基于GaussDB(DWS)的全文检索特性,了解一下?
摘要:全文检索是在互联网场景下应用非常广泛的特性,搜索引擎、站内搜索、电商搜索等场景下都会使用到,GaussDB(DWS)同样也支持全文检索功能,是基于GIN索引实现的,下面给大家详细介绍一下GaussDB(DWS)的全文检索特性的功能。
全文检索实现的功能,简单来说就是根据关键字从在全文字段中搜索到相关的信息,在不使用全文检索特性时,只能通过like ‘%keyword%’方式做模糊匹配,无法利用到索引,只能进行全表扫描,效率非常低,全文检索特性可以有效地提升检索性能。
全文检索的基础就是GIN索引,Generalized Inverted Index,也就是通用倒排索引,是一个存储对(key, posting list)集合的索引结构,其中key是一个键值,而posting list 是一组出现过key的位置。如(‘hello', 2,3)中,表示hello在2和3这两个位置出现过。
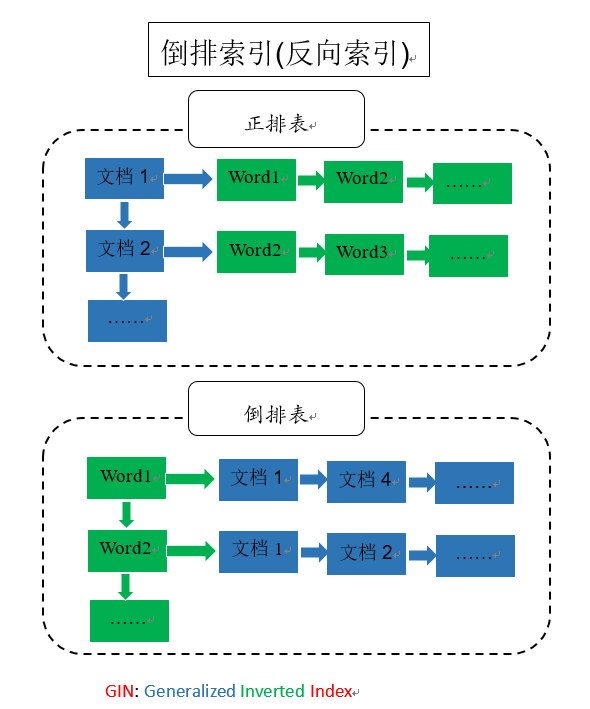
先来了解一下几个接口
to_tsvector
to_tsvector(text, text)
这个函数可以把一个文本转换为一个向量,其中保存单词和其出现的顺序,
test=# SELECT to_tsvector('english', 'huawei cloud data warehouse'); to_tsvector -------------------------------------------- 'cloud':2 'data':3 'huawei':1 'warehous':4 (1 row) test=# SELECT to_tsvector('zhparser', '华为云数据仓库'); to_tsvector ----------------------------------- '云':2 '仓库':4 '华为':1 '数据':3 (1 row)
to_tsquery
to_tsquery(text)
这个函数作用是用来把文本转化为可查询的语句,例如:
SELECT to_tsquery('华为&深圳');
这样就是寻找文本既包含“华为”,也包含“深圳”的语句,&是AND与操作,|是OR或操作
如果想知道一个tsvector是否让tsquery成立,可以使用 @@ 操作符,例如:
SELECT to_tsvector('zhparser', '华为深圳') @@ to_tsquery('华为&深圳');
这条语句会返回True
ts_rank
ts_rank(tsvector, tsquery)
这个函数可以计算tsvector和tsquery的近似程度,通过这个函数计算出rank之后,就可以排序了
SELECT ts_rank( to_tsvector('zhparser', '华为深圳'), to_tsquery('华为&深圳') );
讲完了这些接口,让我们来做一些具体实践:
1.创建数据库
CREATE DATABASE test ENCODING 'utf8' template = template0;
【注意】全文检索必须使用在encoding为utf8或者gbk的数据库上。
2.创建表
CREATE TABLE t1(id int, news text, location text);
3.导入数据
INSERT INTO t1 VALUES(1, '华为云GaussDB(DWS)数据仓库以2048大规模节点通过信通院评测认证,华为云数据仓库成为国内首个单集群突破两千的商用数据仓库产品', '北京'); INSERT INTO t1 VALUES(2, 'GaussDB(DWS)历经十年磨炼,是业界领先的企业级云分布式数据仓库服务', '深圳'); INSERT INTO t1 VALUES(3, '华为GaussDB(DWS)数据仓库,助力招行“人人用数,创新前行,招行客户在华为论坛中表示,华为与招行的联创实验室还将进一步探索云数仓支持OBS存储的实践', '深圳'); INSERT INTO t1 VALUES(4, '数智金融 使能创新,2020 华为 数智金融论坛在溪村成功举办', '东莞'); INSERT INTO t1 VALUES(5, '华为云 AI 训练营西安站:“ModelArts Pro——行业 AI 落地新利器”主题沙龙盛大开幕', '西安');
4.创建索引
CREATE INDEX t1_news_idx ON t1 USING gin(to_tsvector('zhparser', news));
执行查询:
SELECT * FROM t1 WHERE to_tsvector('zhparser',news) @@ to_tsquery('华为');
查询结果:
news中只要包含“华为”词组,都会检索出来
