解析分布式应用框架Ray架构源码
摘要:Ray的定位是分布式应用框架,主要目标是使能分布式应用的开发和运行。
Ray是UC Berkeley大学 RISE lab(前AMP lab) 2017年12月 开源的新一代分布式应用框架(刚发布的时候定位是高性能分布式计算框架,20年中修改定位为分布式应用框架),通过一套引擎解决复杂场景问题,通过动态计算及状态共享提高效率,实现研发、运行时、容灾一体化
Ray架构解析
业务目标
Ray的定位是分布式应用框架,主要目标是使能分布式应用的开发和运行。
业务场景
具体的粗粒度使用场景包括
- 弹性负载,比如Serverless Computing
- 机器学习训练,Ray Tune, RLlib, RaySGD提供的训练能力
- 在线服务, 例如Ray Server提供在线学习的案例
- 数据处理, 例如Modin, Dask-On-Ray, MARS-on-Ray
- 临时计算(例如,并行化Python应用程序,将不同的分布式框架粘合在一起)
Ray的API让开发者可以轻松的在单个分布式应用中组合多个libraries,例如,Ray的tasks和Actors可能会call into 或called from在Ray上运行的分布式训练(e.g. torch.distributed)或者在线服务负载; 在这种场景下,Ray是作为一个“分布式胶水”系统,因为它提供通用API接口并且性能足以支撑许多不同工作负载类型。
系统设计目标
- Ray架构设计的核心原则是API的简单性和通用性
- Ray的系统的核心目标是性能(低开销和水平可伸缩性)和可靠性。为了达成核心目标,设计过程中需要牺牲一些其他理想的目标,例如简化的系统架构。例如,Ray使用了分布式参考计数和分布式内存之类的组件,这些组件增加了体系结构的复杂性,但是对于性能和可靠性而言却是必需的。
- 为了提高性能,Ray建立在gRPC之上,并且在许多情况下可以达到或超过gRPC的原始性能。与单独使用gRPC相比,Ray使应用程序更容易利用并行和分布式执行以及分布式内存共享(通过共享内存对象存储)。
- 为了提高可靠性,Ray的内部协议旨在确保发生故障时的正确性,同时又减少了常见情况的开销。 Ray实施了分布式参考计数协议以确保内存安全,并提供了各种从故障中恢复的选项。
- 由于Ray使用抽象资源而不是机器来表示计算能力,因此Ray应用程序可以无缝的从便携机环境扩展到群集,而无需更改任何代码。 Ray通过分布式溢出调度程序和对象管理器实现了无缝扩展,而开销却很低。
相关系统上下文
- 集群管理系统:Ray可以在Kubernetes或SLURM之类的集群管理系统之上运行,以提供更轻量的task和Actor而不是容器和服务。
- 并行框架:与Python并行化框架(例如multiprocessing或Celery)相比,Ray提供了更通用,更高性能的API。 Ray系统还明确支持内存共享。
- 数据处理框架: 与Spark,Flink,MARS或Dask等数据处理框架相比,Ray提供了一个low-level且较简化的API。这使API更加灵活,更适合作为“分布式胶水”框架。另一方面,Ray对数据模式,关系表或流数据流没有内在的支持。仅通过库(例如Modin,Dask-on-Ray,MARS-on-Ray)提供此类功能。
