
基于Tensorflow + Opencv 实现CNN自定义图像分类
摘要:本篇文章主要通过Tensorflow+Opencv实现CNN自定义图像分类案例,它能解决我们现实论文或实践中的图像分类问题,并与机器学习的图像分类算法进行对比实验。
本文分享自华为云社区《Tensorflow+Opencv实现CNN自定义图像分类及与KNN图像分类对比》,作者:eastmount 。
一.图像分类
图像分类(Image Classification)是对图像内容进行分类的问题,它利用计算机对图像进行定量分析,把图像或图像中的区域划分为若干个类别,以代替人的视觉判断。图像分类的传统方法是特征描述及检测,这类传统方法可能对于一些简单的图像分类是有效的,但由于实际情况非常复杂,传统的分类方法不堪重负。现在,广泛使用机器学习和深度学习的方法来处理图像分类问题,其主要任务是给定一堆输入图片,将其指派到一个已知的混合类别中的某个标签。
在下图中,图像分类模型将获取单个图像,并将为4个标签{cat,dog,hat,mug},分别对应概率{0.6, 0.3, 0.05, 0.05},其中0.6表示图像标签为猫的概率,其余类比。该图像被表示为一个三维数组。在这个例子中,猫的图像宽度为248像素,高度为400像素,并具有红绿蓝三个颜色通道(通常称为RGB)。因此,图像由248×400×3个数字组成或总共297600个数字,每个数字是一个从0(黑色)到255(白色)的整数。图像分类的任务是将这接近30万个数字变成一个单一的标签,如“猫(cat)”。
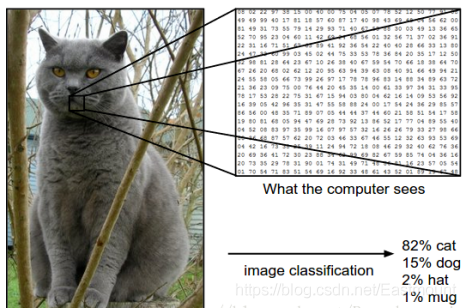
那么,如何编写一个图像分类的算法呢?又怎么从众多图像中识别出猫呢?这里所采取的方法和教育小孩看图识物类似,给出很多图像数据,让模型不断去学习每个类的特征。在训练之前,首先需要对训练集的图像进行分类标注,如图所示,包括cat、dog、mug和hat四类。在实际工程中,可能有成千上万类别的物体,每个类别都会有上百万张图像。

图像分类是输入一堆图像的像素值数组,然后给它分配一个分类标签,通过训练学习来建立算法模型,接着使用该模型进行图像分类预测,具体流程如下:
- 输入: 输入包含N个图像的集合,每个图像的标签是K种分类标签中的一种,这个集合称为训练集。
- 学习: 第二步任务是使用训练集来学习每个类的特征,构建训练分类器或者分类模型。
- 评价: 通过分类器来预测新输入图像的分类标签,并以此来评价分类器的质量。通过分类器预测的标签和图像真正的分类标签对比,从而评价分类算法的好坏。如果分类器预测的分类标签和图像真正的分类标签一致,表示预测正确,否则预测错误。
常见的分类算法包括朴素贝叶斯分类器、决策树、K最近邻分类算法、支持向量机、神经网络和基于规则的分类算法等,同时还有用于组合单一类方法的集成学习算法,如Bagging和Boosting等。
二.基于KNN算法的图像分类
1.KNN算法
K最近邻分类(K-Nearest Neighbor Classifier)算法是一种基于实例的分类方法,是数据挖掘分类技术中最简单常用的方法之一。该算法的核心思想是从训练样本中寻找所有训练样本X中与测试样本距离(欧氏距离)最近的前K个样本(作为相似度),再选择与待分类样本距离最小的K个样本作为X的K个最邻近,并检测这K个样本大部分属于哪一类样本,则认为这个测试样本类别属于这一类样本。
假设现在需要判断下图中的圆形图案属于三角形还是正方形类别,采用KNN算法分析如下:
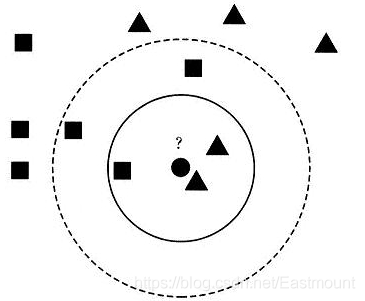
- 当K=3时,图中第一个圈包含了三个图形,其中三角形2个,正方形一个,该圆的则分类结果为三角形。
- 当K=5时,第二个圈中包含了5个图形,三角形2个,正方形3个,则以3:2的投票结果预测圆为正方形类标。设置不同的K值,可能预测得到不同的结果。
简而言之,一个样本与数据集中的k个最相邻样本中的大多数的类别相同。由其思想可以看出,KNN是通过测量不同特征值之间的距离进行分类,而且在决策样本类别时,只参考样本周围k个“邻居”样本的所属类别。因此比较适合处理样本集存在较多重叠的场景,主要用于预测分析、文本分类、降维等处理。
