
解读顶会CIKM'21 Historical Inertia论文
摘要:本文(Historical Inertia: An Ignored but Powerful Baseline for Long Sequence Time-series Forecasting)是由华为云数据库创新Lab联合电子科技大学数据与智能实验室发表在顶会CIKM’21的短文,该文章提出了一种针对长时间序列的baseline。
本文分享自华为云社区《CIKM'21 Historical Inertia论文解读》,作者: 云数据库创新Lab 。
导读
本文(Historical Inertia: An Ignored but Powerful Baseline for Long Sequence Time-series Forecasting)是由华为云数据库创新Lab联合电子科技大学数据与智能实验室发表在顶会CIKM’21的短文,该文章提出了一种针对长时间序列的baseline。CIKM是信息检索和数据挖掘领域顶级学术会议之一。本届会议共收到短文投稿626篇,其中录用论文177篇,录取率约为28% 。该论文是云数据库创新LAB在时序分析层面取得的关键技术成果之一。
1 摘要
长序列时间序列预测(Long Sequence Time-series Forecasting,LSTF)因其广泛的应用而变得越来越流行。虽然人们已经提出了大量复杂模型来提高预测的有效性和效率,但却忽视或低估了时间序列一个最自然、最基本的特性:历史存在惯性。在本文中,我们提出了一个新的LSTF基线,即历史惯性(Historical Inertia, HI)。在此基线模型中, 我们直接将输入时间序列中距离预测目标最近的历史数据点作为预测值。我们在4个公开LSTF数据集,2个LSTF任务上评估了HI的效果,结果表明,与SOTA工作相比,HI可以获得高达82%的相对提高。同时,我们也讨论了HI和现有方法结合的可能性。
2 HI
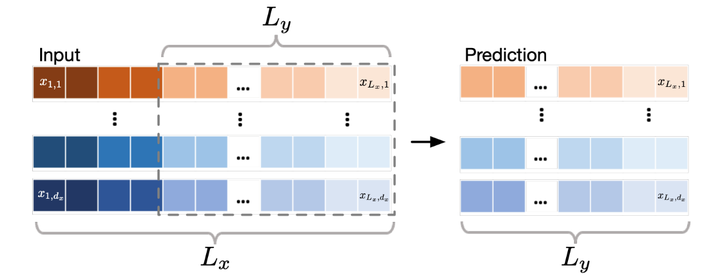