- Actor框架:与诸如Erlang和Akka之类的专用actor框架不同,Ray与现有的编程语言集成,从而支持跨语言操作和语言本机库的使用。 Ray系统还透明地管理无状态计算的并行性,并明确支持参与者之间的内存共享。
- HPC系统:HPC系统都支持MPI消息传递接口,MPI是比task和actor更底层的接口。这可以使应用程序具有更大的灵活性,但是开发的复杂度加大了很多。这些系统和库中的许多(例如NCCL,MPI)也提供了优化的集体通信原语(例如allreduce)。 Ray应用程序可以通过初始化各组Ray Actor之间的通信组来利用此类原语(例如,就像RaySGD的torch distributed)。
系统设计
逻辑架构:
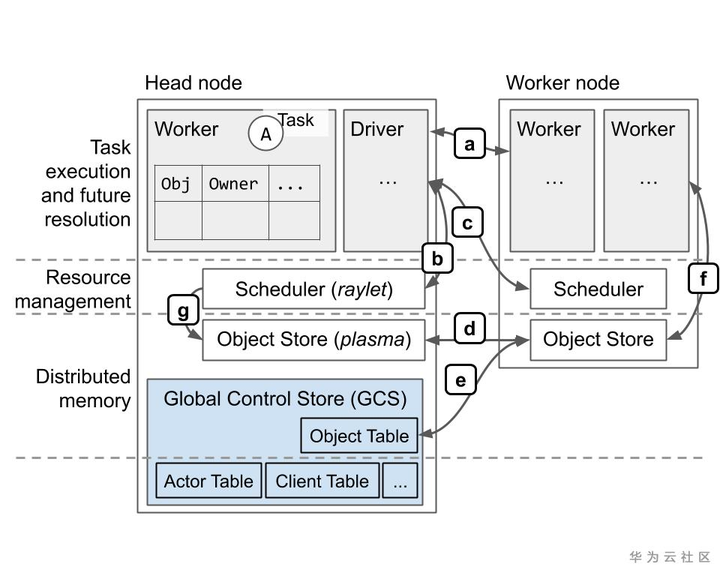
领域模型
- Task:在与调用者不同的进程上执行的单个函数调用。任务可以是无状态的(@ ray.remote函数)或有状态的(@ ray.remote类的方法-请参见下面的Actor)。任务与调用者异步执行:.remote()调用立即返回一个ObjectRef,可用于检索返回值。
- Object:应用程序值。这可以由任务返回,也可以通过ray.put创建。对象是不可变的:创建后就无法修改。工人可以使用ObjectRef引用对象。
- Actor:有状态的工作进程(@ ray.remote类的实例)。 Actor任务必须使用句柄或对Actor的特定实例的Python引用来提交。
- Driver: 程序根目录。这是运行ray.init()的代码。
- Job:源自同一驱动程序的(递归)任务,对象和参与者的集合
集群设计
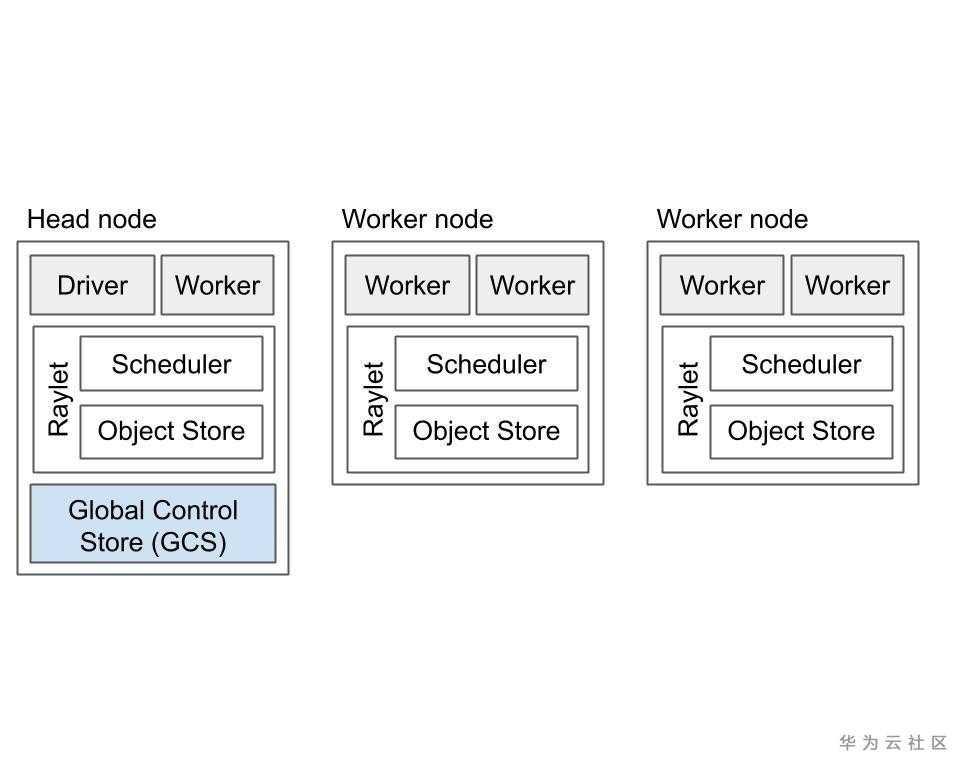
如上图所示,Ray集群包括一组同类的worker节点和一个集中的全局控制存储(GCS)实例。
部分系统元数据由GCS管理,GCS是基于可插拔数据存储的服务,这些元数据也由worker本地缓存,例如Actor的地址。 GCS管理的元数据访问频率较低,但可能被群集中的大多数或所有worker使用,例如,群集的当前节点成员身份。这是为了确保GCS性能对于应用程序性能影响不大。
Ownership
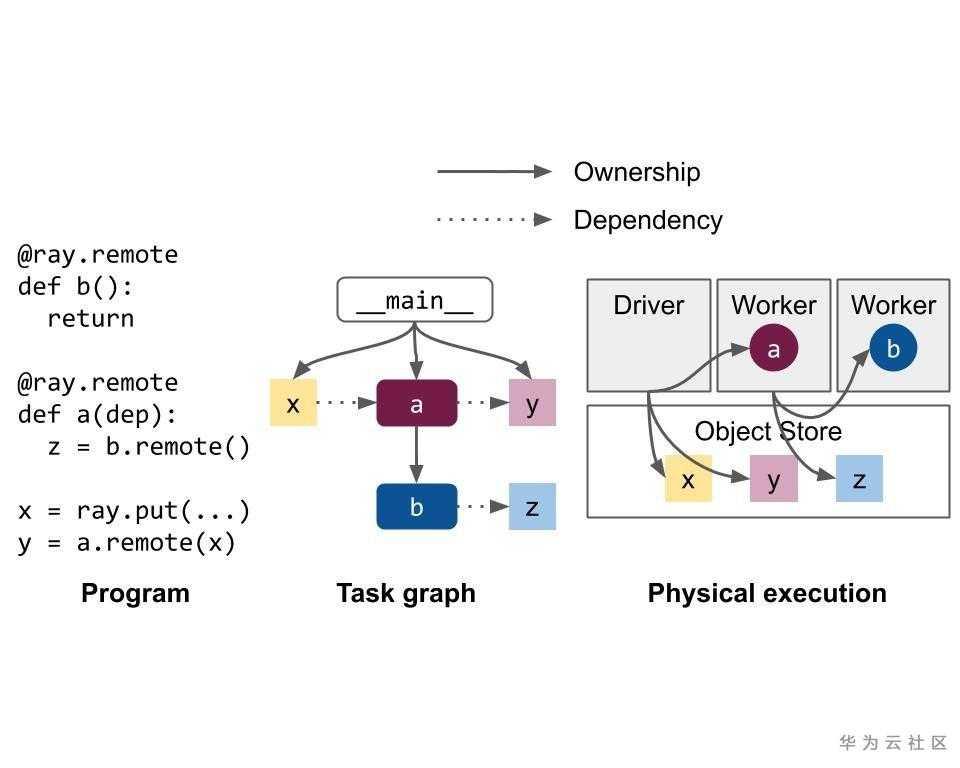
- 大部分系统元数据是根据去中心化理念(ownership)进行管理的:每个工作进程都管理和拥有它提交的任务以及这些任务返回的“ ObjectRef”。Owner负责确保任务的执行并促进将ObjectRef解析为其基础值。类似地,worker拥有通过“ ray.put”调用创建的任何对象。
- OwnerShip的设计具有以下优点(与Ray版本<0.8中使用的更集中的设计相比):
- 低任务延迟(〜1 RTT,<200us)。经常访问的系统元数据对于必须对其进行更新的过程而言是本地的。
- 高吞吐量(每个客户端约10k任务/秒;线性扩展到集群中数百万个任务/秒),因为系统元数据通过嵌套的远程函数调用自然分布在多个worker进程中。
- 简化的架构。owner集中了安全垃圾收集对象和系统元数据所需的逻辑。
- 提高了可靠性。可以根据应用程序结构将工作程序故障彼此隔离,例如,一个远程调用的故障不会影响另一个。
- OwnerShip附带的一些权衡取舍是:
- 要解析“ ObjectRef”,对象的owner必须是可及的。这意味着对象必须与其owner绑定。有关对象恢复和持久性的更多信息,请参见object故障和object溢出。
- 目前无法转让ownership。
核心组件
- Ray实例由一个或多个工作节点组成,每个工作节点由以下物理进程组成:
- 一个或多个工作进程,负责任务的提交和执行。工作进程要么是无状态的(可以执行任何@ray.remote函数),要么是Actor(只能根据其@ray.remote类执行方法)。每个worker进程都与特定的作业关联。初始工作线程的默认数量等于计算机上的CPU数量。每个worker存储ownership表和小对象:
a. Ownership 表。工作线程具有引用的对象的系统元数据,例如,用于存储引用计数。
b. in-process store,用于存储小对象。 - Raylet。raylet在同一群集上的所有作业之间共享。raylet有两个主线程:
a. 调度器。负责资源管理和满足存储在分布式对象存储中的任务参数。群集中的单个调度程序包括Ray分布式调度程序。
b. 共享内存对象存储(也称为Plasma Object Store)。负责存储和传输大型对象。集群中的单个对象存储包括Ray分布式对象存储。
每个工作进程和raylet都被分配了一个唯一的20字节标识符以及一个IP地址和端口。相同的地址和端口可以被后续组件重用(例如,如果以前的工作进程死亡),但唯一ID永远不会被重用(即,它们在进程死亡时被标记为墓碑)。工作进程与其本地raylet进程共享命运。
- 其中一个工作节点被指定为Head节点。除了上述进程外,Head节点还托管:
- 全局控制存储(GCS)。GCS是一个键值服务器,包含系统级元数据,如对象和参与者的位置。GCS目前还不支持高可用,后续版本中GCS可以在任何和多个节点上运行,而不是指定的头节点上运行。
- Driver进程(es)。Driver是一个特殊的工作进程,它执行顶级应用程序(例如,Python中的__main__)。它可以提交任务,但不能执行任何任务本身。Driver进程可以在任何节点上运行。
交互设计
应用的Driver可以通过以下方式之一连接到Ray:
- 调用`ray.init()’,没有参数。这将启动一个嵌入式单节点Ray实例,应用可以立即使用该实例。
- 通过指定ray.init(地址=<GCS addr>)连接到现有的Ray集群。在后端,Driver将以指定的地址连接到GCS,并查找群集其他组件的地址,例如其本地raylet地址。Driver必须与Ray群集的现有节点之一合部。这是因为Ray的共享内存功能,所以合部是必要的前提。
- 使用Ray客户端`ray.util.connect()'从远程计算机(例如笔记本电脑)连接。默认情况下,每个Ray群集都会在可以接收远程客户端连接的头节点上启动一个Ray Client Server,用来接收远程client连接。但是由于网络延迟,直接从客户端运行的某些操作可能会更慢。
Runtime
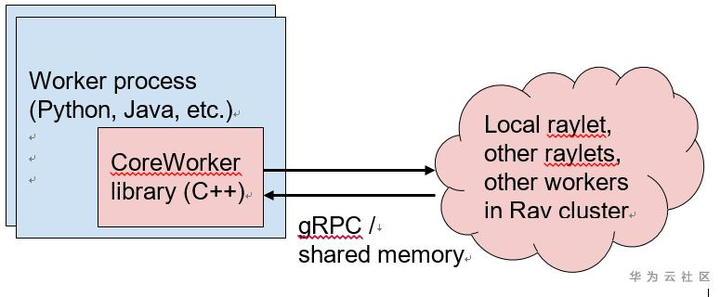
- 所有Ray核心组件都是用C++实现的。Ray通过一个名为“core worker”的通用嵌入式C++库支持Python和Java。此库实现ownership表、进程内存储,并管理与其他工作器和Raylet的gRPC通信。由于库是用C++实现的,所有语言运行时都共享Ray工作协议的通用高性能实现。
Task的lifetime
Owner负责确保提交的Task的执行,并促进将返回的ObjectRef解析为其基础值。如下图,提交Task的进程被视为结果的Owner,并负责从raylet获取资源以执行Task,Driver拥有A的结果,Worker 1拥有B的结果。
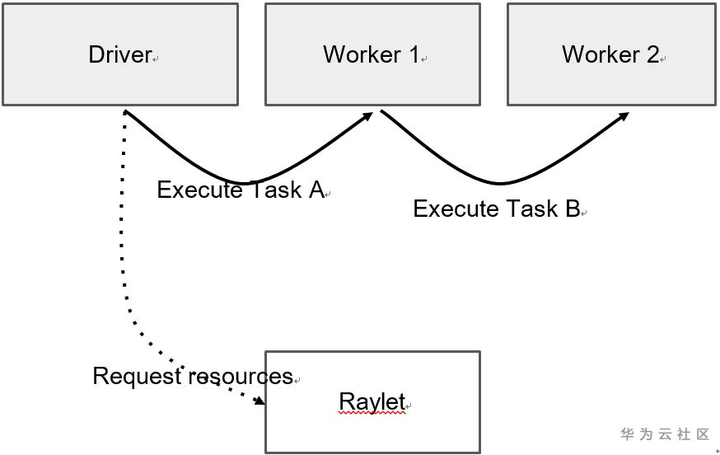
- 提交Task时,Owner会等待所有依赖项就绪,即作为参数传递给Task的ObjectRefs(请参见Object的lifetime)变得可用。依赖项不需要是本地的;Owner一旦认为依赖项在群集中的任何地方可用,就会立即就绪。当依赖关系就绪时,Owner从分布式调度程序请求资源以执行任务,一旦资源可用,调度程序就会授予请求,并使用分配给owner的worker的地址进行响应。
- Owner将task spec通过gRPC发送给租用的worker来调度任务。执行任务后,worker必须存储返回值。如果返回值较小,则工作线程将值直接inline返回给Owner,Owner将其复制到其进程中对象存储区。如果返回值很大,则worker将对象存储在其本地共享内存存储中,并向所有者返回分布式内存中的ref。让owner可以引用对象,不必将对象提取到其本地节点。
- 当Task以ObjectRef作为其参数提交时,必须在worker开始执行之前解析对象值。如果该值较小,则它将直接从所有者的进程中对象存储复制到任务说明中,在任务说明中,执行worker线程可以引用它。如果该值较大,则必须从分布式内存中提取对象,以便worker在其本地共享内存存储中具有副本。scheduler通过查找对象的位置并从其他节点请求副本来协调此对象传输。
- 容错:任务可能会以错误结束。Ray区分了两种类型的任务错误:
- 应用程序级。这是工作进程处于活动状态,但任务以错误结束的任何场景。例如,在Python中抛出IndexError的任务。
- 系统级。这是工作进程意外死亡的任何场景。例如,隔离故障的进程,或者如果工作程序的本地raylet死亡。
- 由于应用程序级错误而失败的任务永远不会重试。异常被捕获并存储为任务的返回值。由于系统级错误而失败的任务可以自动重试到指定的尝试次数。
- 代码参考:
- src/ray/core_worker/core_worker.cc
- src/ray/common/task/task_spec.h
- src/ray/core_worker/transport/direct_task_transport.cc
