
几个小实践带你快速上手MindSpore
摘要:本文将带大家通过几个小实践快速上手MindSpore,其中包括MindSpore端边云统一格式及华为智慧终端背后的黑科技。
MindSpore介绍
MindSpore是一种适用于端边云场景的新型开源深度学习训练/推理框架。 MindSpore提供了友好的设计和高效的执行,旨在提升数据科学家和算法工程师的开发体验,并为Ascend AI处理器提供原生支持,以及软硬件协同优化。
同时,MindSpore作为全球AI开源社区,致力于进一步开发和丰富AI软硬件应用生态。
接下来我将带大家通过几个小实践快速上手MindSpore:
1.MindSpore端边云统一格式— — MindIR
2.华为智慧终端背后的黑科技— —超轻量AI引擎MindSpore Lite
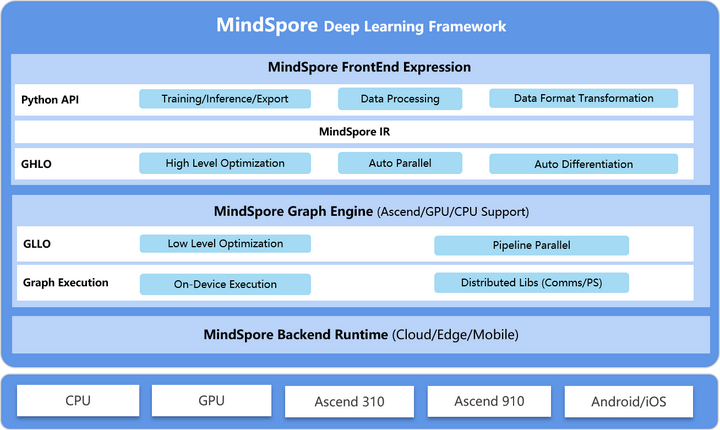
一、MindSpore端边云统一格式— — MindIR
MindIR • 全称MindSpore IR,是MindSpore的一种基于图表示的函数式IR,定义了可扩展的图 结构以及算子的IR表示。它消除了不同后端的模型差异,一般用于跨硬件平台执行推理任务。
(1)MindSpore通过统一IR定义了网络的逻辑结构和算子的属性,将MindIR格式的模型文件 与硬件平台解耦,实现一次训练多次部署。
(2)MindIR作为MindSpore的统一模型文件,同时存储了网络结构和权重参数值。同时支持 部署到云端Serving和端侧Lite平台执行推理任务。
(3)同一个MindIR文件支持多种硬件形态的部署:
- Serving部署推理
- 端侧Lite推理部署
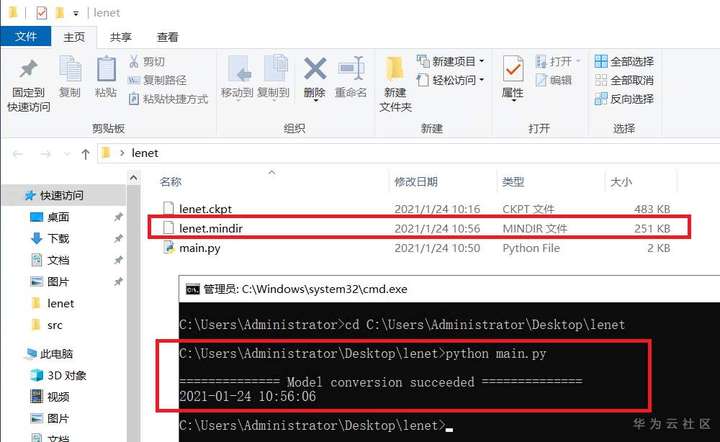
1-1导出LeNet网络的MindIR格式模型
于是我参照着大佬的简单的写了一个py解决了这题
1.定义网络
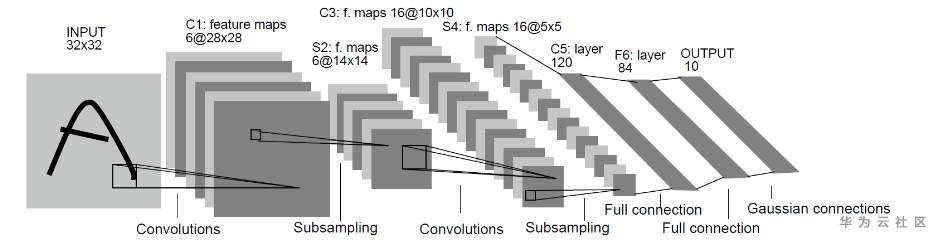
LeNet网络不包括输入层的情况下,共有7层:2个卷积层、2个下采样层(池化层)、3个全连接层。每层都包含不同数量的训练参数,如下图所示:
我们对全连接层以及卷积层采用Normal进行参数初始化。
MindSpore支持TruncatedNormal、Normal、Uniform等多种参数初始化方法,默认采用Normal。具体可以参考MindSpore API的mindspore.common.initializer模块说明。
使用MindSpore定义神经网络需要继承mindspore.nn.Cell。Cell是所有神经网络(Conv2d等)的基类。
神经网络的各层需要预先在__init__方法中定义,然后通过定义construct方法来完成神经网络的前向构造。按照LeNet的网络结构,定义网络各层如下:
import mindspore.nn as nn from mindspore.common.initializer import Normal class LeNet5(nn.Cell): """ Lenet network structure """ #define the operator required def __init__(self, num_class=10, num_channel=1): super(LeNet5, self).__init__() self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid') self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid') self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02)) self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02)) self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02)) self.relu = nn.ReLU() self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) self.flatten = nn.Flatten() #use the preceding operators to construct networks def construct(self, x): x = self.max_pool2d(self.relu(self.conv1(x))) x = self.max_pool2d(self.relu(self.conv2(x))) x = self.flatten(x) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x
MindSpore官网为我们提供了LeNet的Checkpoint文件,提供了不同版本的:https://download.mindspore.cn/model_zoo/official/cv/lenet/
