如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境。
本文分享自华为云社区《基于Jupyter Notebook 搭建Spark集群开发环境》,作者:apr鹏鹏。
一、概念介绍:
1、Sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具。Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行。
2、Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:提交Scala、Python或是R代码片段到远端的Spark集群上执行,提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行和提交批处理应用在集群中运行
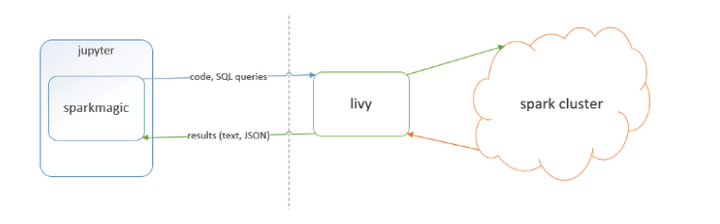
二、基本框架为下图所示:
三、准备工作:
具备提供Saprk集群,自己可以搭建或者直接使用华为云上服务,如MRS,并且在集群上安装Spark客户端。同节点(可以是docker容器或者虚拟机)安装Jupyter Notebook和Livy,安装包的路径为:https://livy.incubator.apache.org/download/
四、配置并启动Livy:
修改livy.conf 参考:https://enterprise-docs.anaconda.com/en/latest/admin/advanced/config-livy-server.html
添加如下配置:
livy.spark.master = yarn livy.spark.deploy-mode = cluster livy.impersonation.enabled = false livy.server.csrf-protection.enabled = false livy.server.launch.kerberos.keytab=/opt/workspace/keytabs/user.keytab livy.server.launch.kerberos.principal=miner livy.superusers=miner
修改livy-env.sh, 配置SPARK_HOME、HADOOP_CONF_DIR等环境变量
export JAVA_HOME=/opt/Bigdata/client/JDK/jdk export HADOOP_CONF_DIR=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop export SPARK_HOME=/opt/Bigdata/client/Spark2x/spark export SPARK_CONF_DIR=/opt/Bigdata/client/Spark2x/spark/conf export LIVY_LOG_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/logs export LIVY_PID_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/pids export LIVY_SERVER_JAVA_OPTS="-Djava.security.krb5.conf=/opt/Bigdata/client/KrbClient/kerberos/var/krb5kdc/krb5.conf -Dzookeeper.server.principal=zookeeper/hadoop.hadoop.com -Djava.security.auth.login.config=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop/jaas.conf -Xmx128m"
启动Livy:
./bin/livy-server start
五、安装Jupyter Notebook和sparkmagic
Jupyter Notebook是一个开源并且使用很广泛项目,安装流程不在此赘述
sparkmagic可以理解为在Jupyter Notebook中的一种kernel,直接pip install sparkmagic。注意安装前系统必须具备gcc python-dev libkrb5-dev工具,如果没有,apt-get install或者yum install安装。安装完以后会生成$HOME/.sparkmagic/config.json文件,此文件为sparkmagic的关键配置文件,兼容spark的配置。关键配置如图所示

其中url为Livy服务的ip和端口,支持http和https两种协议
六、添加sparkmagic kernel
PYTHON3_KERNEL_DIR="$(jupyter kernelspec list | grep -w "python3" | awk '{print $2}')"
KERNELS_FOLDER="$(dirname "${PYTHON3_KERNEL_DIR}")"
SITE_PACKAGES="$(pip show sparkmagic|grep -w "Location" | awk '{print $2}')"
cp -r ${SITE_PACKAGES}/sparkmagic/kernels/pysparkkernel ${KERNELS_FOLDER}
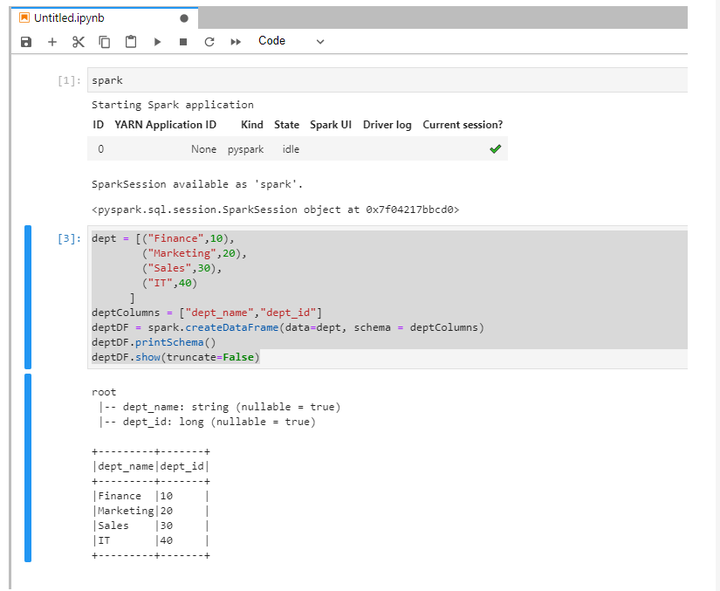
七、在Jupyter Notebook中运行spark代码验证:
八、访问Livy查看当前session日志: