十八般武艺玩转GaussDB(DWS)性能调优:Plan hint运用
摘要:本文介绍GaussDB(DWS)另一种可以人工干预计划生成的功能--plan hint。
前言
数据库的使用者在书写SQL语句时,会根据自己已知的情况尽力写出性能很高的SQL语句。但是当需要写大量SQL语句,且有些SQL语句的逻辑极为复杂时,数据库使用者就很难写出性能较高的SQL语句。
而每个数据库都有一个类似人的大脑的查询优化器模块,它接收来自语法分析模块传递过来的查询树,在这个查询树的基础上进行逻辑上的等价变换、物理执行路径的筛选,并且把选择出的最优的执行路径传递给数据库的执行器模块。查询优化器是提升查询效率非常重要的一个手段。
数据库查询优化器的分类详见博文《GaussDB(DWS)性能调优系列基础篇一:万物之始analyze统计信息》。
Plan hint的引入
由于优化器基于统计信息和估算模型生成计划,当估算出现偏差时,计划可能出现问题,性能较差,使语句的执行变得奇慢无比。
通常,查询优化器的优化过程对数据库使用者是透明的。在上一篇博文《GaussDB(DWS)性能调优系列实战篇五:十八般武艺之路径干预》中,Gauss DB(DWS)提供了可通过配置GUC参数的方式,全局的干预查询计划的路径生成。本次,将介绍另一种可以人工干预计划生成的功能--plan hint。Hint是一种通过SQL语句中的注释传递给优化器的指令,优化器使用hint为语句选择执行计划。在测试或开发环境中,hint对于测试特定访问路径的性能非常有用。例如,您可能知道某些表优先进行连接,可以有效减少中间结果集大小,在这种情况下,可以使用提示来指示优化器使用更好的执行计划。
Plan hint功能属于语句级的调控,仅对当前语句的当前层次生效,可以帮助我们在调优的过程中,针对特定的语句,通过plan hint进行人工干预,选择更高效的执行计划。
GaussDB(DWS)的Plan hint有以下种类:
- Join顺序的hint:调整join顺序
- Scan/Join方法的hint:指定或避免scan/join的方法
- Stream方法的hint:指定或避免redistribute/broadcast
- 行数hint:对于给定结果集,指定行数,或对原有估算值进行计算调整
- 倾斜值hint:在倾斜优化时,指定需要倾斜处理的特殊值
下面分别对以上几种plan hint的功能及其在实际中的运用做一下介绍。在下面几节的介绍中,除倾斜值hint外,都以tpcds中的Q6作为示例。为了能明显看到hint在查询优化过程中的作用,我们将store_sales表的统计信息删除。原始语句和生成的初始计划如下。
示例语句:
explain performance select a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
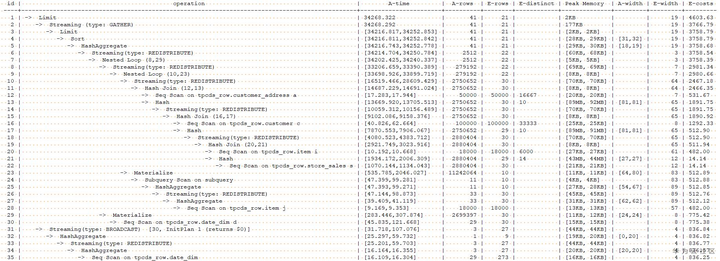
Plan hint的应用
Join 顺序的hint
语法:
格式1:
leading(table_list)
仅指定join顺序,不指定内外表顺序
格式2:
leading((table_list))
同时指定join顺序和内外表顺序,内外表顺序仅在最外层生效
说明:
table_list为要调整join顺序的表名列表,表之间使用空格分隔。可以包含当前层的任意个表(别名),或对于子查询提升的场景,也可以包含子查询的hint别名,同时任意表可以使用括号指定优先级。
注意:
- 表只能用单个字符串表示,不能带schema。
- 表如果存在别名,需要优先使用别名来表示该表。
- list中的表在当前层或提升的子查询中必须是唯一的。如果不唯一,需要使用不同的别名进行区分。
- 同一个表只能在list里出现一次。
示例1:
对于示例中的计划,可以看出,17-22号算子时store_sales表和item表join后生成hash表,store_sales表的数据量很大,store_sales和item表join后未过滤掉任何数据,所以这两个表join并生成hash表的时间都比较长。根据对tpcds各表中数据分布的了解,我们知道,store_sales表和date_dim进行join,可以过滤掉较多数据,所以,可以使用hint来提示优化器优将store_sales表和date_dim表先进行join,store_sales作为外表,date_dim作为内表,减少中间结果集大小。语句改写如下:
explain performance select /*+ leading((s d)) */ a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
增加了join顺序hint的查询计划如下:
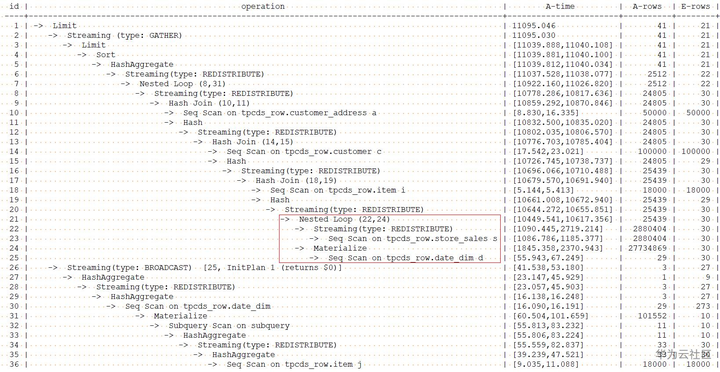
通过调整join顺序,使得之后各join的中间结果集都大幅减少,执行时间由34268.322ms降为11095.046ms。
Scan/Join方法的hint
用于指示优化器使用那种scan方法或join方法。
语法:
Join方法的hint格式:
[no] nestloop|hashjoin|mergejoin(table_list)
Scan方法的hint格式:
[no] tablescan|indexscan|indexonlyscan(table [index])
说明:
- no表示提示优化器不使用这种方法。
- table表示hint指定的表,只能指定一个表,如果表存在别名应优先使用别名进行hint。
- index表示使用indexscan或indexonlyscan的hint时,指定的索引名称,当前只能指定一个。
示例2-1:
示例1中得到的执行计划,由于store_sales表的行数估算不准,store_sales和date_dim采用了效率不好的nestloop方式进行join。现在通过本节的hint方法来指示优化器不使用nestloop方式进行join。
explain performance select /*+ leading((s d)) no nestloop(s d) */ a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
增加了join方式hint后的计划如下:
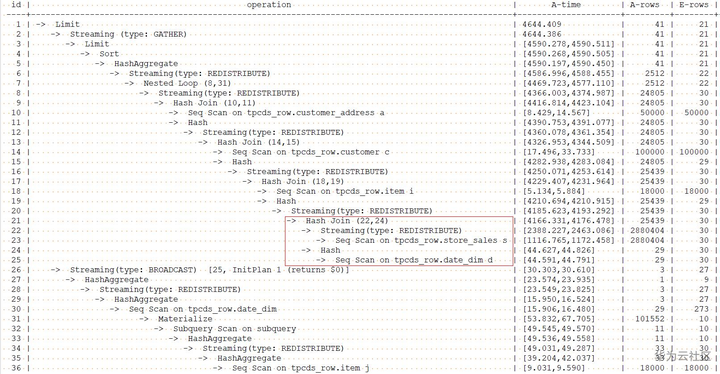
从上面的计划中可以看到,优化器对store_sales和date_dim表之间的join方法已经由nestloop改为了hashjoin,且这条语句的执行时间也由11095.046ms降为4644.409ms。
示例2-2:
为了演示scan方式的hint使用,如下在item表的i_item_sk列上创建一个名称为i_item的索引。
create index i_item on item(i_item_sk);
通过下面的语句指示优化器访问别名为i的item表时,使用索引i_item做索引扫描。