*Checkpoint • 采用了Protocol Buffers格式,存储了网络中所有的参数值。一般用于训练任务中断后恢复训练,或训练后的微调(Fine Tune)任务。

在这里我选择了CPU,因为题目说可以不用训练,所以定义完网络我就直接使用了
2.模型转换
import time import mindspore.nn as nn from datetime import datetime from mindspore.common.initializer import Normal lenet = LeNet5() # 返回模型的参数字典 param_dict = load_checkpoint("./lenet.ckpt") # 加载参数到网络 load_param_into_net(lenet, param_dict) input = np.random.uniform(0.0, 1.0, size=[32, 1, 32, 32]).astype(np.float32) # 以指定的名称和格式导出文件 export(lenet, Tensor(input), file_name='lenet.mindir', file_format='MINDIR',) t = datetime.now().strftime('%Y-%m-%d %H:%M:%S') print(" ") print("============== Model conversion succeeded ==============") print(t)
1-2训练一个ResNet50网络。使用训练好的checkpoint文件,导出MindIR格式模型
训练ResNet50网络生成checkpoint
参照着官网的教程使用MindSpore训练了一个ResNet50网络图像分类模型,官网的教程里那个文档适用于CPU、GPU和Ascend AI处理器环境。使用ResNet-50网络实现图像分类:https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/cv_resnet50.html
(1)数据集的准备,这里使用的是CIFAR-10数据集。
(2)构建一个卷积神经网络,这里使用ResNet-50网络。
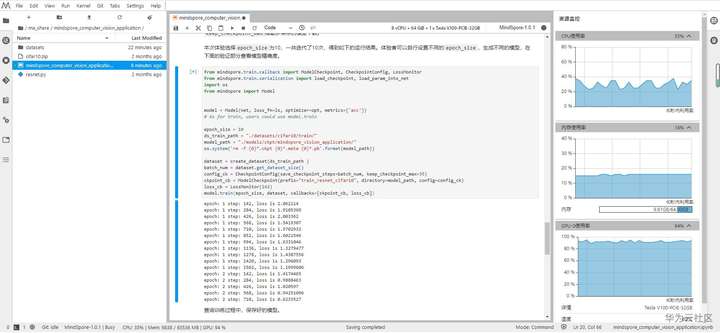
这里担心自己电脑跑不起来,使用了ModelArts平台提供的Notebook来跑 8vCPU+64G+1 x Tesla V100-PCIE-32G,不得不说性能很强
这里对训练好的ResNet50网络导出为MindIR 格式
import numpy as np from resnet import resnet50 from mindspore.train.serialization import export, load_checkpoint, load_param_into_net from mindspore import Tensor resnet = resnet50(batch_size=32, num_classes=10) # return a parameter dict for model param_dict = load_checkpoint("./models/ckpt/mindspore_vision_application/train_resnet_cifar10-10_1562.ckpt") # load the parameter into net load_param_into_net(resnet, param_dict) input = np.random.uniform(0.0, 1.0, size=[32, 3, 224, 224]).astype(np.float32) export(resnet, Tensor(input), file_name='resnet_Jack20.mindir', file_format='MINDIR')
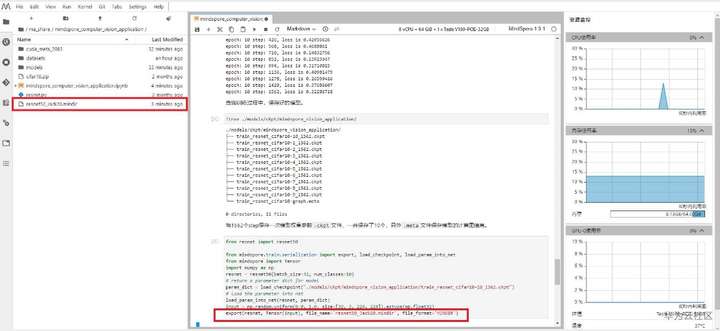
为了保存数据,我把它下载了下来,结果发现原训练好的Checkpoint文件文件过大超过了100MB不能直接下载,于是找到了另一种解决方法:
在Notebook中,新建一个“ipynb”文件,使用MoXing先将大文件从Notebook上传到OBS中,然后我再从我OBS桶了下载不就完了嘛
import moxing as mox mox.file.copy('./train_resnet_cifar10-10_1562.ckpt', 'obs://bucket_name/train_resnet_cifar10-10_1562.ckpt')
注:其中"./train_resnet_cifar10-10_1562.ckpt”为文件在Notebook中的存储路径,"train_resnet_cifar10-10_1562.ckpt”为该文件上传到OBS的存储路径。
