技术干货丨隐私保护下的迁移算法
摘要:本文稍微回顾一下传统迁移算法的流程、特性和局限之处,然后文章介绍几种解决当源域数据有某些访问限制的场景下实现迁移的算法。具体包括:ADDA-CVPR2017,FADA-ICLR2020,SHOT-ICML2020。
本文介绍一种特殊场景下的迁移算法:隐私保护下的迁移算法。首先,本文稍微回顾一下传统迁移算法的流程、特性和局限之处,然后文章介绍几种解决当源域数据有某些访问限制的场景下实现迁移的算法。具体包括:ADDA-CVPR2017,FADA-ICLR2020,SHOT-ICML2020。
传统迁移算法UDDA
首先说明这里说的传统迁移算法,主要指深度域适应(Deep Domain Adaptation),更具体的是无监督深度域适应(Unsupervised Deep Domain Adaptation, UDDA)。因为UDDA是最为常见,也是大家广泛关注的设定,因此这方面的工作远远多于其余迁移算法的设定。
先介绍一下UDDA具体是做什么的:给定一个目标域(Target Domain),该域只有无标记数据,因此不能有监督地训练模型,目标域通常是一个新的局点、场景或者数据集;为了在目标域无标记数据的情况下建立模型,可以借助源域(Source Domain)的知识,源域通常是已有局点、场景或者数据集,知识可以是源域训练好的模型、源域的原始数据、源域的特征等。
借助有标记信息的源域,目标域上即便没有标记数据,也可以建立一个模型。使得该模型对目标域数据有效的关键难点在于源域和目标域存在数据分布的差异,称之为域漂移(Domain Shift),如何去对齐源域和目标域的数据是UDDA解决的主要问题。
UDDA通常包含下面的三种框架:
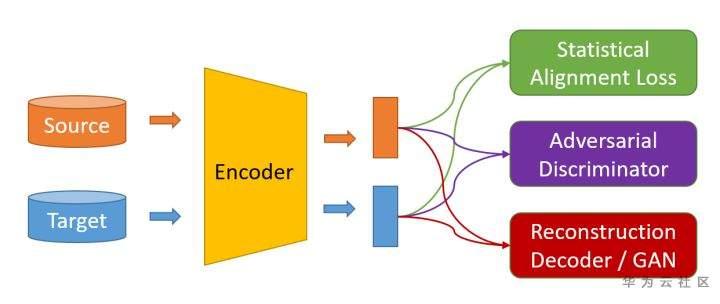
首先,源域和目标域的数据(圆柱)会经过特征提取器(Encoder)提取特征(矩形),然后各种办法会对源域和目标域的特征进行操作,使得源域和目标域上数据的特征对齐。这里值得一提的是,UDDA通常假设源域和目标域的类别是一样的,比如源域和目标域都是去分类0-9十个手写数字,只不过源域和目标域的手写风格不一样。
对源域和目标域特征进行操作的办法包括三种类别:
- 基于统计对齐:使用各种统计量对齐源域和目标域特征的分布,比如对齐核空间均值(MMD Loss)、对齐协方差矩阵(CORAL Loss)等;
- 基于对抗对齐:建立一个域分类器(Domain Classifier)作为判别器(Discriminator),目的要尽可能将源域和目标域的特征区分开来,使用梯度反转(Gradient Reversal Gradient,GRL)可以促使特征提取器提取和领域无关(Domain Invariant)的特征;
- 基于重构对齐:将源域和目标域的特征通过同一个生成网络进行生成相应的数据,通过假设只有分布接近的样本才可以使用同一个网络生成数据对齐源域和目标域特征。
关于以上几种UDDA的具体算法可以参加以前的文章:
https://zhuanlan.zhihu.com/p/205433863zhuanlan.zhihu.com
这里本文只给出UDDA的几个特性:
- 源域数据可获得:UDDA假设源域数据存在并且可以获得;
- 源域目标域数据可混合:UDDA通常假设源域和目标域数据可以在一起处理,即可以放在同一个设备上进行运算;
- 训练预测过程是Transductive的:目标域数据必须和源域数据一同训练才可以使得特征提取器提取领域无关的特征,才可以将源域的模型迁移到目标域,因此当一批新的目标域的数据到来的话,并不能直接使用源域模型进行预测。
总的来说,传统的UDDA方法假设源域数据可获得、源域目标域数据可混合、训练过程Transductive。然而,有一些场景下,源域数据不可获得,或者源域数据不可以外传,这种情况下如何进行迁移呢?
首先,这里需要注意的是,源域数据不能外传和源域数据不可获得是两种情况,前者假设源域数据存在,但是不可以和目标域数据放在一起,后者是源域数据根本就不存在了。
ADDA
ADDA是CVPR2017的一篇工作,来自论文《Adversarial Discriminative Domain Adaptation》。
回归正题,ADDA的训练流程图如下:
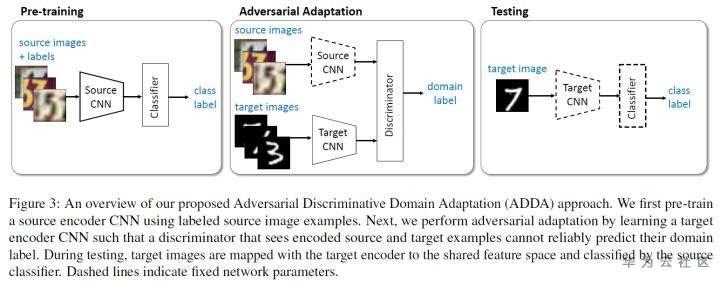
首先是预训练阶段(Pre-training Stage),源域上利用有标记数据训练,采用交叉熵损失:


重复以上两步,直到收敛。

FADA
正如上述介绍的CVL组,Xingchao Peng将ADDA扩充到多域版本,并且提出了FADA。FADA来自ICLR2020的《Federated Adversarial Domain Adaptation》,论文首页截图如下:

该文提出了一个新的场景FADA,即联邦学习下的多域迁移。假设有很多个源域,每个源域的数据分布在单独的设备上,原始数据不能外传,如何在这种情况下将其模型复用到目标域呢?简而言之,如何在数据不能被发送出去的约束下进行特征对齐呢?

FADA总的框架图如下,该框架融合了很多方法,还包括特征解耦(Feature Disentangle)等等,这里不过多介绍。
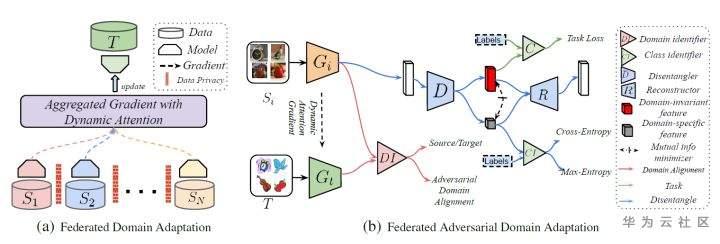
总的来说,FADA将多个源域和目标域的特征发送到一个指定的设备,在该设备上训练一个域判别器,然后将域判别器下发到各个源域作为对抗项促使相应的特征提取器提取领域无关的特征。可以说,FADA是ADDA的多领域扩展版本。
SHOT
SHOT是比较有意思的一篇工作,名称是《Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation》,来自ICML2020,作者信息截图如下:

如果说ADDA和FADA都是假设源域数据不可以被发送出设备的话,SHOT假设源域数据获取不到,即源域数据丢失或者不存在。
那么在只有源域模型和目标域众多无标记数据的情况下,如何迁移呢?SHOT解决了这个问题。首先SHOT指的是Source Hypothesis Transfer,Source Hypothesis指的是源域模型的分类器。SHOT和ADDA有一个一致的地方就是,都固定住了源域模型的分类器,微调源域的特征提取器。ADDA通过对抗损失(假设可以访问到源域数据的特征)进行微调目标域特征提取器,而SHOT则是通过伪标签(Pseudo Label)自监督地训练。


