【万字干货】OpenMetric与时序数据库存储模型分析
摘要:解读OpenMetric规范和指标的模型定义基础上,结合当下主流的时序数据库核心存储及处理技术,尝试让用户(架构师、开发者或使用者)结合自身业务场景选择合适的产品,消除技术选型的困惑。
本文分享自华为云社区《【万字干货】OpenMetric与时序数据库存储模型分析》,作者: 敏捷的小智。
摘要
近些年时序数据库发展突飞猛进,IT系统的监控指标就是一种典型的时序数据。由于云计算、容器、微服务和Serverless的普遍采用和业务系统的大型化、复杂化;加之IoT的蓬勃发展,海量时序数据的采集、存储、处理与分析,面临着全新的需求与挑战。在解读OpenMetric规范和指标的模型定义基础上,结合当下主流的时序数据库核心存储及处理技术,尝试让用户(架构师、开发者或使用者)结合自身业务场景选择合适的产品,消除技术选型的困惑。结合云服务商的最新动态,为用户提供开箱即用的、高可靠的多种可选方案,加速应用构建及可运维能力的完善,聚焦核心业务,促进业务成功。
背景
参考DB-ENGINES网站[1]关于各大数据库排名,是数据库产品选型的一个重要参考指标。尤其是针对不同业务场景和诉求,在垂直细分领域中关注那些评分和排名靠前的数据库产品。比如,根据DB-Engines按数据库类别的调查统计和评分图表(如下图1)显示:在最近的2年里,时序数据库(TSDB)位居增长最快的数据库类型榜首,尤其是最近一年时间里,更是一骑绝尘!
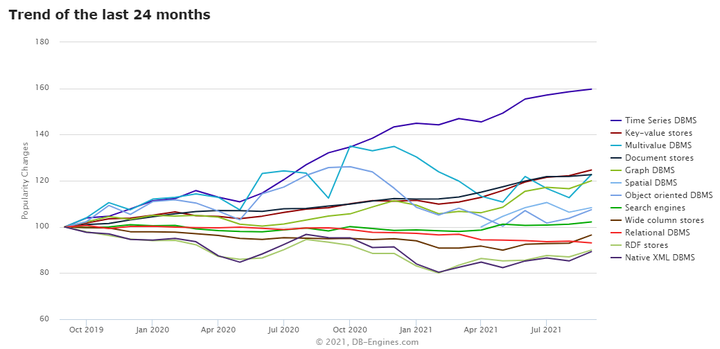
图1
从DB-Engines关于TSDB的评分趋势图(如下图2)来看,主流的TSDB包括了InfluxDB、Prometheus、TimescaleDB、Apache Druid、OpenTSDB等等。
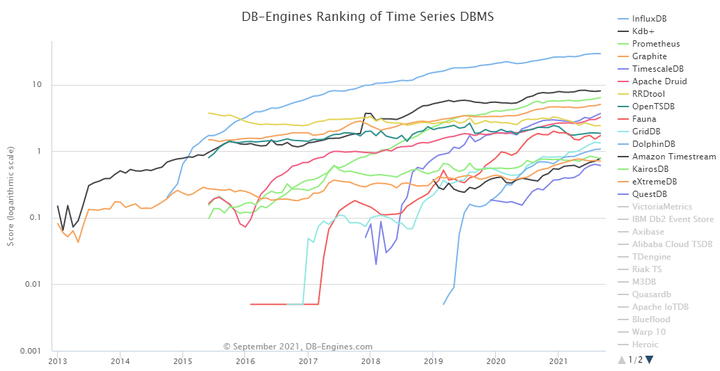
图2
事实上,业界流行的ClickHouse、Apache IoTDB等也属于时序数据库范畴。本文从应用运维场景,对众多的TSDB做个初步分析和筛选出典型代表产品,方便后面进行针对性的对比分析。
- InfluxDB:排名第一,社区火热和国内外采用厂商比较多。
- Prometheus:属于CNCF基金会第二个毕业的项目,在社区中比较火爆,甚至在容器领域形成事实的监控缺省方案。在国内外被普遍采用。
- TimescaleDB: 基于优秀的PostgreSQL构建出的时序数据库。长远考虑,专业的TSDB必须是从底层存储面向时序数据的特征进行针对性设计和优化的。因此它不在本文中进一步分析。
- Apache Druid:非常有名的实时OLAP分析平台,面向时序数据设计的,在极致性能和数据schema的灵活性方面有一定的平衡。类似的产品还有Pinot、Kylin等。
- OpenTSDB:基于HBase构建的时序数据库,依赖Hadoop生态太重,早期和InfluxDB并驾齐驱;近年来在社区中的热度已经远远落后于InfluxDB了。它还不支持多维查询。因此,它也排除在外。
- ClickHouse:俄罗斯Yandex开发的数据分析数据库(OLAP),但它可以充当TSDB来使用。本文不做深入分析。
- IoTDB:国内清华大学开源的时序数据库,面向工业IoT场景;性能出众,社区活跃。
