

工商银行:应用多k8s集群管理及容灾实践
摘要:在华为开发者大会(Cloud)2021上,工商银行Paas云平台架构师沈一帆发表了《工商银行多k8s集群管理及容灾实践》主题演讲,分享了工商银行使用多云容器编排引擎Karmada的落地实践过程。
本文分享自华为云社区《Karmada | 工商银行多k8s集群管理及容灾实践》,原文作者:技术火炬手。
在华为开发者大会(Cloud)2021上,工商银行Paas云平台架构师沈一帆发表了《工商银行多k8s集群管理及容灾实践》主题演讲,分享了工商银行使用多云容器编排引擎Karmada的落地实践过程。

演讲主要包含4个方面的内容:
- 1)工行云平台现状
- 2)业界多集群管理方案及选型
- 3)为什么选择Karmada?
- 4)落地情况及未来展望
工行云计算的业务背景
近几年互联网的崛起,对金融行业的金融模式及服务模式都产生了巨大的冲击,这令我们不得不做出一些巨大的革新。同时从现在的角度来看,银行业务系统入云已是大势所趋,截止目前,工商银行已形成了以基础设施云、应用平台云、金融生态云以及比较有工行特色的分行云4个模块,组成了我们整体的云平台架构。

工商银行云平台的整体架构
工行云平台技术栈
采用了业界比较领先的云产品和主流开源技术,在此基础上结合了我们一些金融的业务场景,进行了深度化定制。

- 基础设施云:基于华为云Stack8.0产品结合运营运维需求进行客户化定制,构建新一代基础设施云。
- 应用平台云:通过引入开源容器技术Docker、容器集群调度技术Kubernetes等,自主研发建设应用平台云。
- 上层应用方案:基于HaProxy、Dubbo、ElasticSerch等建立负载均衡、微服务、全息监控、日志中心等周边配套云生态。
工行金融云成效
在容器云方面,工行的金融云成效也是非常大的,首先体现在它的入云规模大,截至目前应用平台云容器规模超20万,业务容器占到55,000个左右,整体的一些核心业务都已入容器云内部。除了在同业的入云规模最大之外,我们的业务场景涉及非常广泛,一些核心的应用,核心的银行业务系统,包括个人金融体系的账户,快捷支付、线上渠道、纪念币预约等,这些核心的业务应用也已容器化部署;另外,我们的一些核心技术支撑类应用如MySQL,还有一些中间件以及微服务框架,这一类核心支撑类应用也已入云;此外,一些新技术领域,包括物联网、人工智能、大数据等。
当越来越多的核心业务应用入云之后,对我们最大的挑战是容灾以及高可用,在这方面我们也做了很多实践:
1)云平台支持多层次故障保护机制,确保同一业务的不同实例会均衡分发到两地三中心的不同资源域,确保单个存储、单个集群甚至单个数据中心发生故障时,不会影响业务的整体可用性。
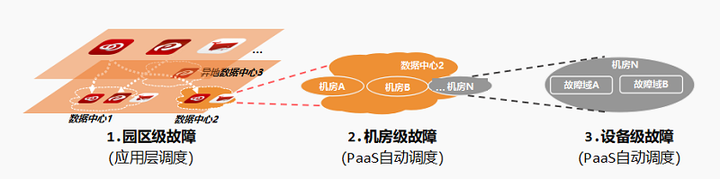
