面对key数量多和区间查询低效问题:Hash索引趴窝,LSM树申请出场
摘要:Hash索引有两个明显的限制:(1)当key的数量很多时,维护Hash索引会给内存带来很大的压力;(2)区间查询很低效。如何对这两个限制进行优化呢?这就轮到本文介绍的主角,LSM树,出场了。
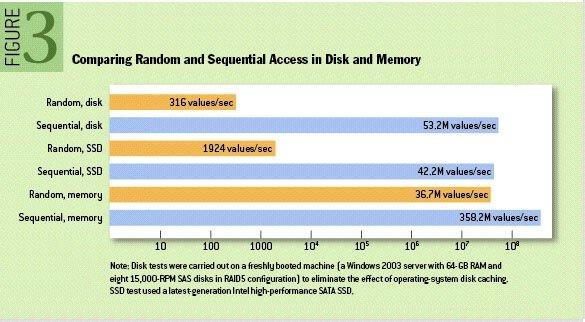
我们通过append-only log的数据结构,实现了一个具备高写入性能的key-value数据库。append-only log之所以有很高的写入性能,主要得益于磁盘的顺序写入。这可能违反了我们对磁盘的认知,因为在我们的印象中,写磁盘总是很慢。其实不然,准确地说应该是随机写磁盘很慢,因为在写之前可能会进行多次寻址。如果只是顺序写磁盘,性能是非常的高,如下的一个ACM报告中显示,顺序写磁盘甚至比随机写内存的性能还要高!
举个例子,Kafka是一个高性能的消息队列,它的厉害之处就在于极致地利用磁盘的顺序写入性能,如果生产者和消费者的速率相当,消息甚至可以在操作系统的Page Cache层面就完成了传递。所以,以后别再认为写磁盘很慢了!
append-only log大幅提升了数据写入性能,但是随之而来的是,非常低的数据读取性能。针对这一点,我们采用Hash索引进行了优化,优化的效果也非常的显著。然而,Hash索引有两个明显的限制:(1)当key的数量很多时,维护Hash索引会给内存带来很大的压力;(2)区间查询很低效。如何对这两个限制进行优化呢?这就轮到本文介绍的主角,LSM树,出场了。
LSM树(Log-Structured Merge Tree)并不是一种数据结构,准确来说是一种存储模型,由MemTable、Immutable MemTable、SSTable等部分组成。它也是利用了append-only log的优势,大幅提升了写入性能。同时,因为key的存储有序性,所以具备了不错的读取性能,也克服了上文所述Hash索引的两个限制。下面,本文将一步步分析LSM树是如何做到这一点的。
SSTable
在最简单的数据库例子中,因为数据是无序存储的,所以在读取某个key的值时,就需要遍历整个数据文件,算法复杂度是O(n)。为了提升读性能,我们不得不在内存中维护所有key的Hash索引。
假如存储数据时,对记录按照key进行排序的会怎样?