结合国内用户和社区热度情况,本文挑选出具有代表性的InfluxDB、Prometheus、Druid、和IoTDB来进一步分析它们的存储核心。
运维域的时序数据的特性:
• 不可变性(Immutable)
• 实时性(realtime),历史越久远的数据,其潜在价值越小。一方面是流式写入,一方面是近实时查询或即时分析。
• 海量(Volumne)某直播平台,高速实时写入2000万/s; 需要结构化的数据多达200TB/d。如果考虑云服务厂商的某些逻辑多租的时序数据库应用,对峰值写入和峰值查询有更高的要求。
• 高压缩率:数据量太大直接影响到存储成本,所以高性能数据压缩是必备特性。
时序数据模型
在本文展开之前,先罗列出一些专业术语,以方便统一认知。说实话,就是数据库或者运维领域的专业人士,也经常被各种中文翻译搞得一头雾水。为了减少歧义性,本文习惯性地在一些关键词后面备注一下对应的原英文术语,以方便大家理解。
基本概念
Time series(时间序列,简称时序或者时序数据):根据wiki百科[2],其数学定义是这样:In mathematics, a time series is a series of data points indexed (or listed or graphed) in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time. Thus it is a sequence of discrete-time data. 翻译过来的要点就是 1)源于数学学科; 2)是按时间顺序索引的一系列数据点。因此也多翻译为“时序数据”。3)最常见的是在连续的相等间隔时间点上获取的序列。4)是一个离散时间的数据序列。
Metric(指标):在软件领域,Metric是对软件或其规格的某些属性的度量。在wiki百科中有这样的阐述:software metric[3]是衡量软件系统或过程具有某种属性的程度的标准。尽管学术界最初认为Metric是函数(function),Measurement是通过应用metric获得的数值;但随着计算机学科和传统学科的借鉴融合,这两个术语通常也用作同义词,泛指同一个东西了。
二者的关系:简单地讲,带有时间戳的很多metric放在一起就构成了一个Time series。
时序数据一般有以下几个显著特点:
• 每条数据必然自带时间戳,数据以时间排序
• 不可变性(immutable):一旦写入,基本不做修改或单条删除。(因为老化过期可以做删除)
• 数据量大,一般要求支持PB级别。同时也要求高吞吐能力。
• 高效的存储压缩效率,降低成本
• 时序最核心的用途在于数据分析,包括降采样、数据插值和空间聚合计算等
• 时序的唯一性:某一个时刻的某个指标只有一条数据(或点),即时出现多条数据也会被认为是同一条数据(或点)
• 单条数据并不重要
OpenMetrics规范
OpenMetrics[4]:一种云原生、高度可扩展的指标协议。它定义了大规模上报云原生指标的事实标准,同时支持文本表示协议和Protocol Buffers协议。虽然时间序列可以支持任意字符串或二进制数据,但RFC只针对和包括数字数据。得益于Prometheus的流行,作为Prometheus的监控数据采集方案,OpenMetrics可能很快会成为未来监控的业界标准。