2)在故障情况下,云平台通过容器重启及自动漂移,实现故障的自动恢复。

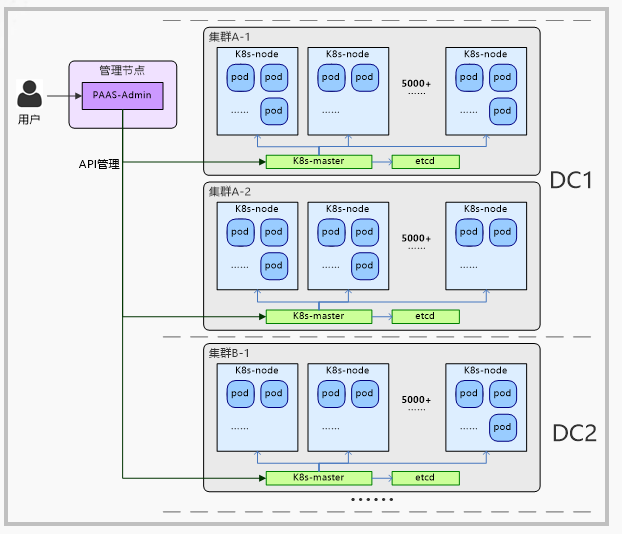
在整体容器云实践下,我们也遇到了一些问题,其中比较突出的是 pass层容器层的多集群的现状。现在工行内部整体的k8s总数,k8s集群的总数已近百个,主要的原因有4个:
1)集群种类多:刚刚也说了我们的业务场景非常的广泛,比如GPU要有不同支持GPU的设备,一些中间件,数据库它对底层的网络容器存储的需求是不同的,那势必会产生不同的解决方案,因此我们需要为不同的业务场景定制不同集群。
2)受到k8s本身性能的限制,包括scheduler、 etcd 、API server等一些性能瓶颈,每一个集群也有它数量的上限。
3)业务扩展非常快。
4)故障域分区多,我们两地三中心的架构至少有三个DC,每个DC内部还有不同的网络区域,通过防火墙进行隔离, 这样的倍乘关系,中间就会产生很多集群故障域的分布。
基于以上4点,针对当前的现状,我们现有的解决方案还是依靠容器云的云管平台,通过云管平台管理这些多k8s集群,另外上层的业务应用需要自主选择它的集群,包括它需要的偏好、网络、区域等,去选择它具体的某一个k8s集群。在选择到k8s集群之后,我们内部是通过故障率进行自动打散的调度。
但现有的解决方案对上层应用还是暴露出非常多的问题:
1)对上层应用来说,它可能上了容器云比较关心的一个部分,就是我们具有在业务峰值的过程中自动伸缩的能力,但自动伸缩现在只是在集群内部,没有整体的跨集群自动伸缩的能力。
2)无跨集群自动调度能力,包括调度的能力可能都是在集群内部,应用需要自主的选择具体的集群
3)集群对上层用户不透明
4)无跨集群故障自动迁移能力。我们还是主要依靠两地三中心架构上副本的冗余,那么在故障恢复的自动化恢复过程中,这一块的高可用能力是有缺失的。
业界多集群管理方案及选型
基于目前的现状,我们定下了一些目标,对业界的一些方案进行整体的技术选型,总共分为5个模块:
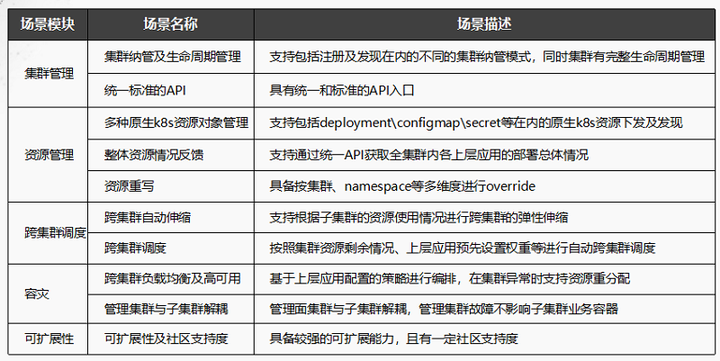
为什么希望它是一个具有一定社区支持度的开源项目,主要是三点的考虑:
- 1)希望整体方案是企业内部自主可控的,这点也是开源的一大益处
- 2)不希望花费更多的能力
- 3)为什么不把调度以及故障恢复的能力全部集成到刚刚的云管平台。这部分是我们希望整体的多集群管理模块,从云管平台中隔离出来,下沉到下面的一个多集群管理模块。
基于以上这些目标,我们进行社区解决方案的一些调研。
Kubefed
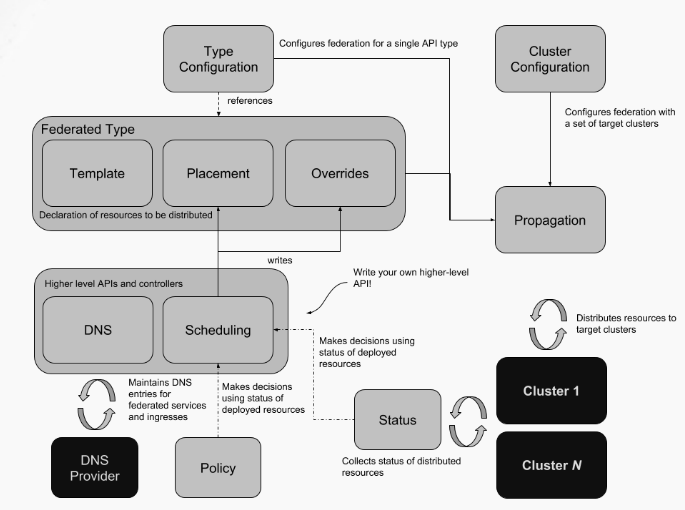
我们调研的第一个是之前比较火的一个集群联邦federation项目, federation整体是分v1和v2的版本,我们去调研的时候,那个时候已经主要是v2也就是Kubefed。
Kubefed本身也能解决一部分问题,它具有集群生命周期管理、Override以及基础调度的能力,但对我们来说它有几点致命的硬伤,目前还无法满足我们的需求:
1)调度层面是非常基础的一个调度能力,他们也不准备在调度方面花费更大的精力支持自定义调度,不支持按资源余量调度。
2)第二点也是比较为人所诟病的,它本身不支持原生k8s对象,我要在它的管理集群中使用它新定义的CRD,对于我们已经使用了这么久的k8s原生资源对象的上层应用,云管平台本身对接API方面,我们也需要重新进行开发,这部分成本是非常大的。
3)它基本不具备故障自动迁移能力
RHACM
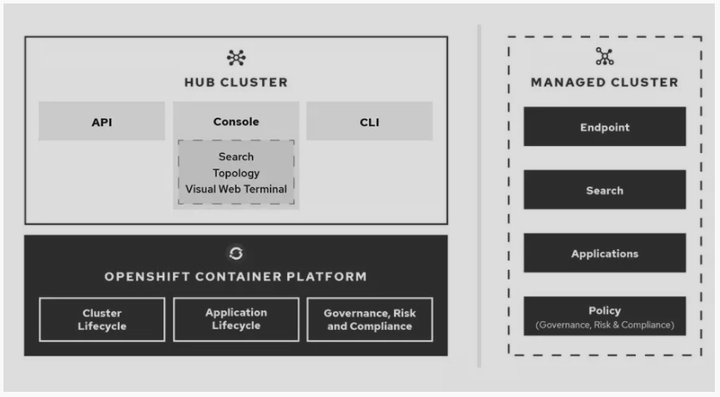
我们调研的第二个项目是RHACM,该项目主要由红帽和 IBM主导,整体调研下来,发现它的功能是比较健全的,包括我们刚刚所提的能力也是具备的,而且它上层应用application层对于对用户那一层的能力比较靠近云管平台这样一个定位,但它仅仅支持Openshift,对于我们已经存量有这么多的k8s集群来说,改造成本非常大,而且太重了。而在我们进行研究的时候,它还没有开源,社区的整体支持力度是不够的。
Karmada
当时我们和华为交流到了多集群管理的一个现状以及痛点,包括对社区联邦类项目的讨论,我们双方也非常希望能够在这方面革新,下图为Karmada的功能视图:
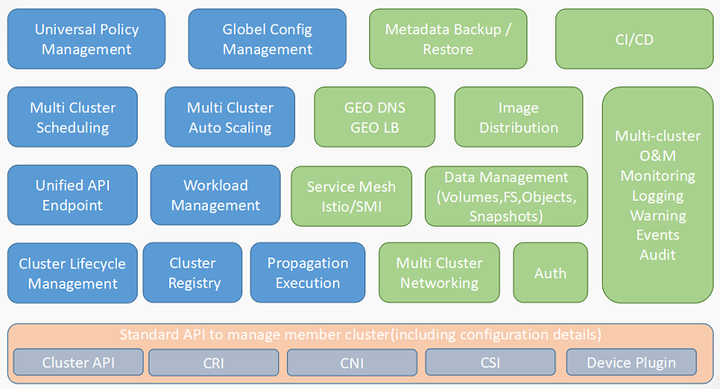
Karmada功能视图
从它整体功能视图及规划来看,和我们上文提到的目标非常契合,它有集群整体的生命周期管理、集群注册、多集群伸缩、多集群调度、整体统一的API、底层标准API支持,它都是CNI/CSI在它整体功能视图里,包括上层的应用、对Istio、Mash、CI/CD等都有整体规划上的考虑。因此基于整体思路,它的功能与我们非常契合,工行也决定投入到这个项目中来,跟华为和我们很多的项目伙伴共建Karmada项目,并把它回馈到我们社区整体。
为什么选择Karmada
技术架构
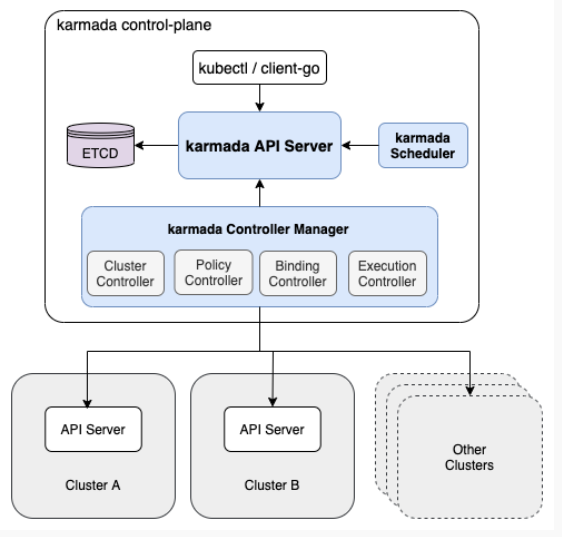
在我个人的理解上,它有以下优势:
1)Karmada以类k8s的形式部署,它有API Server、Controller Manager等,对我们已经拥有存量那么多k8s集群的企业来说,改造成本是比较小的,我们只需在上面部署一个管理集群即可
2)Karmada-Controller-Manager管理包括cluster、policy、binding、works等多种CRD资源作为管理端资源对象,但是它没有侵入到原生的我们想要部署的那些k8s原生资源对象。