以上就是标签精炼的过程,主要是指使用目标域样本的关系(聚簇结果)来对伪标签进行进一步调整,而不仅仅是利用模型的预测结果。
打了伪标签之后,模型可以根据交叉熵损失进行训练,综合IM损失,可以将模型性能提升至很高。
总结
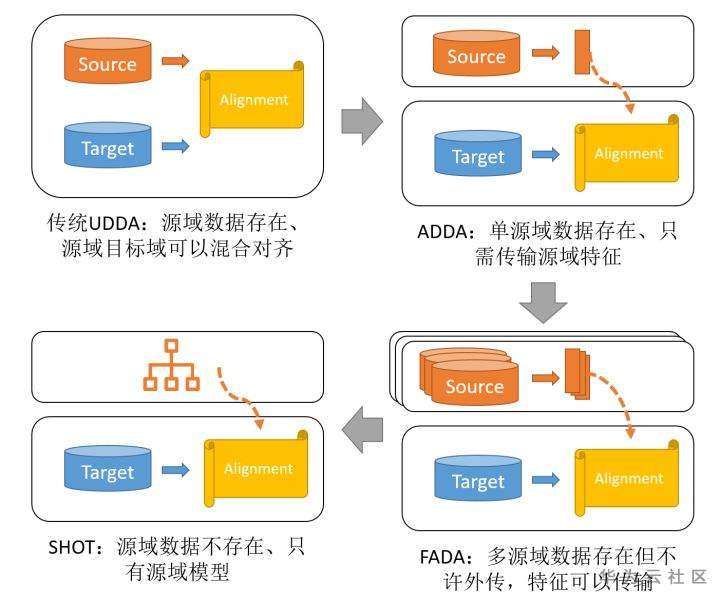
总结一下,传统UDDA以及本文主要介绍的ADDA、FADA和SHOT可以使用下图来区分:
作者信息截图如下:

一作Eric Tzeng来自于加利福尼亚大学伯克利分校,代表作有DDC和ADDA;二作Judy Hoffman来自斯坦福大学,代表作CyCADA,以及多篇在多领域迁移方面的理论文章,比如NeurIPS 2018的《Algorithms and Theory for Multiple-Source Adaptation》;三作Kate Saenko是波斯顿大学计算机科学计算机视觉组(Computer Vision and Learning Group,CVL)的Leader,是一名女性学者,Baochen Sun,Xingchao Peng,Kuniaki Saito等人都在该组深造或者深造过。
CVL代表作有(个人评定,以下文章个人在学习DA的过程中或多或少阅读或者研究过):
- Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020
- Xingchao Peng, Yichen Li, Kate Saenko: Domain2Vec: Domain Embedding for Unsupervised Domain Adaptation. ECCV (6) 2020: 756-774
- Shuhan Tan, Xingchao Peng, Kate Saenko: Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment. CoRR abs/1910.10320 (2019)
- Xingchao Peng, Zijun Huang, Ximeng Sun, Kate Saenko: Domain Agnostic Learning with Disentangled Representations. ICML 2019: 5102-5112
- Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, Bo Wang: Moment Matching for Multi-Source Domain Adaptation. ICCV 2019: 1406-1415
- Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, Kate Saenko: Semi-Supervised Domain Adaptation via Minimax Entropy. ICCV 2019: 8049-8057
- Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, Kate Saenko: Adversarial Dropout Regularization. ICLR (Poster) 2018
- Xingchao Peng, Ben Usman, Neela Kaushik, Dequan Wang, Judy Hoffman, Kate Saenko: VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation. CVPR Workshops 2018: 2021-2026
- Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971
- Baochen Sun, Kate Saenko: Deep CORAL: Correlation Alignment for Deep Domain Adaptation. ECCV Workshops (3) 2016: 443-450
- Baochen Sun, Jiashi Feng, Kate Saenko: Return of Frustratingly Easy Domain Adaptation. AAAI 2016: 2058-2065
- Eric Tzeng, Judy Hoffman, Trevor Darrell, Kate Saenko: Simultaneous Deep Transfer Across Domains and Tasks. ICCV 2015: 4068-4076
参考文献
- Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971
- Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020
- Jian Liang, Dapeng Hu, Jiashi Feng: Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation. CoRR abs/2002.08546 (2020)
本文分享自华为云社区《[技术干货]隐私保护下的迁移算法》,原文作者:就挺突然。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号