- src/ray/core_worker/transport/依赖关系_解析器.cc
- src/ray/core_worker/task_manager.cc
- src/ray/protobuf/common.proto
Object的lifetime
下图Ray中的分布式内存管理。worker可以创建和获取对象。owner负责确定对象何时安全释放。
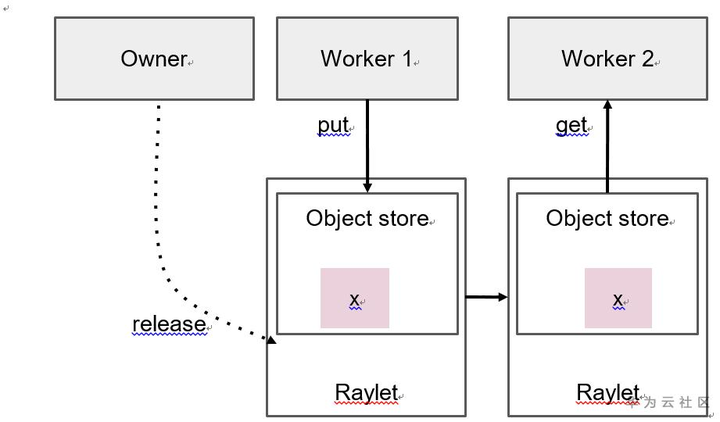
- 对象的owner就是通过提交创建task或调用ray.put创建初始ObjectRef的worker。owner管理对象的生存期。Ray保证,如果owner是活的,对象最终可能会被解析为其值(或者在worker失败的情况下引发错误)。如果owner已死亡,则获取对象值的尝试永远不会hang,但可能会引发异常,即使对象仍有物理副本。
- 每个worker存储其拥有的对象的引用计数。有关如何跟踪引用的详细信息,请参阅引用计数。Reference仅在下面两种操作期间计算:
1.将ObjectRef或包含ObjectRef的对象作为参数传递给Task。
2.从Task中返回ObjectRef或包含ObjectRef的对象。 - 对象可以存储在owner的进程内内存存储中,也可以存储在分布式对象存储中。此决定旨在减少每个对象的内存占用空间和解析时间。
- 当没有故障时,owner保证,只要对象仍在作用域中(非零引用计数),对象的至少一个副本最终将可用。。
- 有两种方法可以将ObjectRef解析为其值:
1.在ObjectRef上调用ray.get。
2.将ObjectRef作为参数传递给任务。执行工作程序将解析ObjectRefs,并将任务参数替换为解析的值。 - 当对象较小时,可以通过直接从owner的进程内存储中检索它来解析。大对象存储在分布式对象存储中,必须使用分布式协议解析。
- 当没有故障时,解析将保证最终成功(但可能会引发应用程序级异常,例如worker segfault)。如果存在故障,解析可能会引发系统级异常,但永远不会挂起。如果对象存储在分布式内存中,并且对象的所有副本都因raylet故障而丢失,则该对象可能会失败。Ray还提供了一个选项,可以通过重建自动恢复此类丢失的对象。如果对象的所有者进程死亡,对象也可能失败。
- 代码参考:
- src/ray/core_worker/store_Provider/memory_store/memory_store.cc
- src/ray/core_worker/store_Provider/plasma_store_provider.cc
- src/ray/core_worker/reference_count.cc
- src/ray/object_manager/object_manager.cc
Actor的lifetime
Actor的lifetimes和metadata (如IP和端口)是由GCS service管理的.每一个Actor的Client都会在本地缓存metadata,使用metadata通过gRPC将task发送给Actor.