HI直接将输入时间序列中距离预测目标最近的历史数据点作为预测值。
3 实验
3.1 单变量长时间序列预测结果

对于单变量长时间序列预测任务,HI在ETTh1和ETTm1数据集上显著优于SOTA模型。Informer及其变体主导了ETTh2数据集的最优结果。而对于Electricity数据集,HI,Informer和DeepAR都有较好的表现。整体来看,HI在MSE和MAE上分别实现了高达80%和58%的相对提高。
3.2 多变量长时间序列预测结果
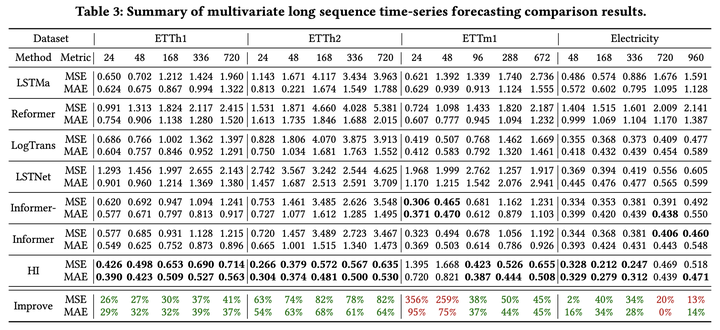
对于多变量长时间序列预测任务,HI在四个数据集的绝大多数预测任务上都显著优于SOTA模型,最高带来了82%的相对提高。
4 讨论
4.1 为什么HI会有如此好的效果
我们从两个角度考虑了HI能取得良好效果的原因:
- 数值 :HI可以保证预测序列与真实序列有相似的数值大小。
- 周期性:对于有周期性且周期性较短的数据集,HI可以做到预测序列与真实序列相位相似。
4.2 如何利用HI
我们提出了两种利用HI的可能方向
- 融合模型(Hybrid model):可以考虑将HI与其他模型融合,例如简单的作为一种trick将输出结果加权平均。
- 自动机器学习(AutoML):某些情况下复杂模型可能并不能达到良好效果,因此可以考虑根据数据自适应模型结构,适当地降低/增加模型复杂度。
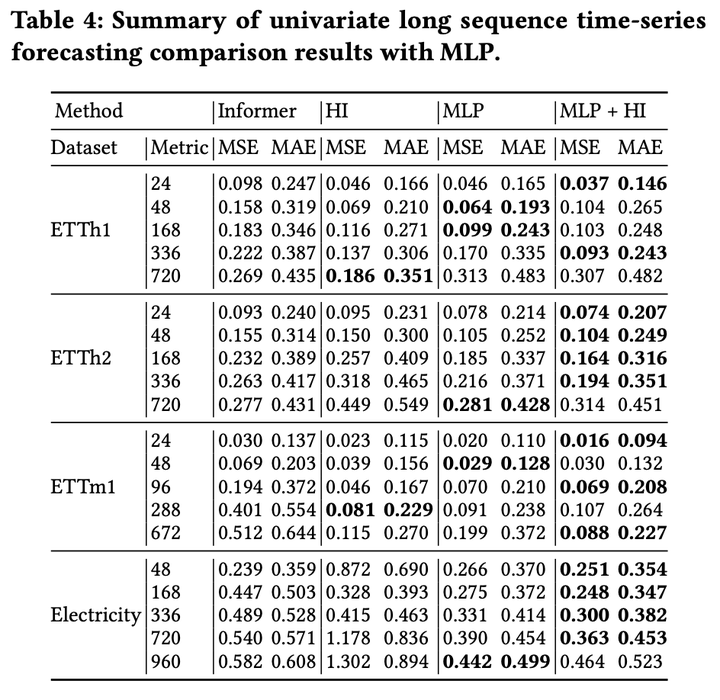
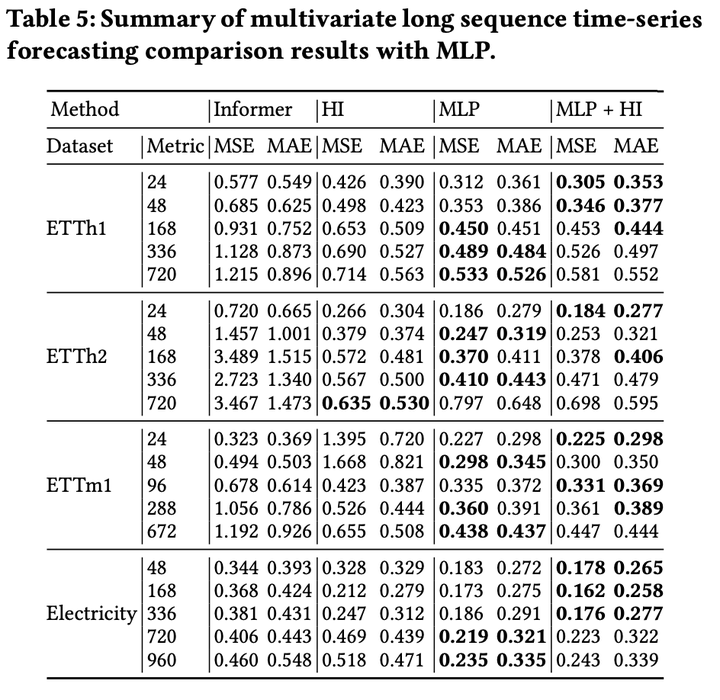
对于融合模型这一方向,我们设计了简单的实验予以验证:将HI与2层MLP模型的输出结果取平均得到最终预测结果。实验结果表明,融合HI的MLP模型可实现更准确的预测,并且此优势在单变量长时间序列预测任务上更显著。
华为云数据库创新lab官网:https://www.huaweicloud.com/lab/clouddb/home.html