3)Karmada仅管理资源在集群间的调度,子集群内分配高度自治
Karmada整体的Resources是如何进行分发的?
- 第一步,集群注册到Karmada
- 第二步,定义Resource Template
- 第三步,制定分发策略Propagation Policy
- 第四步,制定Override策略
- 第五步,看Karmada干活
下图为整体的下发流程:
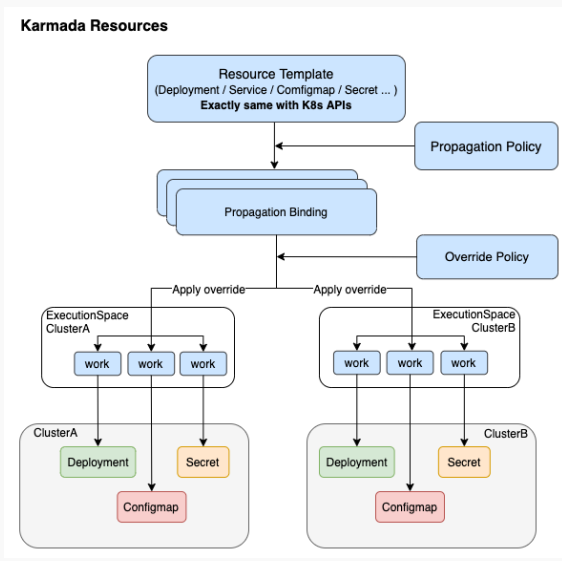
当我们定义了deployment之后,它通过 Propagation Policy进行匹配,然后它就会产生一个绑定关系,就是Propagation Binding,然后再通过一个 override的一个policy,就产生了每一个works。这个works其实就是在子集群中各个资源对象的一个封装。在这里我觉得比较重要的是propagation以及workers机制。
Propagation机制
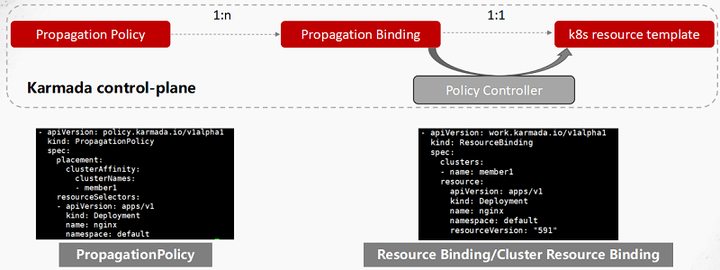
首先我们定义的是 Propagation的Policy,可以看到整体yaml得话,我们先定了一个比较简单的策略,选择了一个cluster,它叫member 1; 第二个就是我需要这条策略到底匹配哪些K8s resource template,它匹配的是我们定义了一个namespace为default的nginx deployment。它除了支持Cluster的亲和性之外,还支持集群容忍,按集群标签、故障域分发。
当定义完Propagation Policy之后,之前定义的想要下发的K8s resource template会自动跟它进行匹配,匹配之后,deployment会被分发到比如说ABC三个集群,这样就跟ABC三个集群产生了绑定,这个绑定关系就是Resource Bindding。
Resource Bindding整体的yaml可能就是你选择的一个cluster,在这里就是member 1这样一个cluster,现在整个Resource Bindding是支持cluster和namespace两种级别的,这两种级别相当于对应了不同的场景,namespace级别是当一个集群内部是用namespace做租户隔离时,可能Resource Bindding用的namespace的 scope。还有一个cluster场景,就是整个子集群都是给一个人用的,给一个租户用的,我们直接用Cluster Resource Bindding绑定即可。
Work机制
在我们已经建立了Propagation Bindding之后,那work是怎么进行分发的?