目前绝大部分热门开源服务均有官方或非官方的exporter可供使用。实施者必须以 OpenMetrics 文本格式公开指标,以响应对给定进程或设备的文档化 URL 的简单 HTTP GET 请求。这个端点应该被称为“/metrics”。实施者还可以通过其他方式公开 OpenMetrics 格式的指标,例如通过 HTTP 定期将指标集推送到操作员配置的端点。
备注:事件(Event)与指标相反,单一事件发生在特定时刻;而指标是个时间序列。这个概念在运维域非常重要。
数据模型
- OpenMetrics对数据模型[5]有如下的定义:
- 度量值(value):它必须是浮点数或整数。
- 时间戳(timestamp):必须是以秒为单位的 Unix Epoch。
- 字符串(string):必须仅由有效的 UTF-8 字符组成
- 标签(Label):由字符串组成的键值对。以下划线开头的标签名称是保留的,一般不得使用。
- 标签集(LabelSet):它必须由标签组成并且可以为空。标签名称在标签集中必须是唯一的。
- 指标点(MetricPoint):每个MetricPoint 由一组值组成,具体取决于 MetricFamily 类型。MetricPoints 不应该有明确的时间戳。
- 指标(metric):由 MetricFamily 中的唯一 LabelSet 定义。Metrics 必须包含一个或多个 MetricPoints 的列表。给定 MetricFamily 具有相同名称的度量标准应该在它们的 LabelSet 中具有相同的标签名称集。如果为一个 Metric 公开了多个 MetricPoint,则其 MetricPoint 必须具有单调递增的时间戳。
- 指标家族(又译作“指标系列”, MetricFamily):一个 MetricFamily 可以有零个或多个指标。MetricFamily 必须具有名称、HELP、TYPE 和 UNIT 元数据。MetricFamily 中的每个 Metric 都必须有一个唯一的 LabelSet。
MetricFamily 名称是一个字符串,并且在 MetricSet 中必须是唯一的。
后缀:OpenMetrics定义了文本格式样例度量名称使用的后缀(不同数据类型的后缀有所不同)有:
计数器Counter:'_total','_created'
摘要Summary:'_count'、'_sum'、'_created'
直方图Histogram:'_count'、'_sum'、'_bucket'、'_created'
GaugeHistogram: '_gcount', '_gsum', '_bucket'
信息Info:'_info'
类型指定 MetricFamily 类型。有效值有8种指标类型(参考后文)。 - 指标集(MetricSet):是 OpenMetrics 公开的顶级对象。它必须由 MetricFamilies 组成。每个 MetricFamily 名称必须是唯一的。相同的标签名称和值不应出现在 MetricSet 中的每个 Metric 上。MetricSet 中不需要特定的 MetricFamilies 排序。
尽管OpenMetric对一些概念定义得比较琐碎和细致,甚至晦涩难懂;但从大逻辑思路上看,它仍然包括了时间戳、指标、标签以及基础数据类型几个方面,基本符合大家的日常思路。