对于key有序存储这种情况,即使不用Hash索引,也能得到很好的查询效率,因为我们可以使用二分查找法(Binary Search)来快速找到key所在的位置,算法复杂度是O(logn)。LSM树正是采用key有序这种方式来组织数据存储的,并称之为SSTable。
SSTable(Sorted String Table)是LSM树最基础的一个存储结构,存储在磁盘中,并且数据按照key进行排序的。数据保持key有序的好处是可以在O(logn)的时间下,快速找到一个key值,相比于纯粹的append-only log有了很大的提升。但是,如果所有的数据都存储在一个SSTable上,数据量一大,查询效率也会下降。因此,LSM树通常会将数据分散存储在多个SSTable中,并且记录每个SSTable的最大key和最小key,这样就能快速定位到一个key存储在哪个SSTable上了。
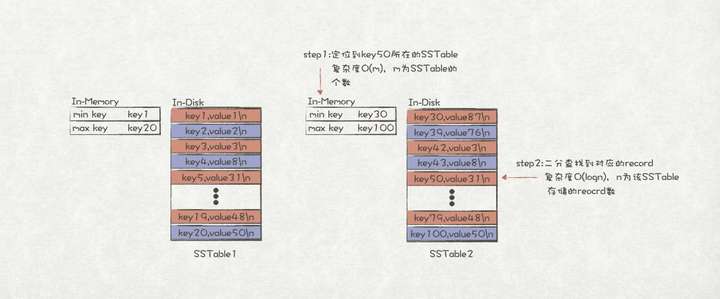
SSTable数据查找示例
// SSTable,数据保存到SSTable后只读不写 public class SSTable { ... // 数据存储路径 private final LogFile logFile; // 该SStable中存储的最小Key private String minKey; // 该SStable中存储的最大Key private String maxKey; // 使用二分查找法获取key值 public String get(String key) { // step1:先判断是否在SSTable的范围内 if (key.compareTo(minKey) < 0 || key.compareTo(maxKey) > 0) { return ""; } // step2:二分查找 long start = 0; long end = logFile.size(); while (start < end) { long mid = start + (end - start) / 2; // 先找到一条record到起始offset long startOffset = logFile.startOffsetOf(mid); String record = logFile.read(startOffset); String midKey = Util.keyOf(record); if (key.compareTo(midKey) == 0) { return Util.valueOf(record); } else if (key.compareTo(midKey) < 0) { end = mid; } else { // 找到一条record到起始offset时可能会有mid == start的情况 if (mid == start) { break; } start = mid; } } return ""; } ... }
这里只是介绍了一种比较简单的SSTable实现方式,实际上,各种LSM树存储引擎对SSTable的实现都有所差异,比如LevelDB就将SSTable划分成两大块,数据存储区存储key:value数据,数据管理区存储索引等数据。
那么怎样才能保证SSTable的有序性呢?
类似的在磁盘中维护数据有序的存储结构最常见的当属B/B+树了,如果对SSTable也采用类似的存储结构,那么带来的第一个问题就是每次写入都会伴随着磁盘的随机写,从而影响了数据的写入性能,这明显就违反了LSM树的初衷。为了同时兼顾SSTable的有序性以及写入性能,LSM树采用了MemTable这一组件。
MemTable
相比于磁盘上维护一个有序的数据结构,在内存上实现数据有序要简单得多,而且具备较高的读写性能,常见的有序数据结构有红黑树、AVL树、跳表等,不管你插入的顺序如何,读出来的数据总是有序的。MemTable正是LSM维护在内存中的一个有序的数据结构,接下来我们看下LSM是如何利用Memtable做到同时兼顾SSTable的有序行和写入性能的:
1、当写入请求过来时,先将record写入到Memtable中,这样就能保证record在内存中有序了,而且具备较高的写入性能。
2、当Memtable的大小达到一定的阈值后(通常是几个Mb的大小),将MemTable转成Immutable MemTable(一个只读不写的MemTable),并创建新的MemTable接收写请求。
和《从Hash索引到LSM树(一)》中的segment file机制类似,一个时刻只有current segment file接收写请求,其他的只读不写。
3、通过后台任务,定时将Immutable MemTable的数据刷到SSTable中,因为Immutable MemTable本身的有序性,所以就能保证SSTable中的数据是有序的,而且数据写入SSTable文件时完全是顺序写入,做到了有序性和写入性能的兼顾。
4、当读请求过来时,查找的顺序是MemTable->Immutable MemTable->SSTable,找到则返回,否则一步步执行下去。
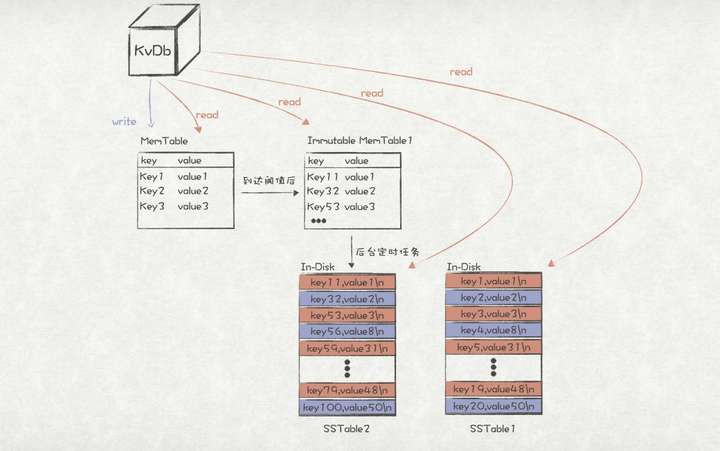
Memtable同时兼顾有序和写性能
Memtable底层通常采用跳表来实现(LevelDB、HBase都采用了这一实现方法),相比较AVL和红黑树,跳表在插入数据的时候可以避免频繁的树节点调整操作,所以写入效率很高,而且实现起来也更简单些。
// LSM维护在内存中的有序数据结构,数据写入时先写MemTable public class MemTable { // 基于跳表实现的key-value结构 private final ConcurrentSkipListMap<String, String> cache; // 当前存储数据的大小 private AtomicInteger size; ... // 查找key public String get(String key) { if (!cache.containsKey(key)) { return ""; } return cache.get(key); } // 添加key:value,并更新当前Memtable的大小 public void add(String key, String value) { cache.put(key, value); size.addAndGet(key.length() + value.length()); } // 返回当前Memtable的大小(字节为单位) // 用于判断达到阈值之后,转成Immutable MemTable public int size() { return this.size.get(); } // 达到阈值之后转储到SSTable public void compact2Sst(SSTable sst) { cache.forEach(sst::add); } ... }
LsmKvDb
使用LSM树作为存储引擎的数据库,通常对SSTable进行分层管理,方便查询以及后续的Compact操作。本文也将采用对SSTable进行分层的架构实现LsmKvDb。
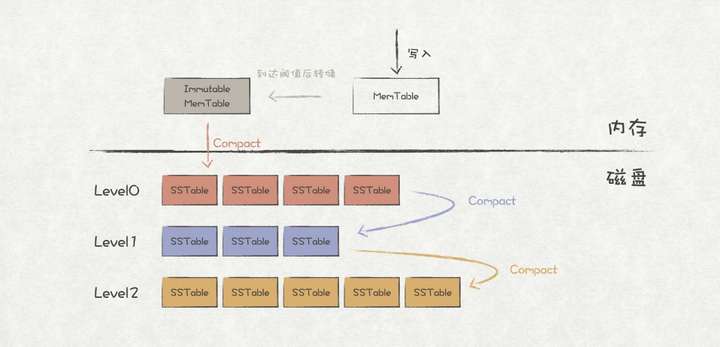
LsmKvDb存储架构
首先对Level进行抽象,每个Level都由多个SSTable组成:
// 对LSM的层的抽象,由SSTable组成 public class Level { private final List<SSTable> ssts; ... public void add(SSTable sst) { ssts.add(sst); } // 在当前level总查找key对应的value, 从老到新遍历所有SSTable public String find(String key) { for (int i = ssts.size() - 1; i >= 0; i--) { String value = ssts.get(i).get(key); if (!value.equals("")) { return value; } } return ""; } // sst与当前level进行compact操作 public void compactWith(SSTable sst) {...} // 对给定sst集合与当前level进行compact操作 public void compactWith(List<SSTable> ssts) {...} }
LsmKvDb的实现代码如下,写数据时写入MemTable,当达到阈值后转Immutable MemTable。Immutable MemTable与MemTable具有相同的数据结构,唯一不同的是前者只读不写,后者既读也写。
/** * 基于LSM树的key-value数据库, 采用分层架构 * MemTable -> Immutable MemTable -> Level0 -> Level1 -> Level2 */ public class LsmKvDb implements KvDb { ... // 存储SSTable的目录 private final String sstDir; // 当前写入的MemTable private MemTable memTable; // MemTable到达阈值大小后转储到immutableMts private final List<MemTable> immutableMts; // 后台定时将immutableMts中的MemTable刷到Level0,各SSTable之间可能由Key重叠 private final Level level0; // 后台定时将Level0中的SSTable与Level1中的进行合并 private final Level level1; // 当Level1中的SSTable的数量到达一定阈值后,选择最老的SSTable与Level2中的进行合并 private final Level level2; ... @Override public String get(String key) { // step1: 从MemTable中读取 String value = memTable.get(key); if (!value.equals("")) { return value; } // step2: 从Immutable MemTable中读取,从新到老 for (int i = immutableMts.size() - 1; i >= 0; i--) { value = immutableMts.get(i).get(key); if (!value.equals("")) { return value; } } // step3: 从Level0中读取 value = level0.find(key); if (!value.equals("")) { return value; } // step4: 从Level1中读取 ... // step5: 从Level2中读取 ... return ""; } @Override public void set(String key, String value) { memTable.add(key, value); // 当MemTable大小到达阈值后转成Immutable MemTable if (memTable.size() > MEMTABLE_MAX_SIZE) { synchronized (this) { immutableMts.add(memTable); memTable = MemTable.create(); } } } ... }