5.创建多字段联合索引:
CREATE INDEX t1_news_location_idx ON t1 USING gin(to_tsvector('zhparser', news||location));
执行结果:
- 查找同时包含两个词组
SELECT * FROM t1 WHERE to_tsvector('zhparser', news||location) @@ to_tsquery('华为 & 深圳');
news跟location只要有一个字段中包含“华为”和“深圳”都会检索出来
test=# SELECT * FROM t1 WHERE to_tsvector('zhparser', news||location) @@ to_tsquery('华为 & 深圳'); id | news | location ----+----------------------------------------------------------------------------------------------------------------------------------------------+---------- 3 | 华为GaussDB(DWS)数据仓库,助力招行“人人用数,创新前行,招行客户在华为论坛中表示,华为与招行的联创实验室还将进一步探索云数仓支持OBS存储的实践 | 深圳 (1 row)
- 查询包含其中一个词组
SELECT * FROM t1 WHERE to_tsvector('zhparser', news||location) @@ to_tsquery('云|深圳');
news跟location只要有一个包含“云”跟“深圳”这两个词的任何一个都会检索出来。
test=# SELECT * FROM t1 WHERE to_tsvector('zhparser', news||location) @@ to_tsquery('云|深圳'); id | news | location ----+----------------------------------------------------------------------------------------------------------------------------------------------+---------- 5 | 华为云 AI 训练营西安站:“ModelArts Pro——行业 AI 落地新利器”主题沙龙盛大开幕 | 西安 3 | 华为GaussDB(DWS)数据仓库,助力招行“人人用数,创新前行,招行客户在华为论坛中表示,华为与招行的联创实验室还将进一步探索云数仓支持OBS存储的实践 | 深圳 1 | 华为云GaussDB(DWS)数据仓库以2048大规模节点通过信通院评测认证,华为云数据仓库成为国内首个单集群突破两千的商用数据仓库产品 | 北京 2 | GaussDB(DWS)历经十年磨炼,是业界领先的企业级云分布式数据仓库服务 | 深圳 (4 rows)
6.排序
- 按照某一列包含的某个词组权重来排序
SELECT id, news, location ,ts_rank_cd(to_tsvector('zhparser',news), query) AS rank FROM t1, to_tsquery('华为') query WHERE query @@ to_tsvector('zhparser',news) order by rank DESC;
执行结果:
test=# SELECT id, news, location ,ts_rank_cd(to_tsvector('zhparser',news), query) AS rank FROM t1, to_tsquery('华为') query WHERE query @@ to_tsvector('zhparser',news) order by rank DESC; id | news | location | rank ----+----------------------------------------------------------------------------------------------------------------------------------------------+----------+------ 3 | 华为GaussDB(DWS)数据仓库,助力招行“人人用数,创新前行,招行客户在华为论坛中表示,华为与招行的联创实验室还将进一步探索云数仓支持OBS存储的实践 | 深圳 | .3 1 | 华为云GaussDB(DWS)数据仓库以2048大规模节点通过信通院评测认证,华为云数据仓库成为国内首个单集群突破两千的商用数据仓库产品 | 北京 | .2 4 | 数智金融 使能创新,2020 华为 数智金融论坛在溪村成功举办 | 东莞 | .1 5 | 华为云 AI 训练营西安站:“ModelArts Pro——行业 AI 落地新利器”主题沙龙盛大开幕 | 西安 | .1 (4 rows)