指标类型(Metric Type)
OpenMetrics规范定义了8种指标类型:
Gauge(仪表读数,中文翻译不准确):它是当前的测量值,例如当前CPU的利用率或者内存字节数大小。对于Gauge,用户(我们)感兴趣的是其绝对值。通俗地讲,Gauge类型的指标就像我们汽车仪表盘中的指针所对应的当前数值(有增有减或者不动,因此是可变的;数值是大于零的)。Metric 中类型为 Gauge 的 MetricPoint 必须是单个值(相对于仪表盘指针不可能同时指到多个刻度位置)。
Counter(计数器):它是计量离散事件的。MetricPoint 必须具有一个称为 Total 的值。Total必须从 0 开始随时间单调非递减。一般而言,用户感兴趣的主要是Counter随时间增加的速度。
StateSet(状态集):StateSet 表示一系列相关的布尔值,也称为位集。StateSet 度量的一个点可能包含多个状态,并且每个状态必须包含一个布尔值。状态有一个字符串名称。
Info(信息指标):信息指标用于公开在流程生命周期内不应更改的文本信息。常见示例是应用程序的版本、修订控制提交和编译器的版本。信息可用于编码其值不随时间变化的 ENUM,例如网络接口的类型。
Histogram(直方图):直方图测量离散事件的分布。常见示例是 HTTP 请求的延迟、函数运行时或 I/O 请求大小。直方图 MetricPoint 必须至少包含一个桶,并且应该包含 Sum 和 Created 值。每个桶必须有一个阈值和一个值。
GaugeHistogram(仪表直方图):测量当前分布。常见的例子是项目在队列中等待的时间,或者队列中请求的大小。
Summary(摘要):Summary测量离散事件的分布,并且可以在直方图计算过于昂贵或平均事件大小足够时使用。包含 Count 或 Sum 值的类型为 Summary 的 Metric 中的 MetricPoint 应该具有名为 Created 的 Timestamp 值。这可以帮助摄取者区分新的指标和之前没有看到的长期运行的指标。
Unknown(未知):当无法确定来自 3rd 方系统的单个指标的类型时,可以使用未知。一般情况下不能使用。
通俗地讲,histogram用于表示一段时间内对数据的采样,按照指定的时间间隔及总数进行统计。它是需要按照统计区间进行计算的。而Summary用于表示一段时间内数据采样结果,直接存储分位数(quantile)数据,不需要计算。本质上Summary是与histogram类似的。更多详细情况可以参考官方文档[6]。
基于标签(tag-value)的时序数据模型
当前主流TSDB的时序数据模型都是以标签(tag,也称label)为主来唯一确定一个时间序列(一般也附加上指标名称、时间戳等)。
Prometheus时序数据模型
本文从CNCF社区最流行的Prometheus监控系统来分析时序数据的建模。Prometheus采用了多维数据模型,包含指标名称(metric name)、一个或多个标签(labels,与tags意义相同)以及指标数值(metric value)。
时序数据模型包括了metric name、一个或多个labels(同tags)以及metric value。metric name加一组labels作为唯一标识,来定义time series,也就是时间线。