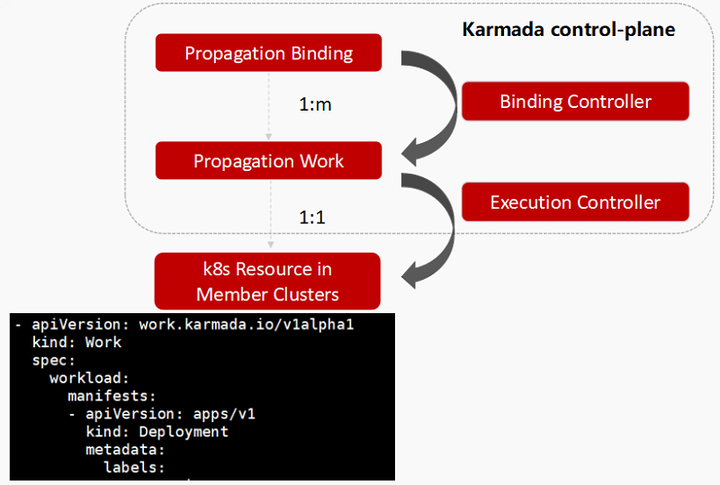
当Propagation Bindding产生了之后,比如产生了ABC三个集群,这里的1:m就是指这三个集群。找到这三个集群之后,Bindding Controller就会工作,然后去产生基于 resource template以及你的绑定关系,去产生具体的works对象,works对象整体就是具体的子集群中resource的封装,那么同时 works 的一个status有一个子集群resource的反馈,可以看到整个work yaml,可以看到manifests下面就是整体的一个子集群,具体已经override过,具体要分发到子集群里面的整体的一个deployment yaml都在这里了,所以说它只是一个resource的封装。
Karmada优势
工行在具体使用与验证之后,发现Karmada有以下几点优势:
1)资源调度
- 自定义跨集群调度策略
- 对上层应用透明
- 支持两种资源绑定调度
2)容灾
- 动态binding调整
- 按照集群标签或故障域自动分发资源对象
3)集群管理
- 支持集群注册
- 全生命周期管理
- 统一标准的API
4)资源管理
- 支持k8s原生对象
- works支持子集群资源部署状态获取
- 资源对象分发既支持pull也支持push方式
Karmada在工行的落地情况及对未来展望
首先我们看下Karmada其中的两个功能怎么去纳管集群和资源下发?
目前为止工行的测试环境中Karmada已经对存量集群进行了一些纳管,在对未来规划方面,一个比较关键的点是如何跟我们整体云平台进行集成。
云平台集成
在这方面我们希望之前提到的多集群管理、跨集群调度、跨集群伸缩、故障恢复以及资源整体视图方面都全部下沉到Karmada这样一个控制平面。

对于上层的云管平台,我们更注重它对用户业务的管理,包括用户管理、应用管理、进项管理等,也包括由Karmada衍生出来的比如说Policy定义在云平台上。上图比较简略,具体的云平台可能还要连一根线到每一个k8s集群,比如pod在哪个node上,Karmada的平面可能是不关心的,但具体要知道pod位置类的信息,可能还要从k8s的子集群获取,这个也可能是我们后面集成中需要去解决的问题,当然这也是符合Karmada本身的设计理念,它是不需要关心具体的pod在k8s子集群的哪个位置。
未来展望1-跨集群调度
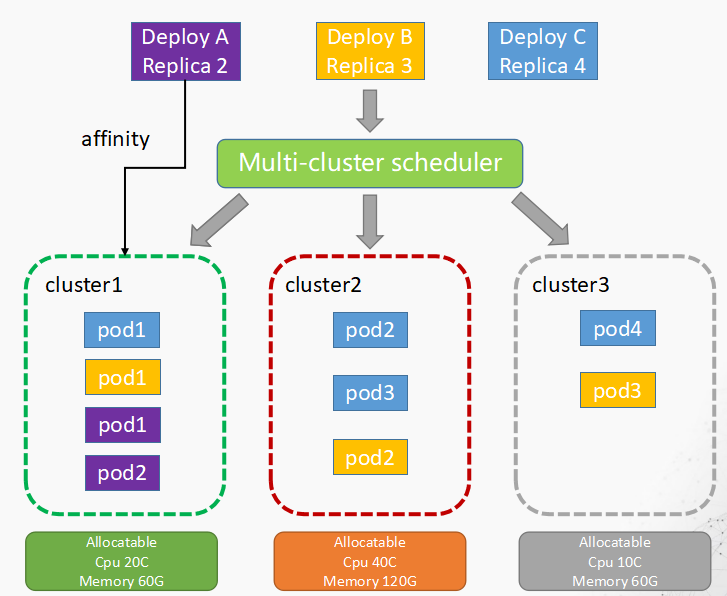