搜索出含有“华为”的词组,并且根据权重排序
- 按照某一列包含多个词组权重排序(同时包含两个词组)
SELECT id, news, location,ts_rank_cd(to_tsvector('zhparser', news||location), query) AS rank FROM t1, to_tsquery('华为&深圳') query WHERE query @@ to_tsvector('zhparser',news||location) order by rank DESC;
执行结果:
test=# SELECT id, news, location,ts_rank_cd(to_tsvector('zhparser', news||location), query) AS rank FROM t1, to_tsquery('华为&深圳') query WHERE query @@ to_tsvector('zhparser',news||location) order by rank DESC; id | news | location | rank ----+----------------------------------------------------------------------------------------------------------------------------------------------+----------+----------- 3 | 华为GaussDB(DWS)数据仓库,助力招行“人人用数,创新前行,招行客户在华为论坛中表示,华为与招行的联创实验室还将进一步探索云数仓支持OBS存储的实践 | 深圳 | .00555556 (1 row)
搜索出含有“华为”和“深圳”的词组,并且根据权重排序
- 按照某一列包含多个词组权重排序(包含两个词组其中一个)
SELECT id, news, location,ts_rank_cd(to_tsvector('zhparser', news||location), query) AS rank FROM t1, to_tsquery('云|深圳') query WHERE query @@ to_tsvector('zhparser', news||location) order by rank DESC;
查看执行结果:
test=# SELECT id, news, location,ts_rank_cd(to_tsvector('zhparser', news||location), query) AS rank FROM t1, to_tsquery('云|深圳') query WHERE query @@ to_tsvector('zhparser', news||location) order by rank DESC; id | news | location | rank ----+----------------------------------------------------------------------------------------------------------------------------------------------+----------+------ 1 | 华为云GaussDB(DWS)数据仓库以2048大规模节点通过信通院评测认证,华为云数据仓库成为国内首个单集群突破两千的商用数据仓库产品 | 北京 | .2 2 | GaussDB(DWS)历经十年磨炼,是业界领先的企业级云分布式数据仓库服务 | 深圳 | .2 5 | 华为云 AI 训练营西安站:“ModelArts Pro——行业 AI 落地新利器”主题沙龙盛大开幕 | 西安 | .1 3 | 华为GaussDB(DWS)数据仓库,助力招行“人人用数,创新前行,招行客户在华为论坛中表示,华为与招行的联创实验室还将进一步探索云数仓支持OBS存储的实践 | 深圳 | .1 (4 rows)
检索出包含“云”或者“深圳”的记录,并且根据权重排序。
通过以上的案例,相信大家对GaussDB(DWS)的全文检索使用已经有了一些了解,其实全文检索还有ngram分词,和自定义词典等等其他用法,大家如果有兴趣,可以访问DWS产品文档或者到社区提问,获取更全面的解答。
本文分享自华为云社区《GaussDB(DWS)全文检索特性初探》,原文作者:DWS_Jack 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号