

分布式身份:重新定义你的“身份”管理
摘要:随着欧洲通用数据保护条例(GDPR)的实施,基于区块链的分布式身份(Decentralized Identifiers, DID)越来越受到学术界和产业界的关注。究竟什么是分布式身份?其设计原理和实现方式是怎样的?我们可以用它来做什么呢?
相比于上面几个问题,我相信你一定对“为什么需要分布式身份”这个问题更加好奇。
身份模式的演进及特点
在上世纪90年代,互联网被定义为Web1.0。用户与网络的交互非常简单,网站提供的几乎都是“只读”服务,不论文字、图片还是音频内容,用户能做的仅仅是阅读或者简单的搜索,不涉及内容发布和评论对身份没有要求。可见此时的互联网,不具备有实际用途的身份体系。
互联网Web2.0定义了一个可“读写”的网络,在短短十几年时间里,应用类型、服务形式、内容生态均得到飞速发展。与此同时,数字身份体系也被重新定义并不断完善。先后产生了中心化身份、联盟身份和以用户为中心的身份三种身份模式。
不难发现,身份体系变化发展背后的主要推动力就是用户对身份自主控制和自我隐私保护意识的不断增强。
中心化身份的数据由单一的主体负责生成、控制、管理和维护。例如我们熟悉的支付宝、微信等账号。显然,中心化身份的使用权由中心主体和用户共同享有,但身份的生成权、解释权、存储权都集中在身体提供商,由此带来了身份不自主可控、隐私泄漏、可移植性差、互操作性差以及单点风险等一系列问题。
联盟身份的提出一定程度上缓解了上述问题,但没有根本解决。例如,当用户通过微信或支付宝授权,作为第三方账户登录某平台时会面临两类问题。一方面平台还会额外收集用户信息,形成新的独立的身份系统。另一方面由于互联网寡头的垄断,多家身份提供商仍可合谋控制用户的数字身份。
以用户为中心的身份在实践当中由于安全性等种种原因未能广泛推广使用。
分布式身份从根本上解决了上述问题,不依赖于中心身份提供商,真正具备身份的自主可控性、安全性、自解释性、可移植性、互操作性。在分布式场景下赋予每个用户自主控制和使用数字身份的能力,并针对身份数据等敏感信息进行隐私保护。
Web3.0向我们描绘了一个万物互联的可信网络世界,实现了数据的确权与授权、强隐私保护、开放的抗审查的自由数据交换。以DID为基础构建去中心化运行的统一身份认证系统正是Web3.0发展的重要实践之一。
解读分布式身份
接下来我们讨论,什么是分布式身份以及其设计原理和实现方式。
分布式身份的技术架构包括分布式账本、标准的DID协议、标准的可验证凭证协议和以此构建的应用生态。在实现上会基于区块链完成身份的注册、发现,可验证凭证的申请、签发、授予和验证,以及相关数据的隐私存储和可信计算。
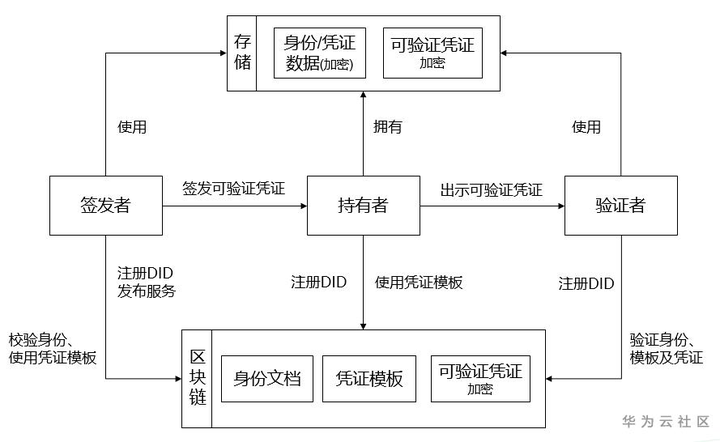
图1. DID系统基本运转流程和使用方式图
为了方便理解DID系统基本的运转流程和使用方式,我绘制了一张图(图1)。从图中可以看出系统主要有三类实体,包括签发者、持有者和验证者,其中每个实体都可以是设备、应用、个人或者组织。
首先,各实体通过简单的密码学工具或者DID SDK生成完全由自己控制的身份文档(具体的数据结构我们后面再展开),并发布到区块链上完成身份的注册。DID文档中还可以包含其所能提供的服务信息,以支持企业用户多样的应用场景。例如签发者是学校A,在其身份文档中可以发布电子学历认证服务;签发者也可以是公司B,在身份文档中声明职位招聘的相关要求。
具备基础的身份标识之后,通过可验证凭证架设起身份与身份之间的认证体系。凭证的模板会由相关主体注册发布到区块链上,并持续维护。接着,持有者便可以向签发者发起认证申请,获得凭证后组合加工出示给验证者完成校验。例如如下场景,小为(持有者)需要向公司B(验证者)发布的职位招聘发起申请,职位要求申请者需要具备本科学历。小为可以将从学校A处申请到的凭证出示给公司B完成职位申请。
最后,业务系统就可以基于DID体系完成上层应用的构建。用户之间无需有信任关系,面向凭证开展业务,细粒度的保护隐私信息。
就这么简单!