Prometheus的指标模型定义如下:
<metric name>{<label name>=<label value>, ...}
指标名称(metric name):表示了被测系统的一般特征,即一个可以度量的指标。它采用一个通用普遍的名称来描述一个时间序列的,比如sys.cpu.user、 stock.quote、 env.probe.temp和http_requests_total, 其中http_requests_total可以表示请求接收到的HTTP的总数。
标签(label):由Prometheus 的维度数据模型来支撑实现。相同指标名称的任何给定标签组合标识该指标的特定维度实例。更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列。因此通过标签可以让查询语言轻松实现过滤、分组和匹配。
样本(Sample):按照某个时序以时间维度采集的数据,称之为样本。实际的时间序列,每个序列包括一个float64的值和一个毫秒级的Unix时间戳。本质上属于单值模型。
单值模型的时间序列/时间线(time series): 具有相同指标名称和相同标签维度集合的带有时间戳数值的数据流。通俗地讲,就是用metric name加一组labels作为唯一标识,来定义时间线。
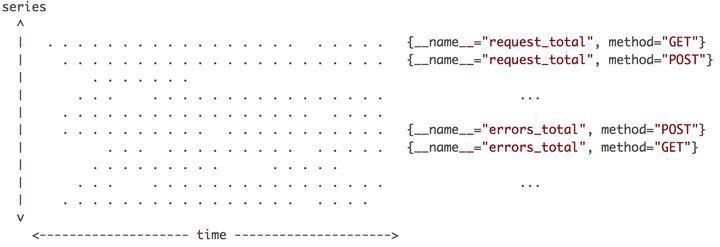
图3
上图3是某个时间段内的相关数据点的分布示意图[7],其中横轴是时间,纵轴是时间线,区域内每个点就是数据点。指标名称和一组标签唯一确定一条时间线(就是每条水平线)。在同一时刻,每条时间线只会产生一个数据点,但同时会有多条时间线产生数据,把这些数据点连在一起,就是一条竖线。因此,Prometheus每次接收数据,收到的是图中纵向的一条线。这些水平线和竖线的特征很重要,影响到数值插值,以及数据写入和压缩的优化策略。
InfluxDB时序数据模型
下图4是InfluxDB对时序数据模型的图形化表示:

图4
measurement:
指标对象,也即一个数据源对象。每个measurement可以拥有一个或多个指标值,也即下文所述的field。在实际运用中,可以把一个现实中被检测的对象(如:“cpu”)定义为一个measurement。measurement是fields,tags以及time列的容器,measurement的名字用于描述存储在其中的字段数据,类似mysql的表名。
tags:
概念等同于大多数时序数据库中的tags, 通常通过tags可以唯一标示数据源。每个tag的key和value必须都是字符串。
field:
数据源记录的具体指标值。每一种指标被称作一个“field”,指标值就是 “field”对应的“value”。fields相当于SQL的没有索引的列。
timestamp:
数据的时间戳。在InfluxDB中,理论上时间戳可以精确到 纳秒(ns)级别
每个Measurement内的数据,从逻辑上来讲,会组织成一张大的数据表(如下图5)。Tag用于描述Measurement,而Field用于描述Value。从内部实现来上看,Tag会被全索引,而Filed不会。
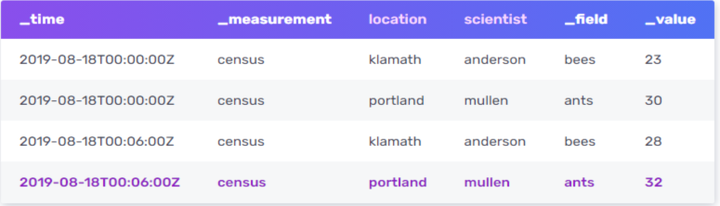
图5