Compaction
在文章《从Hash索引到LSM树(一)》已经对Compaction机制已经有了讲解,其目的是清除掉已经被覆写或删除了的纪录,避免数据存储文件无休止的增长下去。对于LSM树而言,该机制同样适用,随着数据的不断添加、更新和删除,一些SSTable之间必然存在着重叠的key或被删除的key。通过Compaction,可以将多个SSTable合并成一个,从而节省了磁盘空间。
在上篇文章中,对segment file的compact操作主要依赖于Hash索引。因为是索引覆盖全部的key,所以可以很容易通过新的segment file的Hash索引来判断该key是否已经被处理过。但对于SSTable而言,并没有覆盖全部key的Hash索引,那么如何进行compact才高效呢?
得益于SSTable的有序性,我们可以应用归并排序算法来进行compact操作!
LSM树的Compaction通常有三种类型,分别是minor compact、major compact和full compact。
Minor Compact
minor compact指的是将Immutable MemTable中的数据直接转存到Level0中的SSTable。
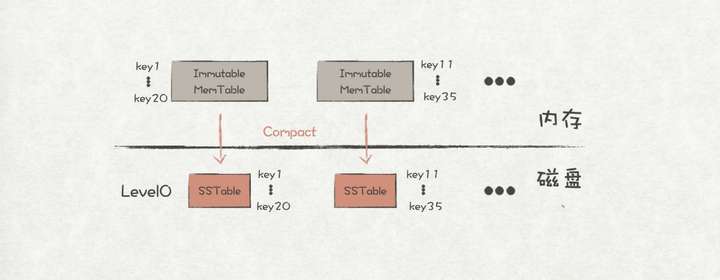
minor compact
因为是直接将各个Immutable MemTable的数据转储成SSTable,并没有做合并的操作,因此在Level0中,各个SSTable之间的key可能存在重叠的现象。
Major Compact
major compact指的是将Level n中的SSTable合并到Level n+1中。
Level0 -> Level1的合并步骤如下:
1、选中Level0中的最老的SSTable sst0,然后在Level0中找到与sst0 的key存在重叠的所有SSTable sst0...n。
2、在Level1中,选取所有与 sst0...n存在key重叠的SSTable sst'0...m。
3、对sst0...n和sst'0...m采用多路归并排序算法进行合并,得到新的sst‘’0...k,并存储在Level1中。
4、删除sst0...n和sst'0...m。
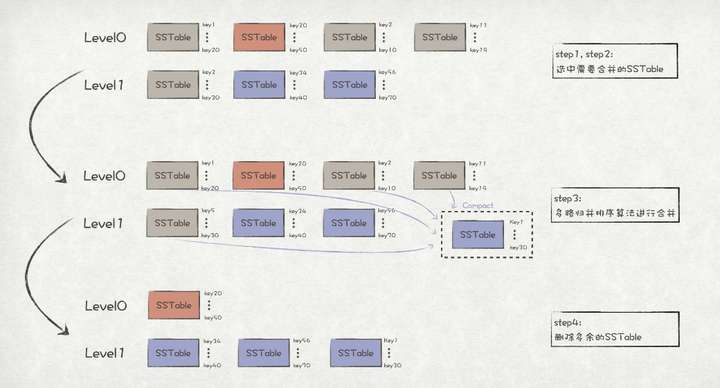
major compact Level0 -> Level1
不同于Level0,Level1和Level2中各个SSTable之间并不存在key重叠的现象,因此Level1 -> Level2的合并会稍微简单些。
Level1 -> Level2的合并步骤如下:
1、选中Level1中的最老的SSTable sst0。
2、在Level2中,选取所有与 sst0存在key重叠的SSTable sst'0...m。
3、对sst0和sst'0...m采用多路归并排序算法进行合并,得到新的sst''0...k,并存储在Level2中。
4、删除sst0和sst'0...m。
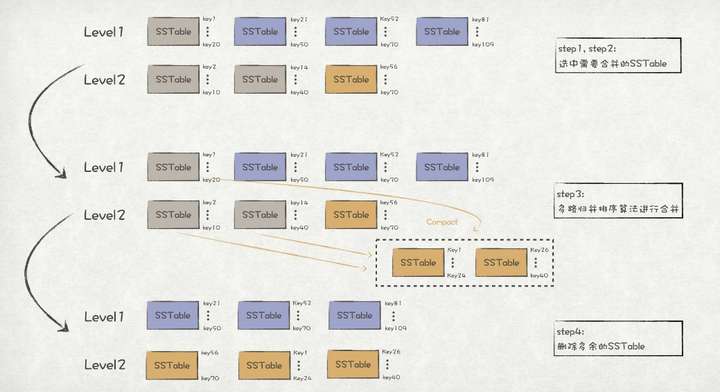
major compact Level1 -> Level2
Full Compact
full compact指的是对Level0、Level1、Level2中所有的SSTable进行compact操作,同样也是采用多路归并排序算法。
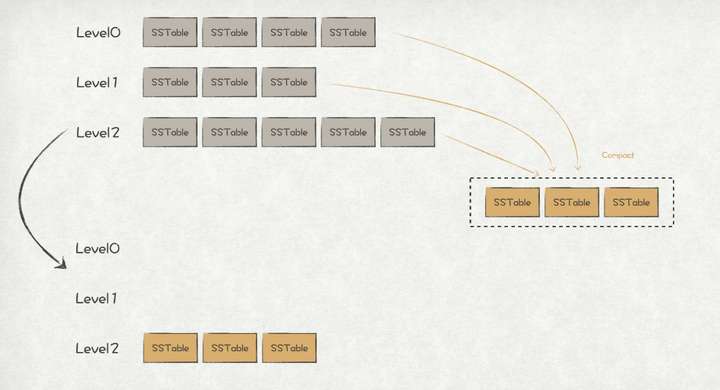
full compact
通常full compact耗时较多,所以一般都会选择在流量较少的时刻进行。
优化LSM树