二、华为智慧终端背后的黑科技— —超轻量AI引擎MindSpore Lite
MindSpore Lite 1.1 在端侧模型训练、算子性能优化、模型小型化、加速库自动裁剪工具、语音类模型支持、Java接口开放、模型可视化等方面进行了全面升级,升级后的版本更轻、更快、更易用
大家可以到官网下载对应的MindSpore Lite: https://www.mindspore.cn/tutorial/lite/zh-CN/r1.1/use/downloads.html
一、设计目标
1.端云一体化
端云IR统一,云侧训练模型可直接支持端侧重训云侧混合精度训练与端侧推理协同提升推理性能
2.极致性能/轻量化
通过NPU/CPU/GPU异构并行最大化发挥硬件算力,高效内核算法+汇编指令优化缩短推理时延不依赖任何第三方库,底层算子库使用C语言+汇编开发。
3.快捷部署
支持第三方模型TensorFlow Lite、Caffe、ONNX离线转换,使用户可快速切换后端;提供量化工具、图片数据处理等功能方便用户的部署和使用;
4.全场景覆盖
覆盖手机、IoT等各种智能设备;支持ARM CPU、GPU、NPU等多种硬件平台、支持Android/iOS操作系统;支持端侧推理及训练;
二、关键特性
1.性能优化
(1)算子融合:支持多达20+常见的融合,减少内存读写和计算量
(2)算子替换:支持常见的算子替换,通过参数值替换减少计算量
(3)算子前移:移动slice相关算动到计算图前,减少冗余计算
2.算子优化
对于CPU硬件,影响算子指令执行速度的关键因素包括了L1/L2缓存的命中率以及指令的流水布,MindSpore端侧CPU算子优化手段包括:
(1)数据的合理排布:MindSpore CPU算子采用NHWC的数据排布格式,相比NC4HW,channel方向不需要补齐至4,更省内存;相比NCHW,卷积单元的点更加紧凑,对缓存更友好;此外,算子间也不再涉及layout转换。
(2)寄存器的合理分配:将寄存器按照用途,划分为feature map寄存器、权重寄存器和输出寄存器,寄存器的合理分配可以减少数据加载的次数。
(3)数据的预存取,通过prefetch/preload等指令,可以提前将数据读到cache中。
(4)指令重排,尽量减少指令的pipeline stall。
(5)向量化计算,使用SIMD指令,如ARM NEON指令,X86 SSE/AVX指令等
3.训练后量化
丰富的量化策略,精度接近无损
MindSpore Lite训练后量化工具提供权重量化和全量化两种方法,支持1~16bit量化,支持分类,检测,NLP等多种模型
4.Micro for IoT
移动终端上的推理框架,通过模型解释的方式来进行推理,这样的方式可以支持多个模型以及跨硬件平台,但是需要额外的运行时内存(MCU中最昂贵的资源)来存储元信息(例如模型结构参数)。MindSpore for Micro的CodeGen方式,将模型中的算子序列从运行时卸载到编译时,并且仅生成将模型执行的代码。它不仅避免了运行时解释的时间,而且还释放了内存使用量,以允许更大的模型运行。这样生成的二进制大小很轻,因此具有很高的存储效率。
5.异构自动并行
6.端云统一
MindSpore在框架的设计上进行了分层设计,将端云共用的数据结构和模块解耦出来,在满足端侧轻量化的同时,保持了端云架构的一致性
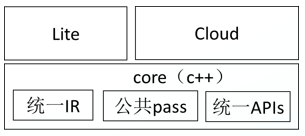
(1)统一IR:MindSpore core的统一lR,保证了端云模型/算子定义的一致性,使得云侧训练的模型可以无缝的部署在端侧。同时,对于端侧训练,可以和云侧使用一致的R进行模型的重训。
(2)公共pass:为了提升性能,训练好的模型在执行推理前,需要提前做一些优化手段,这些优化包括了融合、常量折叠、数据排布的调整等等。对于端云共享的优化,同样也是包含在MindSporecore模块中,只不过对于云侧推理,这些优化是在线推理时去执行的,而对于移动终端这些优化在执行推理前离线完成。
(3)统一接口:MindSpore设计了端云统一的C++接口。统一的C++接口的用法尽量与Python接口保持了一致,降低了学习成本。通过统一接口,用户可以使用一套代码在不同的硬件上进行推理。
7.端侧训练
(1)支持30+反向算子,提供SGD、ADAM等常见优化器及CrossEntropy/SparsCrossEntropy/MSE等损失函数;既可从零训练模型,也可指定特定网络层微调,达到迁移学习目的;
(2)已支持LeNet/AlexNet/ResNet/MobileNetV1/V2/V3和EffectiveNet等网络训练,提供完整的模型加载,转换和训练脚本,方便用户使用和调测;
(3)MindSpore云侧训练和端侧训练实现无缝对接,云侧模型可直接加载到端侧进行训练;
(4)支持checkpoint机制,训练过程异常中断后可快速恢复继续训练;
实践一下:
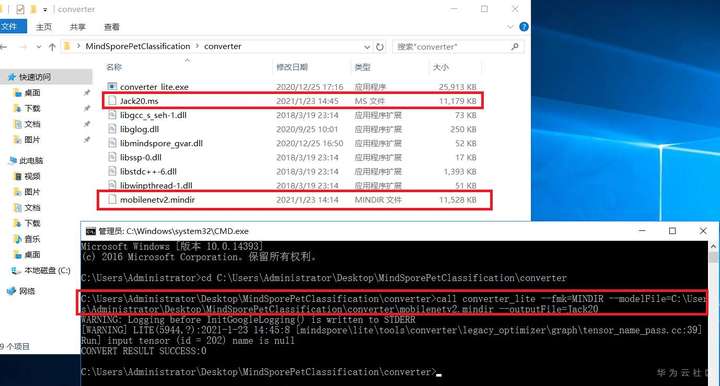