多值模型下的时间线(Series):在讨论Series之前,先看看一个series key的定义:共享measurement,标记集合和field key的数据点的集合。它是InfluxDB的核心概念之一。比如上图中,census,location=klamath,scientist=anderson bees构成一个series key。因此上图中有2个series key。而Series就是针对给定的series key对应的时间戳和字段值。比如上图中,series key为census,location=klamath,scientist=anderson bees的series就是:
2019-08-18T00:00:00Z 23
2019-08-18T00:06:00Z 28
所以,InfluxDB中的series key可以理解为我们通常所说的时间线(或者时间线的key),而series就是时间线所包含的值(相当于数据点)。二者都泛指TSDB中的时间序列/时间线,只是从key-value对的角度进行了逻辑概念区分。
小结:如下图6所示,时序数据一般分为两部分,一个是标识符(指标名称、标签或维度),方便搜索与过滤;一个是数据点,包括时间戳和度量数值。数值主要是用作计算,一般不建索引。从数据点包含数值的多少,可以分为单值模型(比如Prometheus)和多值模型(比如InfluxDB);从数据点存储方式来看,有行存储和列存储之分。一般情况下,列存能有更好的压缩率和查询性能。
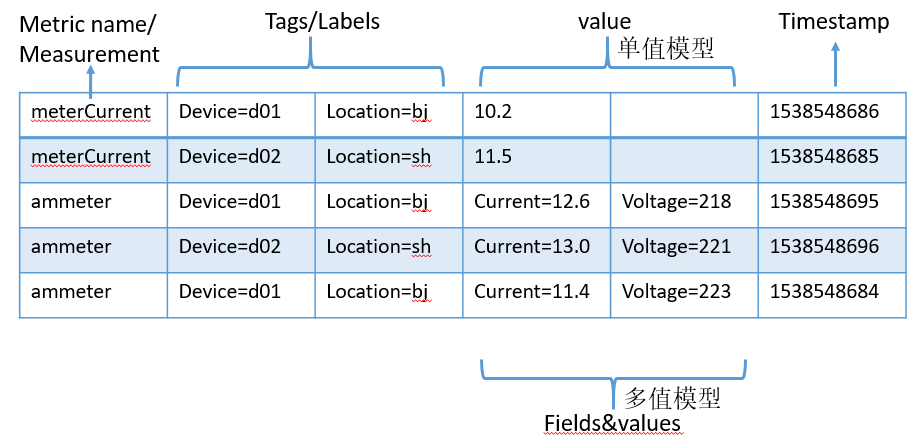
图6
基于树形(tree schema)的时序数据模型
IoTDB与其他TSDB的数据模型最大的不同,没有采用标签(tag-value、Labels)模式,而是采用树形结构定义数据模式:以root为根节点、把存储组、设备、传感器串联在一起的树形结构,从root根节点经过存储组、设备到传感器叶子节点,构成了一条路径(Path)。一条路径就可以命名一个时间序列,层次间以“.”连接。如下图7所示[8]:
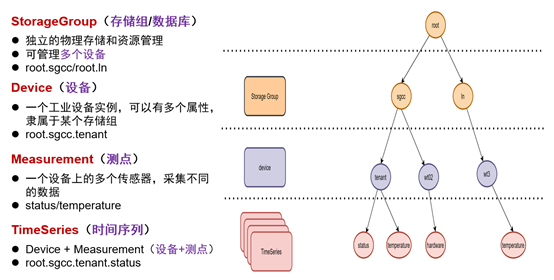
图7
数据点(Data point):一个“时间-值”对。
时间序列(一个实体的某个物理量对应一个时间序列,Timeseries,也称测点 meter、时间线 timeline,实时数据库中常被称作标签 tag、参数 parameter):一个物理实体的某个物理量在时间轴上的记录,是数据点的序列。类似于关系数据库中的一张表,不过这张表主要有时间戳(Timestamp)、设备ID(Device ID)、测点值(Measurement)三个主要字段;另外还增加了Tag和Field等扩展字段,其中Tag支持索引,Field不支持索引。
IoTDB这种基于树的模式(tree schema)和其它TSDB很不一样,有以下优点:
- 设备管理是层次化的:比如许多工业场景里设备管理不是扁平的,而是有层次的。其实在应用软件体系中也是类似的场景,比如CMDB就维护着软件组件或资源之间的一种层次关系。所以IoTDB认为基于tree schema 比基于 tag-value schema更合适IoT场景。