KNN在Sklearn机器学习包中,实现的类是neighbors.KNeighborsClassifier,简称KNN算法。构造方法为:
KNeighborsClassifier(algorithm='ball_tree',
leaf_size=30,
metric='minkowski',
metric_params=None,
n_jobs=1,
n_neighbors=3,
p=2,
weights='uniform')KNeighborsClassifier可以设置3种算法:brute、kd_tree、ball_tree,设置K值参数为n_neighbors=3。调用方法如下:
- from sklearn.neighbors import KNeighborsClassifier
- knn = KNeighborsClassifier(n_neighbors=3, algorithm=“ball_tree”)
它包括两个步骤:
- 训练:nbrs.fit(data, target)
- 预测:pre = clf.predict(data)
2.数据集
该部分主要使用Scikit-Learn包进行Python图像分类处理。Scikit-Learn扩展包是用于Python数据挖掘和数据分析的经典、实用扩展包,通常缩写为Sklearn。Scikit-Learn中的机器学习模型是非常丰富的,包括线性回归、决策树、SVM、KMeans、KNN、PCA等等,用户可以根据具体分析问题的类型选择该扩展包的合适模型,从而进行数据分析,其安装过程主要通过“pip install scikit-learn”实现。
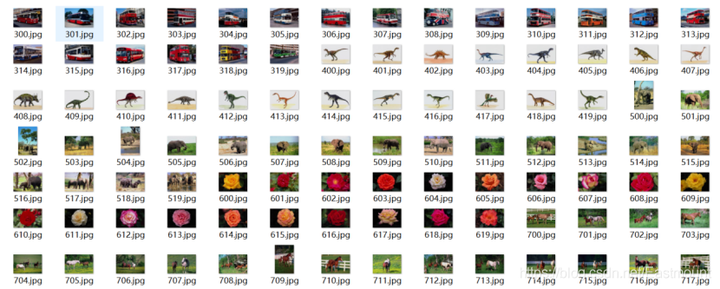
实验所采用的数据集为Sort_1000pics数据集,该数据集包含了1000张图片,总共分为10大类,分别是人(第0类)、沙滩(第1类)、建筑(第2类)、大卡车(第3类)、恐龙(第4类)、大象(第5类)、花朵(第6类)、马(第7类)、山峰(第8类)和食品(第9类),每类100张。如图所示。
接着将所有各类图像按照对应的类标划分至“0”至“9”命名的文件夹中,如图所示,每个文件夹中均包含了100张图像,对应同一类别。
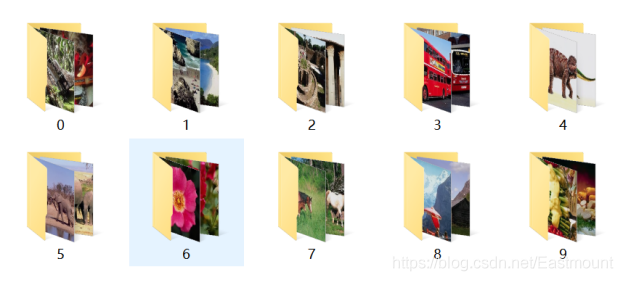
比如,文件夹名称为“6”中包含了100张花的图像,如下图所示。
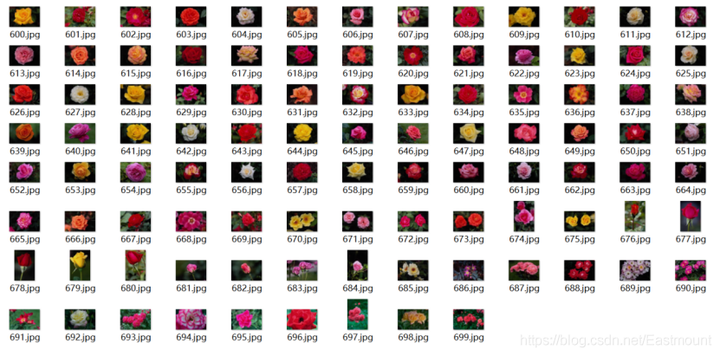
3.KNN图像分类
下面是调用KNN算法进行图像分类的完整代码,它将1000张图像按照训练集为70%,测试集为30%的比例随机划分,再获取每张图像的像素直方图,根据像素的特征分布情况进行图像分类分析。KNeighborsClassifier()核心代码如下:
- from sklearn.neighbors import KNeighborsClassifier
- clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train)
- predictions_labels = clf.predict(XX_test)
完整代码及注释如下:
# -*- coding: utf-8 -*-
import os
import cv2
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
#----------------------------------------------------------------------------------
# 第一步 切分训练集和测试集
#----------------------------------------------------------------------------------
X = [] #定义图像名称
Y = [] #定义图像分类类标
Z = [] #定义图像像素
for i in range(0, 10):
#遍历文件夹,读取图片
for f in os.listdir("photo/%s" % i):
#获取图像名称
X.append("photo//" +str(i) + "//" + str(f))
#获取图像类标即为文件夹名称
Y.append(i)