2-1在 MindSpore model_zoo下载模型mobilenetv2.mindir( https://download.mindspore.cn/model_zoo/official/lite/mobilenetv2_openimage_lite), 使用MindSpore lite converter 转成.ms 模型,请保留所使用的模型转换命令和模型转换截图
1.按要求打开链接找到指定的模型文件下载下来备用

2.把文件放到MindSpore lite converter文件夹下
因为我这里是直接把文件夹放到了桌面,在CMD中进到这个文件环境目录里
cd c: \Users\Administrator\Desktop\MindSporePetClassification\converter
3.将.mindir模型转换为.ms 模型
call converter_lite --fmk=MINDIR --modelFile=c:\Users\Administrator\Desktop\MindSporePetClassification\converter\mobilenetv2.mindir --outputFile=Jack20
注意:其中c:\Users\Administrator\Desktop\MindSporePetClassification\converter\mobilenetv2.mindir代表生成的mindir文件,而--outputFile定义转换后MS文件的名称。
成功后,会在converter文件夹中生成对应的.ms文件。
三、一键部署在线推理服务— —MindSpore Serving
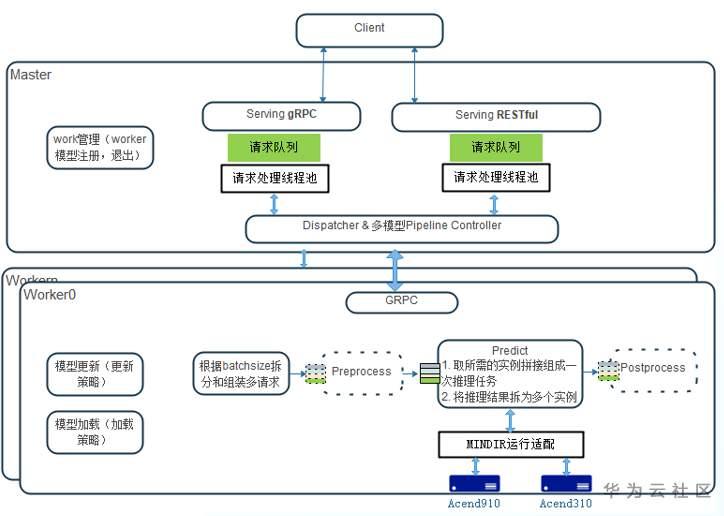
MindSpore Serving就是为实现将深度学习部署到生产环境而产生的
MindSpore Serving是一个简单易用、高性能的服务模块,旨在帮助MindSpore开发者在生产环境中高效部署在线推理服务
注:MindSpore Serving当前仅支持Ascend 310和Ascend 910环境。
大家可以在MindSpore官网下载对应版本安装包实践:https://www.mindspore.cn/versions
特点
(1)简单易用
提供Python接口配置和启动Serving服务,对客户端提供gRPC和RESTful访问接口,提供Python客户端接口,通过它,大家可以轻松定制、发布、部署和访问模型服务。
安装:
pip install mindspore_serving-1.1.0-cp37-cp37m-linux_aarch64.whl
1)轻量级部署
服务端调用Python接口直接启动推理进程(master和worker共进程),客户端直接连接推理服务后下发推理任务。 执行master_with_worker.py,完成轻量级部署服务:
import os from mindspore_serving import master from mindspore_serving import worker def start(): servable_dir = os.path.abspath(".") worker.start_servable_in_master(servable_dir, "add", device_id=0) master.start_grpc_server("127.0.0.1", 5500) if __name__ == "__main__": start()
当服务端打印日志Serving gRPC start success, listening on 0.0.0.0:5500时,表示Serving服务已加载推理模型完毕。
2)集群部署
服务端由master进程和worker进程组成,master用来管理集群内所有的worker节点,并进行推理任务的分发。
部署master:
import os from mindspore_serving import master def start(): servable_dir = os.path.abspath(".") master.start_grpc_server("127.0.0.1", 5500) master.start_master_server("127.0.0.1", 6500) if __name__ == "__main__": start()
部署worker:
import os from mindspore_serving import worker def start(): servable_dir = os.path.abspath(".") worker.start_servable(servable_dir, "add", device_id=0, master_ip="127.0.0.1", master_port=6500, worker_ip="127.0.0.1", worker_port=6600) if __name__ == "__main__": start()
轻量级部署和集群部署启动worker所使用的接口存在差异,其中,轻量级部署使用start_servable_in_master接口启动worker,集群部署使用start_servable接口启动worker。
