有了这个算法,图像上文字擦除再也用不上PS了
摘要:本文介绍几篇关于自然场景下文字擦除的论文工作。
图像文字擦除方法
给定一幅自然场景图像,只将图像中文字区域抹去而不改动其他区域像素值的方法称为文字擦除算法。该方法在隐私保护,身份信息篡改,数据增广等领域有着广泛的应用和研究前景。
受传统生成对抗网络(GAN)算法的启发,基于深度学习的文字擦除算法都采用了类似的生成器+判别器的结构,其损失函数为:
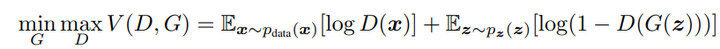
- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能的大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(z))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)。
文字擦除可以分为两个子任务:1)文字区域定位。2)文字内容擦除。Ensnet [1] 提出了一种端到端的文字擦除算法,该方法将两个子任务合并,并让一个网络进行端到端的文字擦除(图1所示)。最后通过判别器和多种损失函数指导生成器的学习。
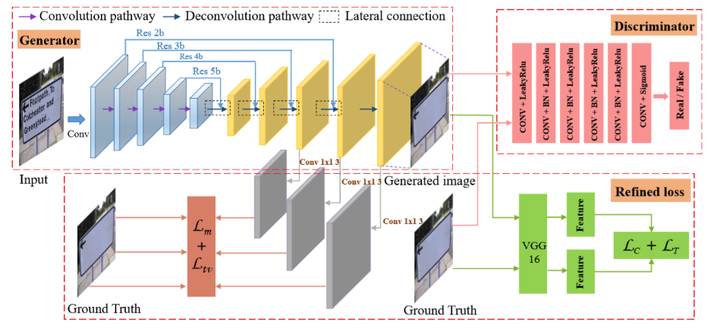
图1. Ensnet 算法结构
为了让网络能够更好地感知文字内容的位置信息,Erasenet [2]进一步引入了一个mask分支进行学习(图2),同时提出了一个新的真实文字擦除数据集,为文字擦除研究领域提供了一个更好的对比基准(图3)。
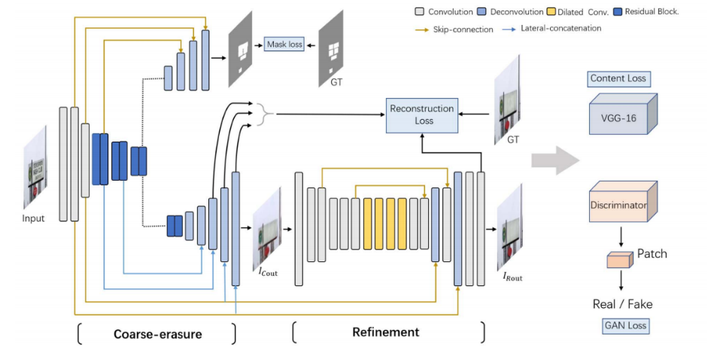
图2. Erasenet 网络

图3. 真实场景的文字擦除数据集
为了将两个子任务进行更好的学习,从而实现更准确的文字擦除结果,MTRNet[3]在输入引入文字分割结果,让网络能够感知文字区域的位置信息,从而降低任务难度,实现更准确的擦除结果。Bian等人[5]通过一种级联的结构,实现对具体的字形感知。但是由于需要提前知道文字区域的准确位置信息,所以这些方法具有一定的局限性。MTRNet++[4]在STRNet基础上进行了改进(图4),通过引入一个微调子网络降低了整体网络对输入位置信息的依赖性,从而实现更鲁棒的文字擦除算法。
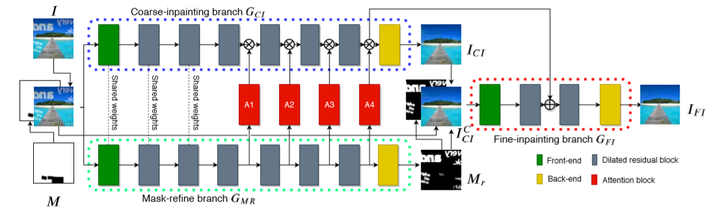
图4. MTRNet++网络
总结与思考
可以看到,现阶段深度学习的文字检测方法都是基于GAN网络框架的,那么,是否有别的方法能够实现GAN相同的效果?区别于传统大面积pixel-to-pixel的任务,文字擦除大多只涉及小区域的像素修改,笔者认为attention在未来可以成为一个新的解决思路。
参考文献
[1] Zhang, Shuaitao, et al. "Ensnet: Ensconce text in the wild." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
[2] Liu, Chongyu, et al. "EraseNet: End-to-End Text Removal in the Wild." IEEE Transactions on Image Processing 29 (2020): 8760-8775.
[3] Tursun, Osman, et al. "Mtrnet: A generic scene text eraser." 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019.
[4] Tursun, Osman, et al. "MTRNet++: One-stage mask-based scene text eraser." Computer Vision and Image Understanding 201 (2020): 103066.
[5] Bian, Xuewei, et al. "Scene text removal via cascaded text stroke detection and erasing." arXiv preprint arXiv:2011.09768 (2020).
本文分享自华为云社区《技术综述九:自然场景图像的文字擦除算法介绍》,原文作者:我想静静。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号