X = np.array(X)
Y = np.array(Y)
#随机率为100% 选取其中的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=0.3, random_state=1)
print len(X_train), len(X_test), len(y_train), len(y_test)
#----------------------------------------------------------------------------------
# 第二步 图像读取及转换为像素直方图
#----------------------------------------------------------------------------------
#训练集
XX_train = []
for i in X_train:
#读取图像
#print i
image = cv2.imread(i)
#图像像素大小一致
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
#计算图像直方图并存储至X数组
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_train.append(((hist/255).flatten()))
#测试集
XX_test = []
for i in X_test:
#读取图像
#print i
image = cv2.imread(i)
#图像像素大小一致
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
#计算图像直方图并存储至X数组
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_test.append(((hist/255).flatten()))
#----------------------------------------------------------------------------------
# 第三步 基于KNN的图像分类处理
#----------------------------------------------------------------------------------
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train)
predictions_labels = clf.predict(XX_test)
print u'预测结果:'
print predictions_labels
print u'算法评价:'
print (classification_report(y_test, predictions_labels))
#输出前10张图片及预测结果
k = 0
while k<10:
#读取图像
print X_test[k]
image = cv2.imread(X_test[k])
print predictions_labels[k]
#显示图像
cv2.imshow("img", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
k = k + 1代码中对预测集的前十张图像进行了显示,其中“818.jpg”图像如图所示,其分类预测的类标结果为“8”,表示第8类山峰,预测结果正确。

下图展示了“452.jpg”图像,其分类预测的类标结果为“4”,表示第4类恐龙,预测结果正确。

下图展示了“507.jpg”图像,其分类预测的类标结果为“7”,错误地预测为第7类恐龙,其真实结果应该是第5类大象。
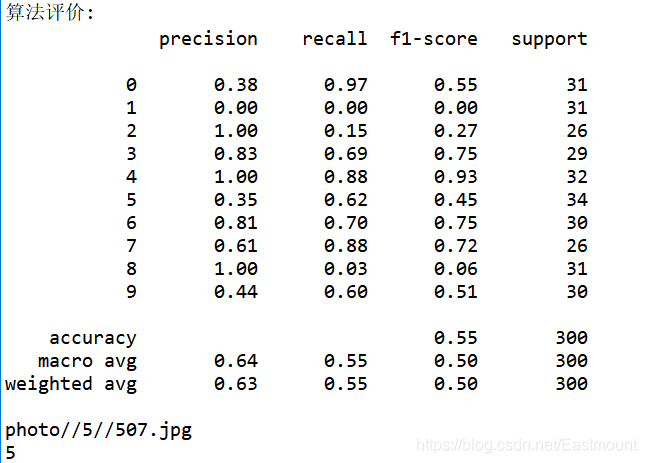
使用KNN算法进行图像分类实验,最后算法评价的准确率(Precision)、召回率(Recall)和F值(F1-score)如图所示,其中平均准确率为0.64,平均召回率为0.55,平均F值为0.50,其结果不是非常理想。那么,如果采用CNN卷积神经网络进行分类,通过不断学习细节是否能提高准确度呢?