如上图,与Task提交不同,Task提交完全分散并由Task Owner管理,Actor lifetime由GCS服务集中管理。
- 在Python中创建Actor时,worker首先同步向GCS注册Actor。这确保了在创建Actor之前,如果创建worker失败的情况下的正确性。一旦GCS响应,Actor创建过程的其余部分将是异步的。Worker进程在创建一个称为Actor创建Task的特殊Task队列。这与普通的非Actor任务类似,只是其指定的资源是在actor进程的生存期内获取的。创建者异步解析actor创建task的依赖关系,然后将其发送到要调度的GCS服务。同时,创建actor的Python调用立即返回一个“actor句柄”,即使actor创建任务尚未调度,也可以使用该句柄。
- Actor的任务执行与普通Task 类似:它们返回futures,通过gRPC直接提交给actor进程,在解析所有ObjectRef依赖关系之前,不会运行。和普通Task主要有两个区别:
- 执行Actor任务不需要从调度器获取资源。这是因为在计划其创建任务时,参与者已在其生命周期内获得资源。
- 对于Actor的每个调用者,任务的执行顺序与提交顺序相同。
- 当Actor的创建者退出时,或者群集中的作用域中没有更多挂起的任务或句柄时,将被清理。不过对于detached Actor来说不是这样的,因为detached actor被设计为可以通过名称引用的长Actor,必须使用ray.kill(no_restart=True)显式清理。
- Ray还支持async actor,这些Actor可以使用asyncio event loop并发运行任务。从调用者的角度来看,向这些actor提交任务与向常规actor提交任务相同。唯一的区别是,当task在actor上运行时,它将发布到在后台线程或线程池中运行的异步事件循环中,而不是直接在主线程上运行。
- 代码参考:
- Core worker源码: src/ray/core_worker/core_worker.h. 此代码是任务调度、Actor任务调度、进程内存储和内存管理中涉及的各种协议的主干。
- Python: python/ray/includes/libcoreworker.pxd
- Java: src/ray/core_worker/lib/java
- src/ray/core_worker/core_worker.cc
- src/ray/core_worker/transport/direct_actor_transport.cc
- src/ray/gcs/gcs_server/gcs_actor_manager.cc
- src/ray/gcs/gcs_server/gcs_actor_scheduler.cc
- src/ray/protobuf/core_worker.proto
本文分享自华为云社区《分布式应用框架Ray架构源码解析》,原文作者:Leo Xiao 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号