

微服务容错时,这些技术你要立刻想到
摘要:伴随着微服务架构被宣传得如火如荼,一些概念也被推到了我们面前。服务熔断、服务降级,好高大上的样子,以前望尘莫及,今日终于揭开它神秘面纱。
服务雪崩效应的定义很简单,是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程。
可以结合下图进行理解:
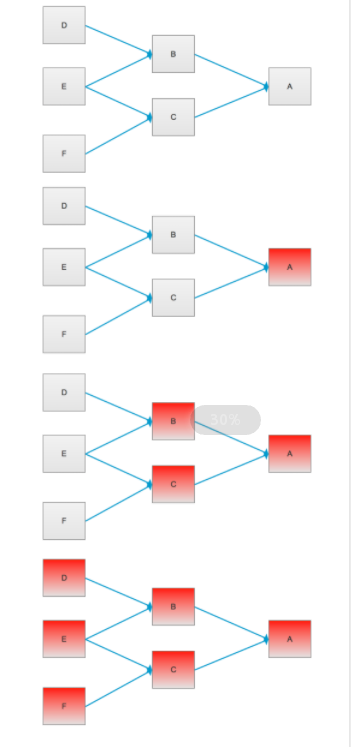 服务雪崩
服务雪崩
上图中,A作为基础的服务提供者,为B和C提供服务,D、E、F是B和C服务的调用者,当A不可用时,将引起B和C的不可用,并将这种不可用放大到D、E、F,从而可能导致整个系统的不可用,服务雪崩的产生可能导致分布式系统的瘫痪。
服务雪崩效应的产生一般有三个流程,服务提供者不可用 -> 重试加大流量 -> 服务调用者不可用
服务提供者不可用的出现的原因有很多,可能是因为服务器的宕机或者网络故障,也可能是因为程序存在的Bug,也有可能是大量的请求导致服务提供者的资源受限无法及时响应,还有可能是因为缓存击穿造成服务提供者超负荷运行等等,毕竟没有人能保证软件的完全正确性。
在服务提供者不可用发生之后,用户可能无法忍受长时间的等待,不断地发送相同的请求,服务调用者重新调用服务提供者,同时服务提供者中可能存在对异常的重试机制,这些都会加大对服务提供者的请求流量。然而此时的服务提供者已经是一艘破船,它也无能无力,无法返回有效的结果。
最后是服务调用者因为服务提供者的不能用导致了自身的崩溃。当服务调用者使用同步调用的时候,大量的等待线程将会耗尽线程池中的资源,最终导致服务调用者的宕机,无法响应用户的请求,服务雪崩效应就此发生了。
断路器
在分布式系统中,不同服务之间发生的调用非常常见,当服务提供者不可用时就很有可能发生服务雪崩的效应,导致整个系统的不可用。所以为了预防这种请求的发生,可以通过断路器模式进行预防(类比电路中的断路器,在电路过大的时候自动断开,防止电线过热损害整条电路)。
断路器模式背后的思想很简单,将远程函数调用包装到一个断路器对象中,用于监控函数调用过程的失败。一旦该函数调用的发生失败的次数在一段时间内到达一定的阀值,那么这个断路器将会跳闸,然后接下来时间里对该被保护函数调用的线程将会被断路器直接返回一个错误,而不再发生该函数的真实调用。这样子就避免了服务调用者在服务提供者不可用时发送请求,从而减少线程池中资源的消耗,保护了服务调用者。
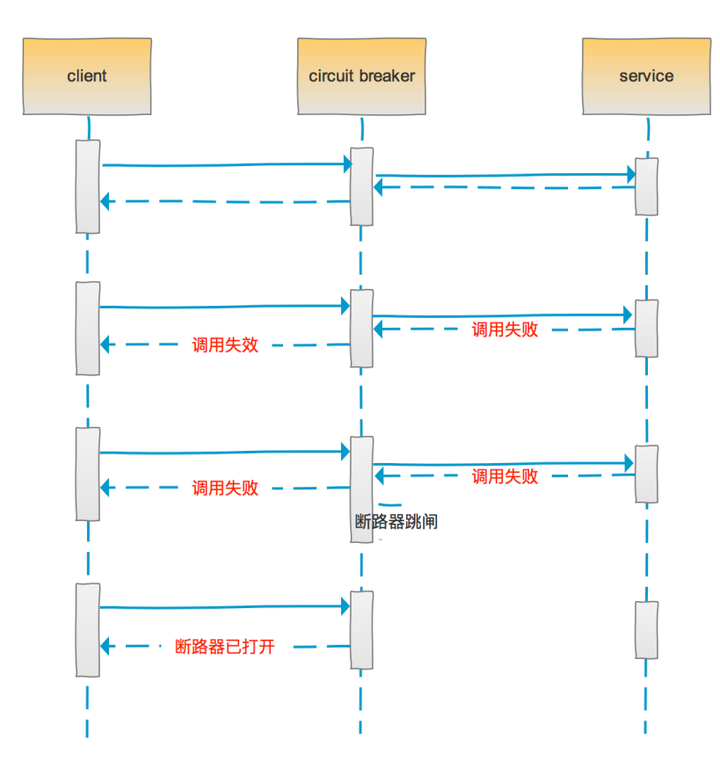 断路器时序图
断路器时序图
虽然上面的断路器在打开的时候避免了被保护的函数调用,但是当情况恢复正常时,需要外部干预来重置断路器,使得函数调用可以重新发生。所以合理的断路器应该具备以下的开关转化逻辑,它需要一个机制来控制它的重新闭合,图6-3中是通过一个重置时间来决定。
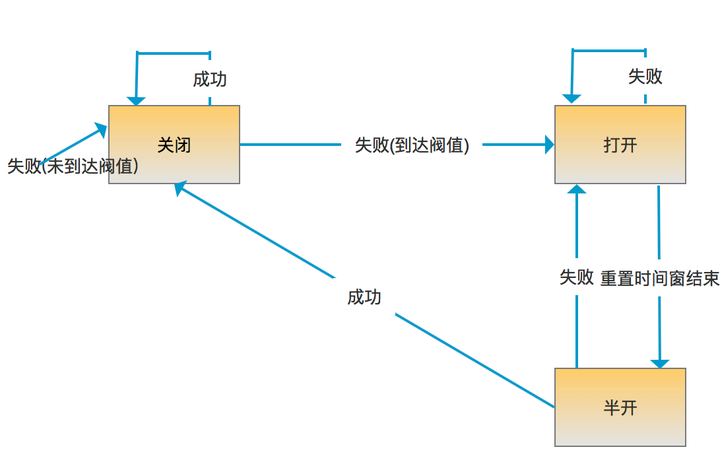 断路器状态图
断路器状态图
- 关闭状态: 断路器处于关闭状态,统计调用失败次数,在一段时间内到达一定的阀值后断路器打开。
- 打开状态: 断路器处于打开状态,对函数调用直接返回失败错误,不发生真正的函数调用。设置了一个重置时间窗,在重置时间窗结束后,断路器来到半开状态。
- 半开状态: 断路器处于半开状态,此时允许进行函数调用,当调用都成功了(或者成功到达一定的比例),关闭断路器,否则认为服务没有恢复,重新打开断路器。
断路器的打开能保证服务调用者在调用异常服务时,快速返回结果,避免大量的同步等待,减少服务调用者的资源消耗。并且断路器能在打开的一段时间后继续侦测请求执行结果,提供断路器关闭的可能,恢复服务的调用。
服务降级操作
断路器是为了隔断服务调用者和异常服务提供者,防止了服务雪崩的现象,是一种保护的措施。而服务降级的意思是在整体资源不够的时候,适当的放弃部分服务,将主要的资源投放到核心服务中,待渡过难关之后,再把关闭的服务重启回来。