三.Tensorflow+Opencv实现CNN图像分类
首先,我们需要在TensorFlow环境下安装OpenCV扩展包;其次需要通过TensorFlow环境搭建CNN神经网络;最后通过不断学实现图像分类实验。
1.OpenCV库安装
第一步,打开Anaconda程序,并选择已经安装好的“TensorFlow”环境,运行Spyder。
第二步,我们需要在TensorFlow环境中安装opencv-python扩展包,否则会提示错误“ModuleNotFoundError: No module named ‘cv2’”。调用Anaconda Prompt安装即可,如下图所示:
activate tensorflow
pip install opencv-python
安装成功如下图所示。
但是,由于anaconda的.org服务器在国外,下载速度很慢,提示错误“Anaconda An HTTP error occurred when trying to retrieve this URL.HTTP errors are often intermittent”。
- 解决方法一:从国内清华的镜像下载
- 解决方法二:从PYPI网站下载对应版本的opencv-python,在再安装本地下载的.whl文件。下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#OpenCV
由于第一种方法一直失败,这里推荐读者尝试第二种方法,同时作者会将“opencv_python-4.1.2-cp36-cp36m-win_amd64.whl”文件上传供大家直接使用。(4.1.2代表opencv的版本,cp36代表用的python3.6,并且是64位)。
第三步,调用PIP安装本地opencv扩展包。
activate tensorflow
pip install C:\Users\xiuzhang\Desktop\TensorFlow\opencv_python-4.1.2-cp36-cp36m-win_amd64.whl
这种方法非常迅速,推荐大家使用。安装成功之后,开始编写我们的代码吧!
2.读取文件夹图像
该部分具体步骤如下:
- 定义函数read_img(),读取文件夹“photo”中“0”到“9”的图像
- 调用cv2.imread()函数循环获取每张图片的所有像素值,并通过
cv2.resize()统一修改为32*32大小 - 依次获取图像像素、图像类标和图像路径名称:fpaths, data, label = read_img(path)
- 将图像的顺序随机调整,并按照2-8比例划分数据集,其中80%的数据用于训练,20%的数据用于测试
#---------------------------------第一步 读取图像-----------------------------------
def read_img(path):
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
imgs = []
labels = []
fpath = []
for idx, folder in enumerate(cate):
# 遍历整个目录判断每个文件是不是符合
for im in glob.glob(folder + '/*.jpg'):
#print('reading the images:%s' % (im))
img = cv2.imread(im) #调用opencv库读取像素点
img = cv2.resize(img, (32, 32)) #图像像素大小一致
imgs.append(img) #图像数据
labels.append(idx) #图像类标
fpath.append(path+im) #图像路径名
#print(path+im, idx)
return np.asarray(fpath, np.string_), np.asarray(imgs, np.float32), np.asarray(labels, np.int32)
# 读取图像
fpaths, data, label = read_img(path)
print(data.shape) # (1000, 256, 256, 3)
# 计算有多少类图片
num_classes = len(set(label))
print(num_classes)
# 生成等差数列随机调整图像顺序
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
fpaths = fpaths[arr]
# 拆分训练集和测试集 80%训练集 20%测试集
ratio = 0.8
s = np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
fpaths_train = fpaths[:s]
x_val = data[s:]
y_val = label[s:]
fpaths_test = fpaths[s:]
print(len(x_train),len(y_train),len(x_val),len(y_val)) #800 800 200 200
print(y_val)3.搭建CNN
该部分具体步骤如下:
- 首先定义Placeholder,用于传入输入值,xs表示图片32*32像素点,并且包含RGB三个图层,故大小设置为32 * 32 * 3;ys表示每张图片最终预测的类标值。
- 调用tf.layers.conv2d()函数定义卷积层,包括20个卷积核,卷积核大小为5,激励函数为Relu;调用tf.layers.max_pooling2d()函数定义池化处理,步长为2,缩小一倍。
- 接着定义第二个卷积层和池化层,现共有conv0, pool0和conv1, pool1。
- 通过tf.layers.dense()函数定义全连接层,转换为长度为400的特征向量,加上DropOut防止过拟合。
- 输出层为logits,包括10个数字,最终预测结果为predicted_labels,即为tf.arg_max(logits, 1)。
#---------------------------------第二步 建立神经网络-----------------------------------