(2)提供定制化服务
支持模型供应商打包发布模型、预处理和后处理,围绕模型提供定制化服务,并一键部署,服务使用者不需要感知模型处理细节。
举个栗子:实现导出两个tensor相加操作的模型
import os from shutil import copyfile import numpy as np import mindspore.context as context import mindspore.nn as nn import mindspore.ops as ops import mindspore as ms context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") class Net(nn.Cell): """Define Net of add""" def __init__(self): super(Net, self).__init__() self.add = ops.TensorAdd() def construct(self, x_, y_): """construct add net""" return self.add(x_, y_) def export_net(): """Export add net of 2x2 + 2x2, and copy output model `tensor_add.mindir` to directory ../add/1""" x = np.ones([2, 2]).astype(np.float32) y = np.ones([2, 2]).astype(np.float32) add = Net() output = add(ms.Tensor(x), ms.Tensor(y)) ms.export(add, ms.Tensor(x), ms.Tensor(y), file_name='tensor_add', file_format='MINDIR') dst_dir = '../add/1' try: os.mkdir(dst_dir) except OSError: pass dst_file = os.path.join(dst_dir, 'tensor_add.mindir') copyfile('tensor_add.mindir', dst_file) print("copy tensor_add.mindir to " + dst_dir + " success") print(x) print(y) print(output.asnumpy()) if __name__ == "__main__": export_net()
构造一个只有Add算子的网络,并导出MindSpore推理部署模型,该模型的输入为两个shape为[2,2]的二维Tensor,输出结果是两个输入Tensor之和。
(3)支持批处理
用户一次请求可发送数量不定样本,Serving分割和组合一个或多个请求的样本以匹配模型的实际batch,不仅仅加速了Serving请求处理能力,并且也简化了客户端的使用。
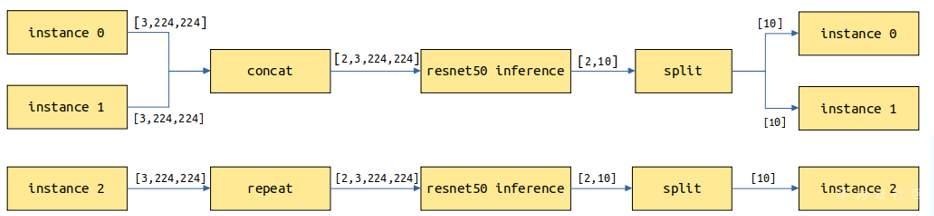
主要针对处理图片、文本等包含batch维度的模型。假设batch_size=2,当前请求有3个实例,共3张图片,会拆分为2次模型推理,第1次处理2张图片返回2个结果,第2次对剩余的1张图片进行拷贝做一次推理并返回1个结果,最终返回3个结果。
对于一个模型,假设其中一个输入是数据输入,包括batch维度信息,另一个输入为模型配置信息,没有包括batch维度信息,此时在设置with_batch_dim为True基础上,设置额**数without_batch_dim_inputs指定没有包括batch维度信息的输入信息。
from mindspore_serving.worker import register # Input1 indicates the input shape information of the model, without the batch dimension information. # input0: [N,3,416,416], input1: [2] register.declare_servable(servable_file="yolov3_darknet53.mindir", model_format="MindIR", with_batch_dim=True, without_batch_dim_inputs=1)
(4) 高性能高扩展
支持多模型多卡并发,通过client/master/worker的服务体系架构,实现MindSpore Serving的高性能和高扩展性。
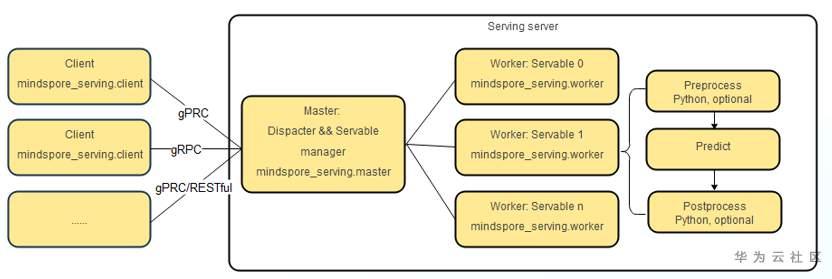
华为Ascend主打芯片低功耗、高算力等特性,MindSpore提供高效的内核算法、自动融合,自动并行等能力。支持多模型多卡并发,通过client/master/worker的服务体系架构,实现MindSpore Serving的高性能和高扩展性。