explain performance select /*+ leading((s d)) no nestloop(s d) indexscan(i i_item) */ a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
使用scan的hint指示扫描item表时采用indexscan后的查询计划如下:
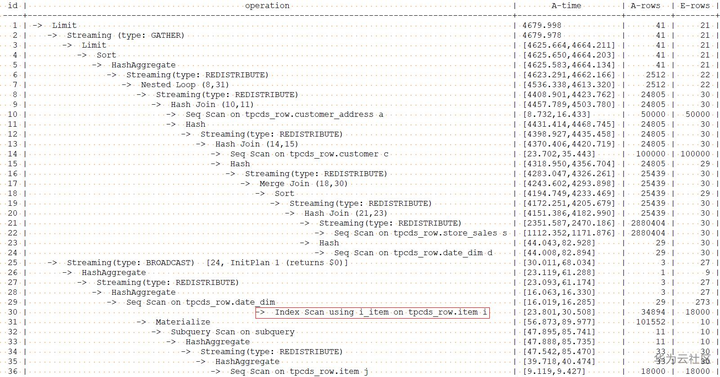
从上面的执行结果看,使用索引扫描后(s 和 d join后,再和item的join采用了mergejoin方式)反而使性能略有下降,所以后面的用例中,我们将不对item表采用索引扫描的方法。
Stream方法的hint
用于指示优化器采用哪种stream方法,可以为broadcast和redistribute。
语法:
[no] broadcast|redistribute(table_list)
说明:
- no表示不使用hint的stream方式。
- table_list为进行stream操作的单表或多表join结果集
示例3:
此处作为演示,修改语句如下,通过hint指示优化器对item表扫描的结果使用broadcast方式进行分布。
explain performance select /*+ leading((s d)) no nestloop(s d) broadcast(i) */ a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i Where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
指示优化器使用broadcast方式分布item结果的查询计划如下:
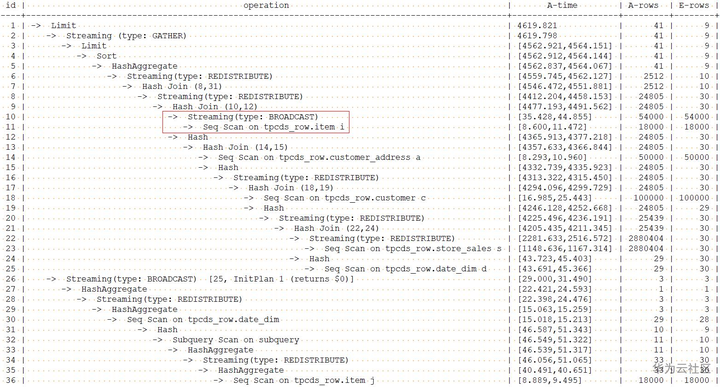
可以看出,之前在item扫描后的结果上是redistribute分布方式,现在已经变为了broadcast分布方式。Broadcast分布方式一般用于数据量比较小的结果集上,相反redistribute用于数据量比较大的结果集上。所以,根据执行计划中单表或表join后的结果集大小,可以通过这种方式,调整结果集的分布方式,从而提升查询的性能。
行数hint
用于指明中间结果集的大小,支持绝对值和相对值的hint。
语法:
rows(table_list #|+|-|* const)
说明:
- #,+,-,*,进行行数估算hint的四种操作符号。#表示直接使用后面的行数进行hint。+,-,*表示对原来估算的行数进行加、减、乘操作,运算后的行数最小值为1行。
- const可以是任意非负数,支持科学计数法。
由于store_sales表没有统计信息,所以在上面的各个计划中可以看到,store_sales表的估计行数和实际行数相差非常大,这就会导致生成了最初的效率比较低的计划。下面我们看看使用行数hint的效果。
示例4:
explain performance select /*+ rows(s #2880404) */ a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i Where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
具体查询计划如下:
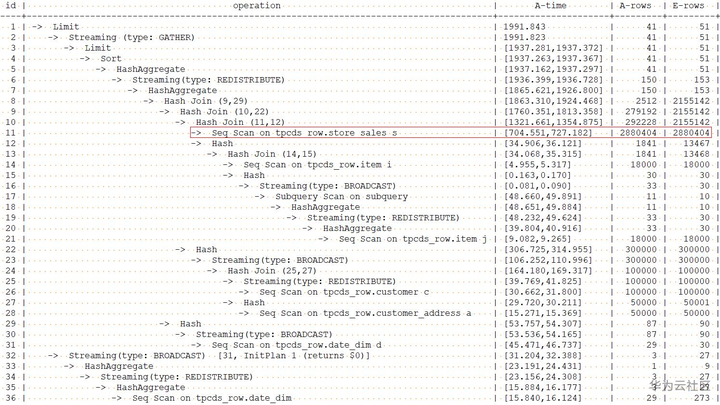