# 定义Placeholder
xs = tf.placeholder(tf.float32, [None, 32, 32, 3]) #每张图片32*32*3个点
ys = tf.placeholder(tf.int32, [None]) #每个样本有1个输出
# 存放DropOut参数的容器
drop = tf.placeholder(tf.float32) #训练时为0.25 测试时为0
# 定义卷积层 conv0
conv0 = tf.layers.conv2d(xs, 20, 5, activation=tf.nn.relu) #20个卷积核 卷积核大小为5 Relu激活
# 定义max-pooling层 pool0
pool0 = tf.layers.max_pooling2d(conv0, [2, 2], [2, 2]) #pooling窗口为2x2 步长为2x2
print("Layer0:\n", conv0, pool0)
# 定义卷积层 conv1
conv1 = tf.layers.conv2d(pool0, 40, 4, activation=tf.nn.relu) #40个卷积核 卷积核大小为4 Relu激活
# 定义max-pooling层 pool1
pool1 = tf.layers.max_pooling2d(conv1, [2, 2], [2, 2]) #pooling窗口为2x2 步长为2x2
print("Layer1:\n", conv1, pool1)
# 将3维特征转换为1维向量
flatten = tf.layers.flatten(pool1)
# 全连接层 转换为长度为400的特征向量
fc = tf.layers.dense(flatten, 400, activation=tf.nn.relu)
print("Layer2:\n", fc)
# 加上DropOut防止过拟合
dropout_fc = tf.layers.dropout(fc, drop)
# 未激活的输出层
logits = tf.layers.dense(dropout_fc, num_classes)
print("Output:\n", logits)
# 定义输出结果
predicted_labels = tf.arg_max(logits, 1)4.定义损失函数和优化器
利用交叉熵定义损失,同时用AdamOptimizer优化器进行深度学习,核心代码如下。
one-hot类型数据又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。例如[0 0 0 1 0 0 0 0 0 0…] 表示为“动物”。
# 利用交叉熵定义损失
losses = tf.nn.softmax_cross_entropy_with_logits(
labels = tf.one_hot(ys, num_classes), #将input转化为one-hot类型数据输出
logits = logits)
# 平均损失
mean_loss = tf.reduce_mean(losses)
# 定义优化器 学习效率设置为0.0001
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(losses)5.模型训练和预测
定义标记变量train,当它为True时进行训练操作并保存训练模型;当其为False时进行预测,20%预测集进行图像分类预测实验。
#------------------------------------第四步 模型训练和预测-----------------------------------
# 用于保存和载入模型
saver = tf.train.Saver()
# 训练或预测
train = False
# 模型文件路径
model_path = "model/image_model"
with tf.Session() as sess:
if train:
print("训练模式")
# 训练初始化参数
sess.run(tf.global_variables_initializer())
# 定义输入和Label以填充容器 训练时dropout为0.25
train_feed_dict = {
xs: x_train,
ys: y_train,
drop: 0.25
}
# 训练学习1000次
for step in range(1000):
_, mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=train_feed_dict)
if step % 50 == 0: #每隔50次输出一次结果
print("step = {}\t mean loss = {}".format(step, mean_loss_val))
# 保存模型
saver.save(sess, model_path)
print("训练结束,保存模型到{}".format(model_path))
else:
print("测试模式")
# 测试载入参数
saver.restore(sess, model_path)
print("从{}载入模型".format(model_path))
# label和名称的对照关系
label_name_dict = {
0: "人类",
1: "沙滩",
2: "建筑",
3: "公交",
4: "恐龙",
5: "大象",
6: "花朵",
7: "野马",
8: "雪山",
9: "美食"
}
# 定义输入和Label以填充容器 测试时dropout为0
test_feed_dict = {
xs: x_val,
ys: y_val,
drop: 0
}
# 真实label与模型预测label
predicted_labels_val = sess.run(predicted_labels, feed_dict=test_feed_dict)
for fpath, real_label, predicted_label in zip(fpaths_test, y_val, predicted_labels_val):