高可靠性设计(某个服务节点宕机,不影响客户端正常服务),负载均衡(如何更合理的使用所有资源信息),弹性扩容缩容(根据业务的高峰低谷,动态调整资源)
四、AI数据高速加载直通车— —单节点数据缓存
Cache单节点缓存模块可用于缓存预处理后的训练数据,加速数据加载,提升数据复用率,降低数据预处理所需的CPU算力
对于需要重复访问远程的数据集或需要重复从磁盘中读取数据集的情况,可以使用单节点缓存算子将数据集缓存于本地内存中,以加速数据集的读取。 缓存算子依赖于在当前节点启动的缓存服务器,缓存服务器作为守护进程独立于用户的训练脚本而存在,主要用于提供缓存数据的管理,支持包括存储、查找、读取以及发生缓存未命中时对于缓存数据的写入等操作。
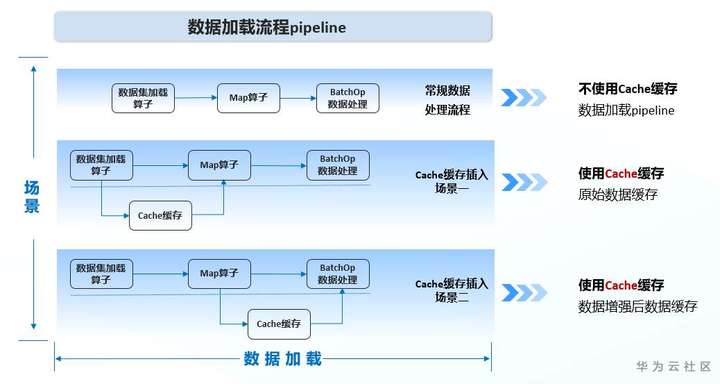
对比使用数据缓存和不使用数据缓存的数据加载流程pipeline,第一个,是不使用数据缓存服务的常规数据处理流程
1.缓存加载后的原始数据,用户可以在数据集加载算子中使用缓存。这将把加载完成的数据存到缓存服务器中,后续若需相同数据则可直接从中读取,避免从磁盘中重复加载。
2.缓存经过数据增强操作后的数据,用户也可在Map算子中使用缓存。这将允许我们直接缓存数据增强(如图像裁剪、缩放等)处理后的数据,避免数据增强操作重复进行,减少了不必要的计算量。
3. 以上两种类型的缓存本质上都是为了提高数据复用,以减少数据处理过程耗时,提高网络训练性能。
Cache的三个重要组件
(1)缓存算子
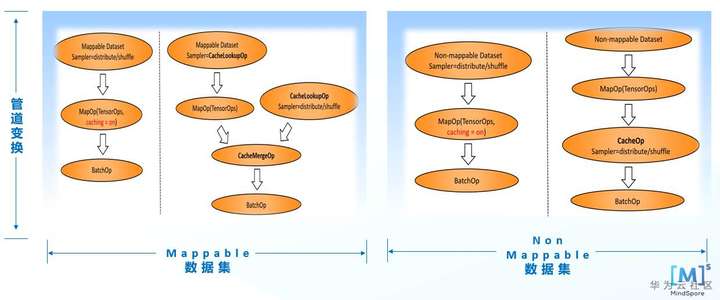
1.对于mappable的数据集(如ImageFolder)的pipeline,Cache将创建名为CacheLookupOp和CacheMergeOp的两个缓存算子,并对pipeline做出相应的调整。
2.见于上图Mappable数据集图示,左边的数据处理pipeline,当用户在MapOp后插入缓存算子后,经过Cache变换调整过程,将对pipeline进行变换并最终将其调整为右图中包含CacheLookupOp和CacheMergeOp两个缓存算子的结构
3.对于包含non-mappable的数据集(如TFRecord)的pipeline,我们将创建名为CacheOp的缓存算子,并在pipeline相应位置插入CacheOp。见于上图Non-mappable数据集图示,左边的数据处理pipeline,当用户在MapOp后插入缓存算子后,经过Cache变换调整过程,将对pipeline进行变换并最终将其调整为右图中包含CacheOp缓存算子的结构。
(2)缓存服务器
主要负责响应缓存客户端所发送的请求,提供缓存数据的查找、读取,以及发生缓存未命中时对于缓存数据的写入等功能。缓存服务器拥有自己的工作队列,不断循环从工作队列中获取一个请求去执行并将结果返回给客户端。同一个缓存服务器可以为多个缓存客户端提供服务,且缓存服务器通过缓存客户端的session_id以及该缓存客户端所对应的数据处理pipeline的crc码来唯一确定该缓存客户端。因此,两个完全一致的pipeline可以通过指定相同的session_id来共享同一个缓存服务,而不同的pipeline若试图共享同一个缓存客户端则会报错。
1.Cache_server如何启动?
Cache Server的服务由一个外部守护进程提供,在用户使用Cache服务之前,需要先在mindspore外部启动一个服务器守护进程,来与缓存客户进行交互沟通;
ms_cache_server start|session [–m <mem_size>] [-d <spill_path>] [-nospill] [-h <host>] [-p <port>] #Command: start | session #start #– starts the service #session #– creates a new caching session, returning the session_id as output
然后启动
cache_admin --start

2.cache_server创建时默认的port端口号是多少?
默认对IP为127.0.0.1(localhost)且端口号为50052的服务器执行操作
(3)缓存客户端
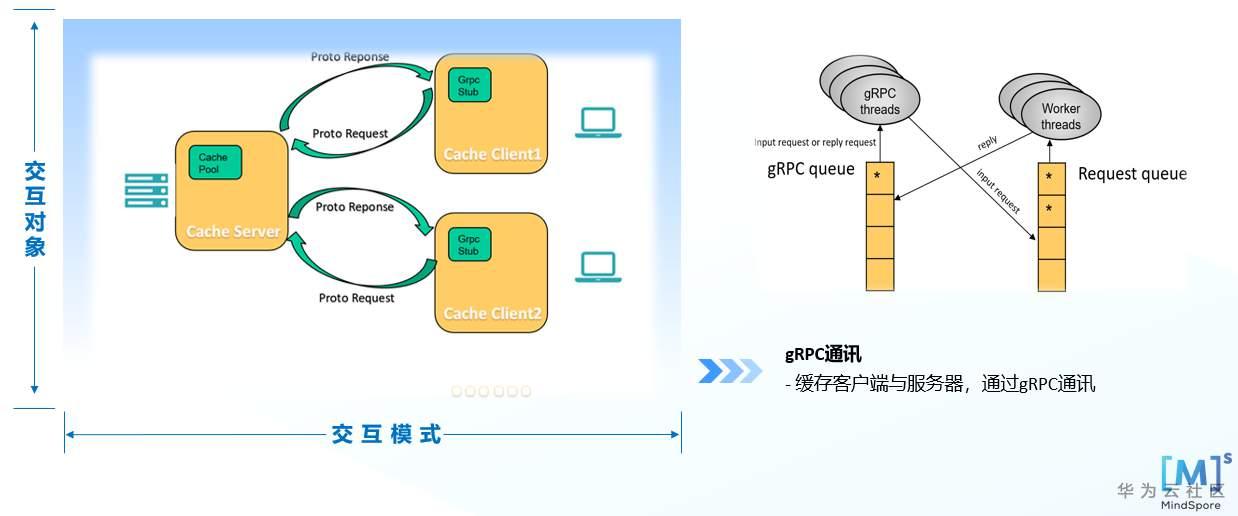
主要负责与缓存服务器建立通讯,向缓存服务器发起数据读取、数据写入、状态查询等请求。缓存客户端与服务器之间通过gRPC进行通讯,如下图所示:当客户端需要发起请求时,仅需要将请求添加到gRPC函数库所提供的gRPC队列,由gRPC线程不断循环从gRPC队列中获取一个请求并将该请求发送到缓存服务器的工作队列中。当缓存服务器需要将处理后的响应数据返回给客户端时,也通过类似的方式将响应数据添加到gRPC队列中,并依赖gRPC实际将数据传输至客户端。
3.cache_client实体在创建时,其<session_id>如何获取?