- 标签及其值的相对不变性:在大量实际应用中,标签的名字及其对应的数值是不变的。例如:风力发电机制造商总是用风机所在的国家、所属的风场以及在风场中的 ID 来标识一个风机,因此,一个 4 层高的树(“root.the-country-name.the-farm-name.the-id”)就能表示清楚,而且很简洁;一定程度减少了数据模式的重复描述。
- 灵活查询:基于路径的时间序列 ID 定义,比较方便灵活的查询,例如:”root.*.a.b.*“,其中、*是一个通配符。
各TSDB的概念对比
首先从RDB视角来对比映射主流TSDB的基本概念,以方便大家理解。
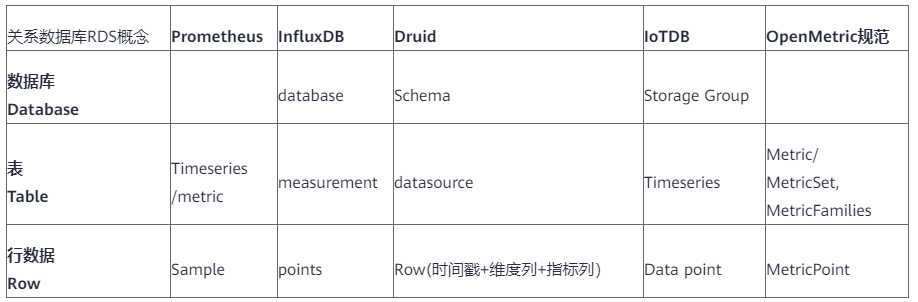
表1
从上面表1可以看出,database逻辑概念更多地体现了一种数据schema定义,方便数据的逻辑组织划分(比如InfluxDB的database)、管理(比如Druid的3种schema定义)和存储(比如IoTDB的storage group)。另外OpenMetric属于指标规范,更多地体现关于数据点的定义和逻辑细节的管理(比如MetricSet、MetricFamilies、MetricPoint、LabelSet等,搞得很细也很复杂)。
其次,我们从时序数据集中的每个数据点或者一行数据的角度来分析,以下图8为例。
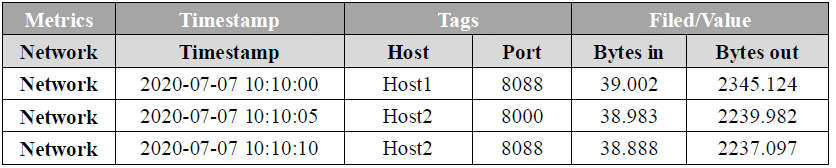
图8
时序数据的基本模型可以分成下面几个部分:
Metric:度量的数据集,类似于关系型数据库中的 table,是固定属性,一般不随时间而变化
Timestamp:时间戳,表征采集到数据的时间点
Tags:维度列,用于描述Metric,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化
Field/Value:指标列,代表数据的测量值,可以是单值也可以是多值
围绕上述时序数据模型,我们对比看看各种TSDB中基本概念的对应关系,如下表2所示:
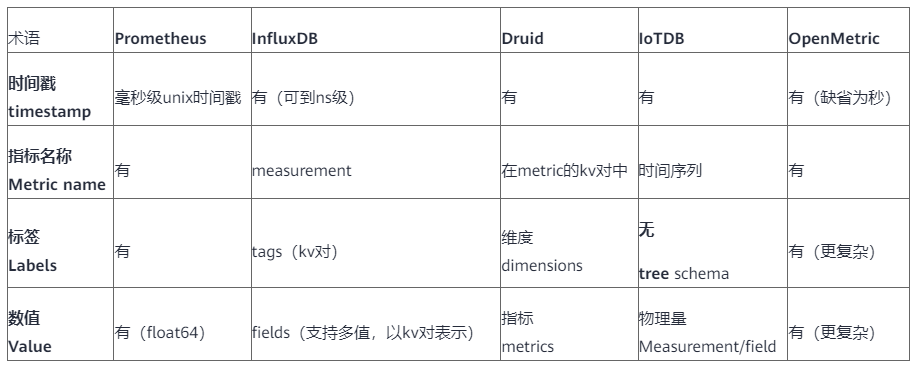
表2
OpenMetric是关于指标的社区规范,还在持续演变中,还每正式成为IETF标准的一部分。当前看,它的建模过于细节(从而概念之间交叉模糊,不易理解)。反而是TSDB经过多年的实践,关于时序数据的模型抽象更直接和高效。
参考资料
[1] https://db-engines.com/en/
[2] https://en.wikipedia.org/wiki/Time_series
[3] https://en.wikipedia.org/wiki/Software_metric
[4] https://openmetrics.io/
[5] https://github.com/OpenObservability/OpenMetrics/blob/main/specification/OpenMetrics.md
[6] https://prometheus.io/docs/practices/histograms/
[7] Fabian Reinartz, https://fabxc.org/tsdb/
[8] https://bbs.huaweicloud.com/blogs/280943

 浙公网安备 33010602011771号
浙公网安备 33010602011771号