# 将label id转换为label名
real_label_name = label_name_dict[real_label]
predicted_label_name = label_name_dict[predicted_label]
print("{}\t{} => {}".format(fpath, real_label_name, predicted_label_name))
# 评价结果
print("正确预测个数:", sum(y_val==predicted_labels_val))
print("准确度为:", 1.0*sum(y_val==predicted_labels_val) / len(y_val))6.完整代码及实验结果
完整代码如下所示,这里参考了王诗爷老师的部分代码,强烈推荐大家学习他的博客。地址:https://blog.csdn.net/wills798
"""
Created on Sun Dec 29 19:21:08 2019
@author: xiuzhang Eastmount CSDN
"""
import os
import glob
import cv2
import numpy as np
import tensorflow as tf
# 定义图片路径
path = 'photo/'
#---------------------------------第一步 读取图像-----------------------------------
def read_img(path):
cate = [path + x for x in os.listdir(path) if os.path.isdir(path + x)]
imgs = []
labels = []
fpath = []
for idx, folder in enumerate(cate):
# 遍历整个目录判断每个文件是不是符合
for im in glob.glob(folder + '/*.jpg'):
#print('reading the images:%s' % (im))
img = cv2.imread(im) #调用opencv库读取像素点
img = cv2.resize(img, (32, 32)) #图像像素大小一致
imgs.append(img) #图像数据
labels.append(idx) #图像类标
fpath.append(path+im) #图像路径名
#print(path+im, idx)
return np.asarray(fpath, np.string_), np.asarray(imgs, np.float32), np.asarray(labels, np.int32)
# 读取图像
fpaths, data, label = read_img(path)
print(data.shape) # (1000, 256, 256, 3)
# 计算有多少类图片
num_classes = len(set(label))
print(num_classes)
# 生成等差数列随机调整图像顺序
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
fpaths = fpaths[arr]
# 拆分训练集和测试集 80%训练集 20%测试集
ratio = 0.8
s = np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
fpaths_train = fpaths[:s]
x_val = data[s:]
y_val = label[s:]
fpaths_test = fpaths[s:]
print(len(x_train),len(y_train),len(x_val),len(y_val)) #800 800 200 200
print(y_val)
#---------------------------------第二步 建立神经网络-----------------------------------
# 定义Placeholder
xs = tf.placeholder(tf.float32, [None, 32, 32, 3]) #每张图片32*32*3个点
ys = tf.placeholder(tf.int32, [None]) #每个样本有1个输出
# 存放DropOut参数的容器
drop = tf.placeholder(tf.float32) #训练时为0.25 测试时为0
# 定义卷积层 conv0
conv0 = tf.layers.conv2d(xs, 20, 5, activation=tf.nn.relu) #20个卷积核 卷积核大小为5 Relu激活
# 定义max-pooling层 pool0
pool0 = tf.layers.max_pooling2d(conv0, [2, 2], [2, 2]) #pooling窗口为2x2 步长为2x2
print("Layer0:\n", conv0, pool0)
# 定义卷积层 conv1
conv1 = tf.layers.conv2d(pool0, 40, 4, activation=tf.nn.relu) #40个卷积核 卷积核大小为4 Relu激活
# 定义max-pooling层 pool1
pool1 = tf.layers.max_pooling2d(conv1, [2, 2], [2, 2]) #pooling窗口为2x2 步长为2x2
print("Layer1:\n", conv1, pool1)
# 将3维特征转换为1维向量
flatten = tf.layers.flatten(pool1)
# 全连接层 转换为长度为400的特征向量
fc = tf.layers.dense(flatten, 400, activation=tf.nn.relu)
print("Layer2:\n", fc)
# 加上DropOut防止过拟合
dropout_fc = tf.layers.dropout(fc, drop)
# 未激活的输出层
logits = tf.layers.dense(dropout_fc, num_classes)