为SSTable引入block
到目前为止,对于在一个SSTable中查找一个key,我们首先会根据min key和max key判断该key是否属于该SSTable所属的范围,如果属于,则对SSTable采用二分查找法进行搜索。二分查找之所以在LsmKvDb中行得通,是因为这是一个简单的SSTable实现 —— 数据按string存储和\n分隔。在实际的运用中,为了尽可能地利用磁盘空间,SSTable中数据通常都是以字节码的形式存储,也不会以\n分隔每条record,这种情况下采用二分查找的实现就比较复杂了,而且效率也会太高。
一个常见的优化方法是,在SSTable中对record按照一定的size组织成多个block,并以block为单位进行压缩。为了能够快速找到某个key所属的block,需要在内存中维护每个block的起始key对应在SSTable中的offset(一个稀疏的Hash索引)。
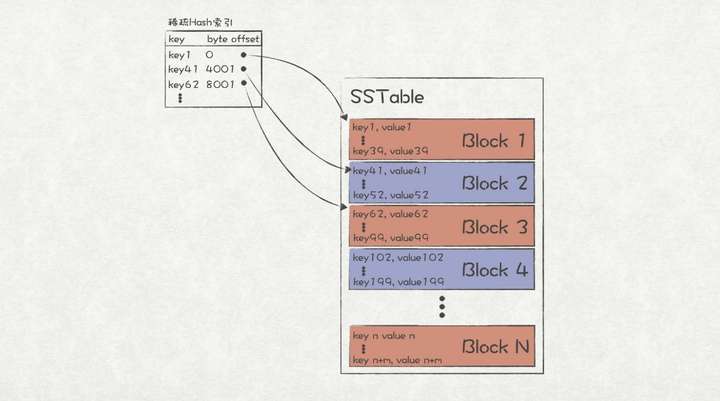
按block存储的SSTable
在查找key的步骤如下:
1、根据索引定位到key所属的block。
2、将该block加载到内存中,并解压。
3、对内存中的数据采用二分查找。
在设计block的大小时,应该利用磁盘的空间局部性原理,使得系统能够只花费一次磁盘I/O就能将整个block加载到内存中。
为SSTable引入Bloom Filter
其实当目标key属于某个SSTable的key范围时,该key也不一定会存在于该SSTable中。但是到目前为止,只要目标key在某个SSTable的范围内,LsmKvDb都会进行查找操作。随着系统中的SSTable数目的增多,查询效率必然会随之下降。
一个常见的优化方法时,为SSTable引入布隆过滤器Bloom Filter。
Bloom Filter是保存在内存中的一种数据结构,可以用来告诉你 “某样东西一定不存在或者可能存在”。它由一个超长的二进制位数组和一系列的Hash函数组成。二进制位数组初始全部为0,当有元素加入集合时,这个元素会被一系列Hash函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。如果需要判断某个元素是否存在于集合当中,只需判断该元素被Hash后的值在数组中的值,如果存在为0的,则该元素一定不存在;如果全为1,则可能存在,这种情况可能有误判。
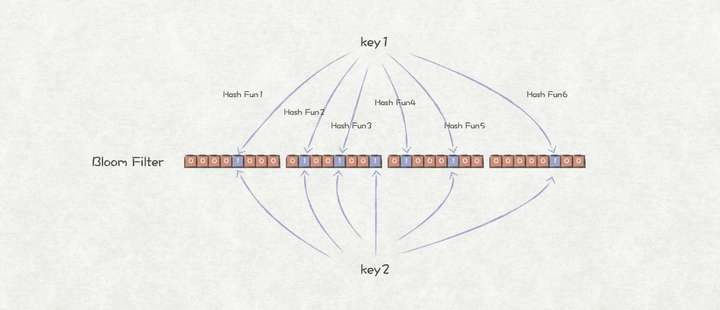
Bloom Filter
通过Bloom Filter,我们可以很快就能判断目标key是否不存在于SSTable中,从而提升了读性能。
Google的Guava库就提供了一个BloomFilter的实现,并且可以按需来设置误判率。
总结
本文承接上《从Hash索引到LSM树(一)》,主要介绍了LSM树的基本原理,并且在原来append-only log的基础上实现了一个简单的基于LSM树的key-value数据库LsmKvDb。LSM树主要由MemTable、Immutable MemTable、SSTable组成,其中MemTable和Immutable MemTable在内存中维护,而SSTable则存储在磁盘中。SSTable的有序性使得LSM树在无需Hash索引的情况下具有不错的读取性能,而且支持区间查询;而Memable则使得LSM树具备很高的写入性能。
本系列文章,我们从一个最简单的key-value数据库起步,一步步通过Hash索引、LSM树、布隆过滤器等技术手段对其进行了优化,从中也深入分析了各个技术点的实现原理。但数据库的索引技术远不止这些,比如最常用到的B/B+树,也是非常值得深入学习的,以后有机会再对其进行深入分析~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号