指定了store_sales表的准确行数后,优化器生成的计划执行时间直接从最初的34268.322ms将为1991.843ms,提升了17倍。这也充分的说明了优化器对统计信息准确性的强烈依赖。
除了可以指明单表的行数,还可指明中间结果集的行数。比如上例中8号算子的实际行数和估计行数也相差较大,我们指明8号算子的结果集行数看看效果。在下面这个例子中,还使用了子链接块名的hint,为子链接指定了一个别名,便于在行数hint中指定子链接。
explain performance select /*+ rows(s #2880404) rows(s i tt c a d #2512) */ a.ca_state state, count(*) cnt from customer_address a ,customer c ,store_sales s ,date_dim d ,item i where a.ca_address_sk = c.c_current_addr_sk and c.c_customer_sk = s.ss_customer_sk and s.ss_sold_date_sk = d.d_date_sk and s.ss_item_sk = i.i_item_sk and d.d_month_seq = (select distinct (d_month_seq) from date_dim where d_year = 2000 and d_moy = 2 ) and i.i_current_price > 1.2 * (select /*+ blockname (tt)*/ avg(j.i_current_price) from item j where j.i_category = i.i_category) group by a.ca_state having count(*) >= 10 order by cnt limit 100;
查询计划如下:
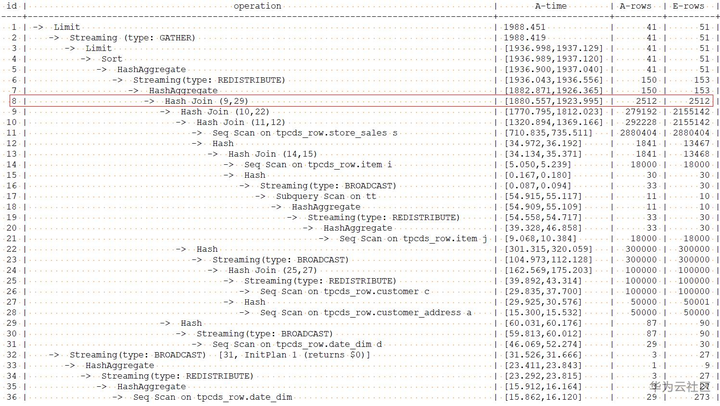
8号算子的估计行数已经和实际行数一致。由于8号算子不是计划的瓶颈点,所以性能提升并不明显。
倾斜值hint
用于指明查询运行时重分布过程中存在倾斜的重分布键和倾斜值,针对Join和HashAgg运算中的重分布进行优化。
语法:
指定单表倾斜
skew(table (column) [(value)])
指定中间结果倾斜
skew((join_rel) (column) [(values)])
说明:
- table表示存在倾斜的单个表名。
- join_rel表示参与join的两个或多个表,如(t1 t2)表示t1和t2 join后的结果存在倾斜。
- column表示倾斜表中存在倾斜的一个或多个列。
- value表示倾斜的列中存在倾斜的一个或多个值。
示例5:
本节,我们用tpcds中的Q1作为示例,未使用hint前的查询及计划如下:
explain performance with customer_total_return as (select sr_customer_sk as ctr_customer_sk ,sr_store_sk as ctr_store_sk ,sum(SR_FEE) as ctr_total_return from store_returns ,date_dim where sr_returned_date_sk = d_date_sk and d_year =2000 group by sr_customer_sk ,sr_store_sk) select c_customer_id from customer_total_return ctr1 ,store ,customer where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2 from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk) and s_store_sk = ctr1.ctr_store_sk and s_state = 'NM' and ctr1.ctr_customer_sk = c_customer_sk order by c_customer_id limit 100;
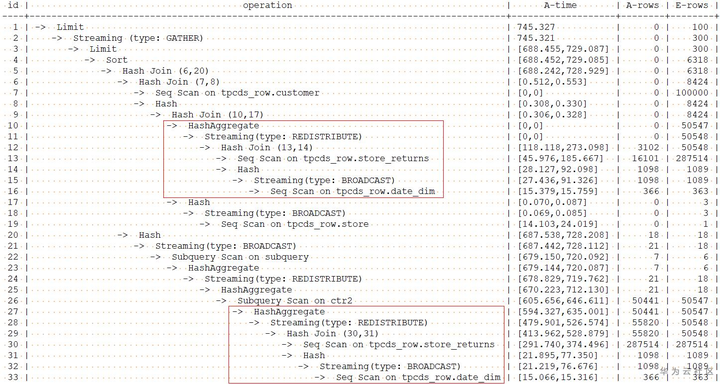
with表达式中group by在做HashAgg中进行重分布时存在倾斜,对应上图中的10和27号算子。对with表达式中的hashagg进行hint指定,查询和计划如下:
explain performance with customer_total_return as (select /*+ skew(store_returns(sr_store_sk sr_customer_sk)) */sr_customer_sk as ctr_customer_sk ,sr_store_sk as ctr_store_sk ,sum(SR_FEE) as ctr_total_return from store_returns ,date_dim where sr_returned_date_sk = d_date_sk and d_year =2000 group by sr_customer_sk ,sr_store_sk) select c_customer_id from customer_total_return ctr1 ,store ,customer where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2 from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk) and s_store_sk = ctr1.ctr_store_sk and s_state = 'NM' and ctr1.ctr_customer_sk = c_customer_sk order by c_customer_id limit 100;
作了倾斜hint的查询计划如下:
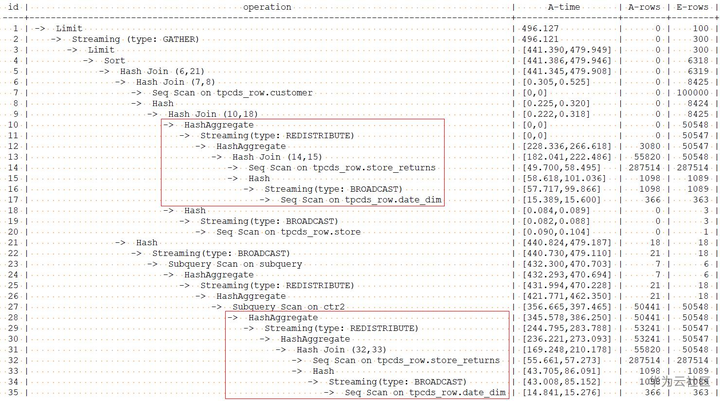
从优化后的计划可以看出:对于HashAgg,由于其重分布存在倾斜,所以优化为双层Agg。
结语
通过上面各节中的示例,展示了Gauss DB(DWS)中plan hint的使用方法,及其对执行计划的影响。数据库使用者结合自己对数据库对象、数据分布情况及数据量等信息的了解,或者根据SQL语句的查询计划分析出其中采用了不正确计划的部分,正确的利用plan hint,提示优化器采用更高效的计划,可以使查询执行的性能获得大幅的提升,成为性能调优的一件有利的工具。
本文分享自华为云社区《GaussDB(DWS)性能调优系列实现篇六:十八般武艺Plan hint运用》,原文作者:wangxiaojuan8 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号