print("Output:\n", logits)
# 定义输出结果
predicted_labels = tf.arg_max(logits, 1)
#---------------------------------第三步 定义损失函数和优化器---------------------------------
# 利用交叉熵定义损失
losses = tf.nn.softmax_cross_entropy_with_logits(
labels = tf.one_hot(ys, num_classes), #将input转化为one-hot类型数据输出
logits = logits)
# 平均损失
mean_loss = tf.reduce_mean(losses)
# 定义优化器 学习效率设置为0.0001
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(losses)
#------------------------------------第四步 模型训练和预测-----------------------------------
# 用于保存和载入模型
saver = tf.train.Saver()
# 训练或预测
train = False
# 模型文件路径
model_path = "model/image_model"
with tf.Session() as sess:
if train:
print("训练模式")
# 训练初始化参数
sess.run(tf.global_variables_initializer())
# 定义输入和Label以填充容器 训练时dropout为0.25
train_feed_dict = {
xs: x_train,
ys: y_train,
drop: 0.25
}
# 训练学习1000次
for step in range(1000):
_, mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=train_feed_dict)
if step % 50 == 0: #每隔50次输出一次结果
print("step = {}\t mean loss = {}".format(step, mean_loss_val))
# 保存模型
saver.save(sess, model_path)
print("训练结束,保存模型到{}".format(model_path))
else:
print("测试模式")
# 测试载入参数
saver.restore(sess, model_path)
print("从{}载入模型".format(model_path))
# label和名称的对照关系
label_name_dict = {
0: "人类",
1: "沙滩",
2: "建筑",
3: "公交",
4: "恐龙",
5: "大象",
6: "花朵",
7: "野马",
8: "雪山",
9: "美食"
}
# 定义输入和Label以填充容器 测试时dropout为0
test_feed_dict = {
xs: x_val,
ys: y_val,
drop: 0
}
# 真实label与模型预测label
predicted_labels_val = sess.run(predicted_labels, feed_dict=test_feed_dict)
for fpath, real_label, predicted_label in zip(fpaths_test, y_val, predicted_labels_val):
# 将label id转换为label名
real_label_name = label_name_dict[real_label]
predicted_label_name = label_name_dict[predicted_label]
print("{}\t{} => {}".format(fpath, real_label_name, predicted_label_name))
# 评价结果
print("正确预测个数:", sum(y_val==predicted_labels_val))
print("准确度为:", 1.0*sum(y_val==predicted_labels_val) / len(y_val))训练输出结果如下所示:
(1000, 32, 32, 3)
10
800 800 200 200
[2 8 6 9 9 5 2 2 9 3 7 0 6 0 0 1 3 2 7 3 4 6 9 5 8 6 4 1 1 4 4 8 6 2 6 1 2
5 0 7 9 5 2 4 6 8 7 5 8 1 6 5 1 4 8 1 9 1 8 8 6 1 0 5 3 3 1 2 9 1 8 7 6 0
8 1 8 0 2 1 3 5 3 6 9 8 7 5 2 5 2 8 8 8 4 2 2 4 3 5 3 3 9 1 1 5 2 6 7 6 7
0 7 4 1 7 2 9 4 0 3 8 7 5 3 8 1 9 3 6 8 0 0 1 7 7 9 5 4 0 3 0 4 5 7 2 2 3
0 8 2 0 2 3 5 1 7 2 1 6 5 8 1 4 6 6 8 6 5 5 1 7 2 8 7 1 3 9 7 1 3 6 0 8 7
5 8 0 1 2 7 9 6 2 4 7 7 2 8 0]
Layer0:
Tensor("conv2d_1/Relu:0", shape=(?, 28, 28, 20), dtype=float32)
Tensor("max_pooling2d_1/MaxPool:0", shape=(?, 14, 14, 20), dtype=float32)
Layer1:
Tensor("conv2d_2/Relu:0", shape=(?, 11, 11, 40), dtype=float32)
Tensor("max_pooling2d_2/MaxPool:0", shape=(?, 5, 5, 40), dtype=float32)
Layer2:
Tensor("dense_1/Relu:0", shape=(?, 400), dtype=float32)
Output:
Tensor("dense_2/BiasAdd:0", shape=(?, 10), dtype=float32)
训练模式
step = 0 mean loss = 66.93688201904297
step = 50 mean loss = 3.376957654953003
step = 100 mean loss = 0.5910811424255371
step = 150 mean loss = 0.061084795743227005
step = 200 mean loss = 0.013018212281167507
step = 250 mean loss = 0.006795921362936497
step = 300 mean loss = 0.004505819175392389
step = 350 mean loss = 0.0032660639844834805
step = 400 mean loss = 0.0024683878291398287
step = 450 mean loss = 0.0019308131886646152
step = 500 mean loss = 0.001541870180517435
step = 550 mean loss = 0.0012695763725787401
step = 600 mean loss = 0.0010685999877750874
step = 650 mean loss = 0.0009132082923315465
step = 700 mean loss = 0.0007910516578704119
step = 750 mean loss = 0.0006900889566168189
step = 800 mean loss = 0.0006068988586775959
step = 850 mean loss = 0.0005381597438827157
step = 900 mean loss = 0.0004809059901162982
step = 950 mean loss = 0.0004320790758356452
训练结束,保存模型到model/image_model预测输出结果如下图所示,最终预测正确181张图片,准确度为0.905。相比之前机器学习KNN的0.500有非常高的提升。
测试模式
INFO:tensorflow:Restoring parameters from model/image_model
从model/image_model载入模型
b'photo/photo/3\\335.jpg' 公交 => 公交
b'photo/photo/1\\129.jpg' 沙滩 => 沙滩
b'photo/photo/7\\740.jpg' 野马 => 野马
b'photo/photo/5\\564.jpg' 大象 => 大象
...
b'photo/photo/9\\974.jpg' 美食 => 美食
b'photo/photo/2\\220.jpg' 建筑 => 公交
b'photo/photo/9\\912.jpg' 美食 => 美食
b'photo/photo/4\\459.jpg' 恐龙 => 恐龙
b'photo/photo/5\\525.jpg' 大象 => 大象
b'photo/photo/0\\44.jpg' 人类 => 人类
正确预测个数: 181
准确度为: 0.905四.总结
写到这里,这篇文章就讲解完毕,更多TensorFlow深度学习文章会继续分享,同时实验评价、RNN、LSTM、各专业的案例都会进行深入讲解。最后,希望这篇基础性文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!
参考文献:
[1] 冈萨雷斯著. 数字图像处理(第3版)[M]. 北京:电子工业出版社,2013.
[2] 杨秀璋, 颜娜. Python网络数据爬取及分析从入门到精通(分析篇)[M]. 北京:北京航天航空大学出版社, 2018.
[3] 罗子江等. Python中的图像处理[M]. 科学出版社,
2020.
[4] [python数据挖掘课程] 二十.KNN最近邻分类算法分析详解及平衡秤TXT数据集读取
[5] TensorFlow【极简】CNN - Yellow_python大神
[6] 基于深度神经网络的定向激活功能开发相位信息的声源定位 - 章子雎Kevin
[7] TensorFlow实战:Chapter-5(CNN-3-经典卷积神经网络(GoogleNet)) - DFann
[8] https://github.com/siucaan/CNN_MNIST
[9] 图像处理讲解-以CNN对图像进行分类为例 - 冰机灵
[10] 基于CNN的图像缺陷分类 - BellaVita1
[12] tensorflow(六)训练分类自己的图片(CNN超详细入门版)- Missayaa
[13] 详解tensorflow训练自己的数据集实现CNN图像分类 - 王诗爷 (强推)
[14] https://github.com/hujunxianligong/Tensorflow-CNN-Tutorial
[15] tensorflow(三):用CNN进行图像分类 - flowrush
[16] TensorFlow图像识别(物体分类)入门教程 - cococok2
[17] https://github.com/calssion/Fun_AI
[18] CNN图片分类 - 火舞_流沙
[19] CNN图片单标签分类(基于TensorFlow实现基础VGG16网络)
[20] https://github.com/siucaan/CNN_MNIST/blob/master/cnn_mnist_TF.py
[21] Tensorflow实现CNN用于MNIST识别 - siucaan (强推)
[22] 使用Anaconda3安装tensorflow,opencv,使其可以在spyder中运行

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步