唯一标识与缓存服务的连接session。应该从ms_cache_service session命令返回的session_id。当给出该选项时,缓存的大小和溢出行为取自session。如果未给出值,则假设这是唯一的通道,没有其他通道将共享此缓存。在这种情况下,将自动生成一个session_id。
ms_cache_server start|session [–m <mem_size>] [-d <spill_path>] [-nospill] [-h <host>] [-p <port>] #Command: start | session #– creates a new caching session, returning the session_id as output

若缓存服务器中不存在缓存会话,则需要创建一个缓存会话,得到缓存会话id:
其中3231564523为端口50052的服务器分配的缓存会话id,缓存会话id由服务器分配。
五、快速定位模型精度问题— —MindSpore调试器
在图模式下,用户难以从Python层获取到计算图中间节点的结果。MindSpore调试器是为图模式训练提供的调试工具,可以用来查看并分析计算图节点的中间结果。
使用MindSpore调试器,可以:
(1)在MindInsight调试器界面结合计算图,查看图节点的输出结果;
(2)设置监测点,监测训练异常情况(比如检查张量溢出),在异常发生时追踪错误原因;
(3)查看权重等参数的变化情况。
一、常见精度问题和定位思路
(1)常见现象
- loss:跑飞,不收敛,收敛慢
- metrics:accuracy、precision等达不到预期
- 梯度:梯度消失、梯度爆炸
- 权重:权重不更新、权重变化过小、权重变化过大
- 激活值:激活值饱和、dead relu
(2)常见问题
- 模型结构问题:算子使用错误、权重共享错误、权重冻结错误、节点连接错误、 loss函数错误、优化器错误等
- 超参问题:超参设置不合理等
- 数据问题:缺失值过多、异常值、未归一化等
(3)常用定位思路
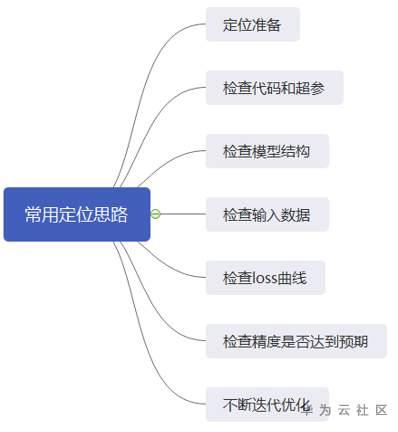
1)定位准备
回顾算法设计,全面熟悉模型
•算法设计、超参、loss、优化器、数据处理等
•参考论文、其它实现
熟悉可视化工具
•安装MindInsight https://www.mindspore.com/install
•加入SummaryCollector callback,收集训练信息
•在summary_dir的父目录中启动MindInsight
•mindinsight start
•熟悉调试器使用
熟悉调试器
•MindSpore调试器是为图模式训练提供的调试工具
•在MindInsight调试器界面结合计算图,查看图节点的输出结果;
•设置监测点,监测训练异常情况(比如检查张量溢出),在异常发生时追踪错误原因;
•查看权重等参数的变化情况。
使用指南请见 https://www.mindspore.cn/tutorial/training/zh-CN/master/advanced_use/summary_record.html
•debugger使用指南请见https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/debugger.html
2)检查代码、超参、模型结构
1.走读脚本,检查代码
•小黄鸭调试法
•检查代码同模型设计、论文、参考脚本等是否一致
2.超参常见问题:
•学习率不合理
•权重初始化参数不合理等