在Hystrix中,当服务间调用发生问题时,它将采用备用的fallback方法代替主方法执行并返回结果,这就进行了服务降级,同时触发了断路器的逻辑。当调用服务失败次数在一段时间内超过了断路器的阀值时(此时一直调用fallback中的逻辑返回结果),断路器将打开,此时将不再调用函数,而是快速失败,直接执行fallback逻辑,服务降级,减少服务调用者的资源消耗,保护服务调用者中的线程资源。
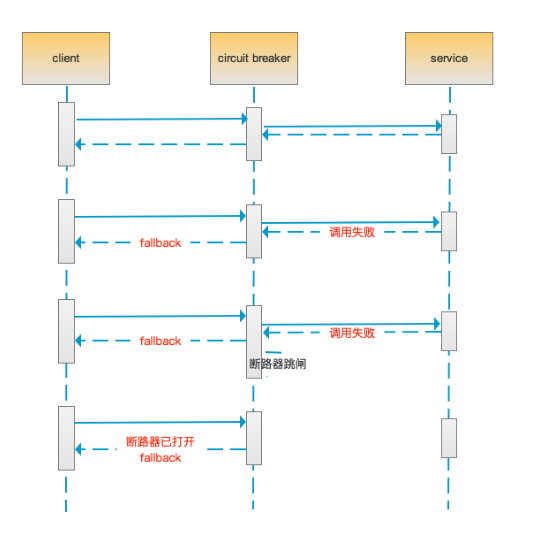
资源隔离
在货船中,为了防止漏水和火灾的扩散,一般会将货仓进行分割,避免了一个货仓出事导致整艘船沉没的悲剧。同样的,在Hystrix中,也采用了这样的舱壁模式,将系统中的服务提供者隔离起来,一个服务提供者延迟升高或者失败,并不会导致整个系统的失败,同时也能够控制调用这些服务的并发度。
- 线程与线程池
Hystrix中通过将调用服务线程与服务访问的执行线程分隔开来,调用线程能够空出来去做其他的工作而不至于被服务调用的执行的阻塞过长的时间。
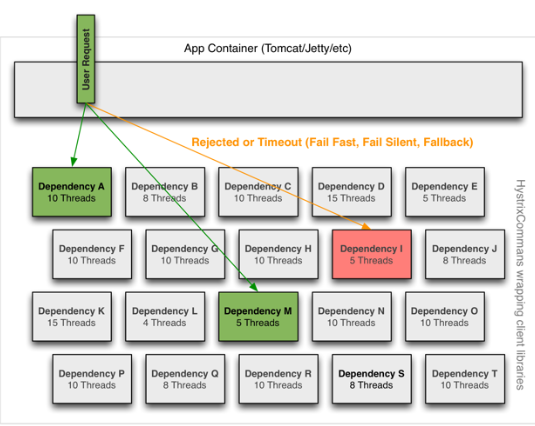
在Hystrix中使用独立的线程池对应每一个服务提供者,来隔离和限制这些服务,于是,某个服务提供者的高延迟或者饱和资源受限只会发生在该服务提供者对应的线程池中。
如上图中,Dependency I的调用失败或者高延迟仅会导致自身对应的线程池中的5个线程的阻塞,并不会影响其他服务提供者的线程池。系统完全与服务提供者请求隔离开来,即使服务提供者对应的线程完全耗尽,并不会影响系统中的其他请求。
注意在对应服务提供者的线程池被占满时,Hystrix会进入了fallback逻辑,快速失败,保护服务调用者的资源稳定。
- 信号量
除了线程池外,Hystrix还可以通过信号量(计数器)来限制单个服务提供者的并发量。如果通过信号量来控制系统负载,将不再允许设置超时控制和异步化调用,这就表示在服务提供者出现高延迟,其调用线程将会被阻塞,直至服务提供者的网络请求超时,如果对服务提供者的稳定性有足够的信心,可以通过信号量来控制系统的负载。
总结
我们在这篇文章介绍了熔断、服务雪崩、服务降级等概念。在处理微服务容错时,这些都是常用的技术,我们需要首先了解其概念。