有趣的特性和应用场景
知道了为什么和是什么之后,让我们稍微深入一些关键技术的细节,以便更好的运用。
身份文档是DID的基础数据结构,其设计简洁、功能丰富、可扩展性强。为了直观理解,我将关键字段组成的JSON(图2)绘图如下。

图2. 身份文档示意图
列举几个有趣的特性:
- “publicKey”列表可以支持不同秘钥体制和类型的公钥。不同的公钥可用于支持不同的业务。(公钥和私钥是成对出现的两个秘钥。公钥可以公开,私钥必须秘密保存。因为加密和解密使用的是两个不同的秘钥,所以这种算法称之为非对称加密算法。)
- “controller”和”authentication”字段可以是本文档的公钥或者其他DID文档的标识、公钥。这样可以轻松扩展出强大的身份层级控制体系。
- “recovery”恢复标识可以在主控私钥丢失的情况下完成文档恢复和更新。
可验证凭证由元数据(Metadata)、属性声明集合(Claims)和证明材料(Proofs)三部分组成。关键组件及字段见图3. 可验证凭证同样具有丰富的功能和极强的扩展性,其中涉及的能力项有很多,例如生命周期管理、可信模型、零知识证明、隐私频谱、凭证安全等。此处通过介绍“凭证细粒度组合出示”帮助大家感受可验证凭证的功能特性。
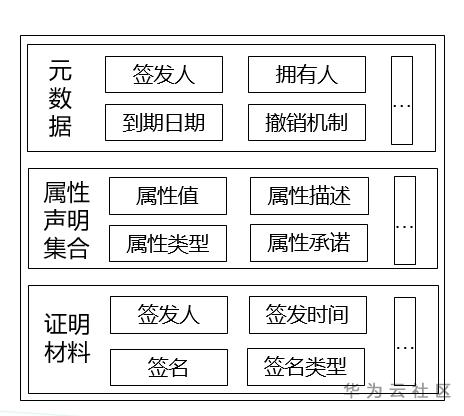
图3. 可验证凭证关键组件及字段
凭证常见的使用模式是签发者对整个凭证的摘要进行签名,并加密将凭证发送给持有者。持有者解密或者重加密凭证,出示给验证者完成校验。显而易见这样的设计会带来两方面问题,一方面是隐私保护能力较差,在出示验证过程中会导致用户无关属性的暴露。另一方面,凭证的使用场景和签发凭证类型耦合在一起,不利于扩展使用场景。
举个例子,前面提到学校A和公司B都发布了各自的“服务”。当小为想申请某个职位时,招聘要求声明应聘者需要是年龄小于30岁的本科毕业生。此时如果小为直接出示身份证(以证明年龄小于30岁)和学历凭证,会暴露例如姓名、籍贯、性别、院校信息等无关属性。如果你向学校申请额外开具一个仅包括学历和年龄的证明,这种方式显然非常低效,并且凭证没有得到复用。
凭证细粒度组合出示的一种实现方式是,签发者计算凭证属性集合中每个属性的“Pedersen 承诺”(用于隐私保护属性信息)。再针对所有承诺进行“C-L签名”(起到多属性签名的聚合效果,压缩签名所占空间)。在凭证出示前,小为可以从已有身份凭证和新获得的学历凭证中挑选服务需要的几个属性公开明文,其余属性均出示密文承诺,完成职位申请。下图是小为申请工作例子的详细流程,大家可以跟着序号和描述梳理梳理。
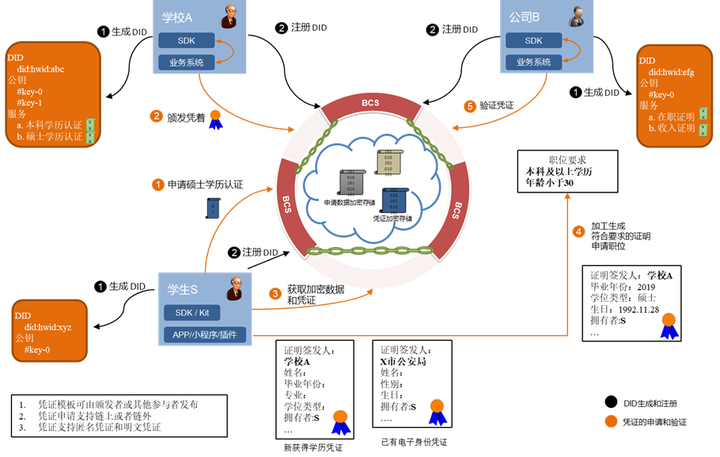
图4. 基于分布式身份的可验证凭证使用示例流程图
至此,我们简答做个总结吧,细节记没记住不重要,领会其精神就好。
本文列举了从Web1.0到Web3.0互联网身份体系的发展变化,随着用户对主权和隐私保护诉求的不断提高,分布式身份和可验证凭证是构建未来统一身份认证体系必不可少的技术。国际上,W3C标准组织与2019年底发布了Decentralized Identifiers(DIDs)v1.0 和 Verifiable Credentials(VC)v1.0 标准规范草案,并持续扩展完善。在国内,2020年6月低分布式数字身份产业联盟(DIDA)成立。
本文介绍了分布式身份基础的数据结构、技术体系架构、主要的功能特性和应用场景。但分布式身份体系所涵盖的内容远比这些要多,他是上层应用生态的身份和认证底座,可以广泛应用到数字政务、民生生活、医疗健康、交通运输、数字金融等领域中。如果你想了解更多细节或者马上动手实际体验一下话,可以打开华为云官网搜索TDIS。
华为云分布式身份服务(Decentralized Identity Service)是一种基于区块链的 分布式数字身份及可验证凭证的注册、签发、管理平台。符合W3C标准规范。为个人和企业用户提供统一的、可自解释的、移植性强的分布式身份标识,同时支持多场景的可验证凭证管理,细粒度的凭证签发和验证,有效解决跨部门、跨企业、跨地域的身份认证难和隐私泄露等问题。