3.MindInsight辅助检查:训练列表->训练参数详情
4.模型结构常见问题:
•算子使用错误(使用的算子不适用于目标场景,如应该使用浮点除,错误地使用了整数除),
•权重共享错误(共享了不应共享的权重),
•权重冻结错误(冻结了不应冻结的权重),
•节点连接错误(应该连接到计算图中的block未连接),
•loss函数错误,
•优化器算法错误(如果自行实现了优化器)等。
5.MindInsight辅助检查:训练列表->训练看板->计算图
3)检查输入数据
1.输入数据常见问题:
•数据缺失值过多
•每个类别中的样本数目不均衡
•数据中存在异常值
•数据标签错误
•训练样本不足
•未对数据进行标准化,输入模型的数据不在正确的范围内
•finetune和pretrain的数据处理方式不同
•训练阶段和推理阶段的数据处理方式不同
•数据处理参数不正确等。
2.MindInsight辅助检查:训练列表->训练看板->数据抽样
4)检查loss曲线
1.常见现象
•loss跑飞
回顾脚本、模型结构和数据,
•检查超参是否有不合理的特别大/特别小的取值,
•检查模型结构是否实现正确,特别是检查loss函数是否实现正确,
•检查输入数据中是否有缺失值、是否有特别大/特别小的取值。
使用参数分布图检查参数更新是否有剧烈变化
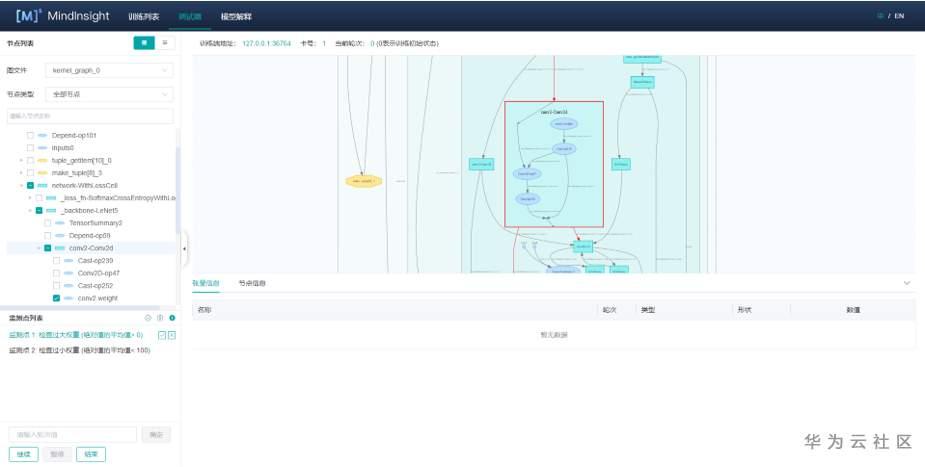
使用调试器功能对训练现场进行检查
•配置“检查张量溢出”监测点,定位NAN/INF出现位置
•配置“检查过大张量”监测点,定位出现大值的算子
•配置“检查权重变化过大”、“检查梯度消失”、“检查梯度过大”监测点,定位异常的权重或梯度
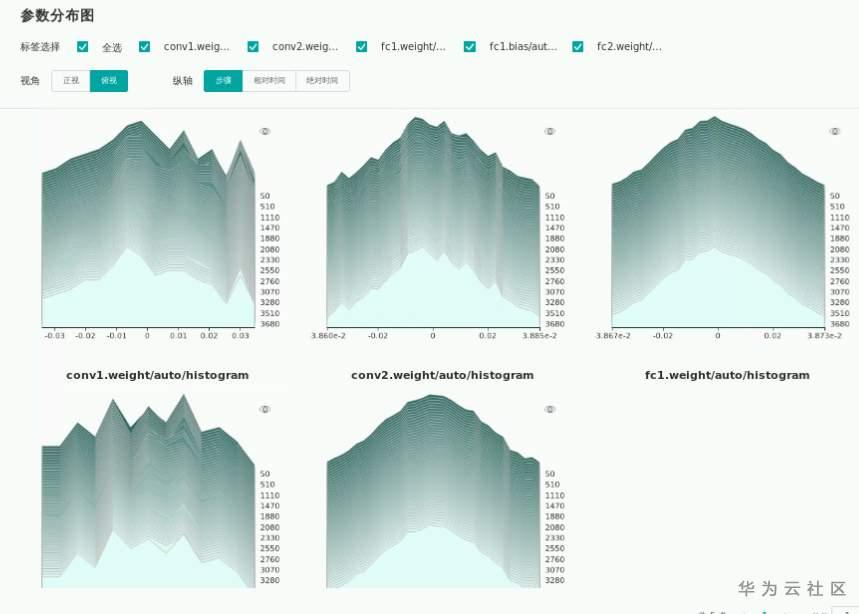
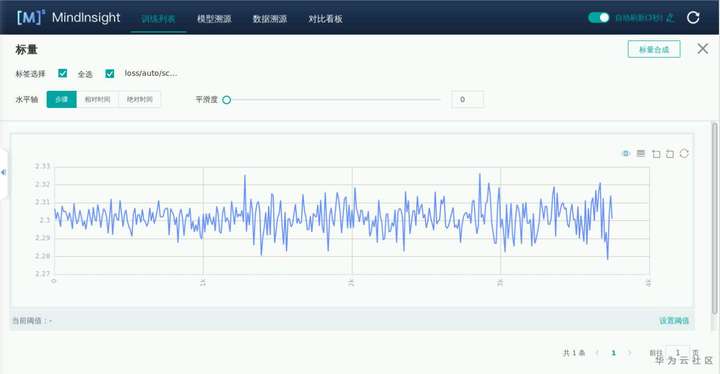
•loss收敛慢
2.MindInsight辅助检查:训练列表->训练看板->标量曲线/参数分布图
3.调试器定位
5)检查精度是否达到预期
1.回顾代码、模型结构、输入数据和loss曲线,
•检查超参是否有不合理的值
•检查模型结构是否实现正确
•检查输入数据是否正确
•检查loss曲线的收敛结果和收敛趋势是否存在异常
2.尝试使用“溯源分析”和调参器优化超参
•mindoptimizer --config ./config.yaml --iter 10
3.尝试模型解释
4.尝试优化模型算法
注意事项
1.场景支持
•调试器暂不支持分布式训练场景。
•调试器暂不支持推断场景。
•调试器暂不支持单机多卡/集群场景。
•调试器暂不支持连接多个训练进程。
•调试器暂不支持CPU场景。
2.性能影响
•使用调试器时,会对训练性能产生一定影响。
•设置的监测点数目过多时,可能会出现系统内存不足(Out-of-Memory)的异常。
3.GPU场景
•在GPU场景下,只有满足条件的参数节点可以与自身的上一轮次结果作对比:使用下一个节点执行过的节点、使用运行到该节点时选中的节点、作为监测点输入的参数节点。其他情况均无法使用上一轮次对比功能。
•由于GPU上一个轮次是一个子图(而非完整的图),GPU上多图做重新检查时,只能重新检查当前的子图。
4.重新检查只检查当前有张量值的监测点。
5.检查计算过程溢出需要用户开启异步Dump的全部溢出检测功能,开启方式请参照异步Dump功能介绍
6.调试器展示的图是优化后的最终执行图。调用的算子可能已经与其它算子融合,或者在优化后改变了名称。
参考
本文分享自华为云社区《几个小实践带你两天快速上手MindSpore 》,原文作者:Jack20 。

