构识别方法,类似的还有百度的RARE。和TableMaster不同的是,RARE把TableMaster中的Transformer换成了GRU。另外,该方法只利用了图像的视觉信息,后续工作中可以结合多模态特征得到更好效果。
文献引用
[1] Jiaquan Ye , Xianbiao Qi , Yelin He , Yihao Chen , Dengyi Gu , Peng Gao , and Rong Xiao. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML. arXiv:2105.01848, 2021.
[2] Ning Lu, Wenwen Yu, Xianbiao Qi, Yihao Chen, Ping Gong, Rong Xiao, and Xiang Bai. Master: Multi-aspect non-local network for scene text recognition. Pattern Recognition, 2021.
[3]Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu, Gang Yu, and Shuai Shao. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9336–9345, 2019.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号