对于跨集群调度方面,Karmada已经支持了上文提到的故障域打算、应用偏好、权重对比。但是我们希望它也能够根据集群的资源与量去进行调度,这样不会产生各个子集群当中资源不均衡的状态。虽然它暂时是没有实现的,但它的一个CRD叫cluster, cluster有一个状态信息,这个状态信息里面会去收集node ready的状态, node上剩余的Allocatable,就是CPU内存的剩余信息。其实有了这些信息之后,我们再做自定义调度,完全是规划中的一个事情。
整体的调度设计完之后,我们希望在工行产生的效果如下图,当我调度 deployment A时,它是因为偏好的设置调度到cluster 1; deployment B因为一个故障域打散,它可能调度到了cluster 123三个集群;deployment C也是一个故障域打散,但是因为资源余量的原因,它多余的pod被调度到了cluster 2这样一个集群。
未来展望2-跨集群伸缩
跨集群伸缩现在也是在Karmada规划当中,现在我们可能还是需要解决一些问题:
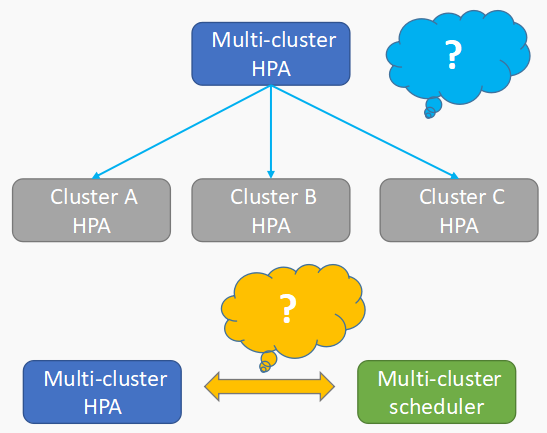
1)考虑它跨集群伸缩和子集群伸缩之间的关系,因为现在往往我们上层业务应用配置的是单个集群伸缩的策略,那么整体跨集群的策略与子集群伸缩策略都配置时,它们之间的关系,到底是上层整体去做管理,还是有优先级,这可能是我们后面需要考虑的。
2)跨集群伸缩和跨集群调度间的关系,我觉得整体上还是以一个调度器为准。我的一个Multi-cluster仅仅负责伸缩的部分,比如到达了多少CPU、多少的内存,比如说70% -80%的时候去进行伸缩,伸缩到多少个,具体的调度还是由整体scheduler去进行。
3)需要汇聚各个集群的metric,包括可能有一些性能瓶颈,它整体的工作模式,是需要我们后续去考虑的。
未来展望3-跨集群故障恢复及高可用
1)子集群健康状态的判断策略:可能只是与管理集群失联,子集群本身业务容器均无损
2)自定义的故障恢复策略:Like RestartPolicy,Always、Never、OnFailure
3)重新调度和跨集群伸缩的关系:希望它多集群的调度是整体的一个调度器,而伸缩控制好它自己伸缩的一个策略即可。
整体对我们工行的一些业务场景而言,Karmada现在的能力及以后的规划,可预见应该都是能解决我们业务场景痛点的。很高兴有机会能够加入到Karmada项目,希望有更多的开发者能够加入Karmada,与我们共建社区,共建这样一个多云管理的新项目。
附:Karmada社区技术交流地址
项目地址:https://github.com/karmada-io/karmada
Slack地址:https://karmada-io.slack.com
