Rust太难?那是你没看到这套Rust语言学习万字指南!
摘要:从开发环境、语法、属性、内存管理和Unicode等五部分,为你带来一份详细的Rust语言学习的精华总结内容。
一、Rust开发环境指南
1.1 Rust代码执行
根据编译原理知识,编译器不是直接将源语言翻译为目标语言,而是翻译为一种“中间语言”,编译器从业人员称之为“IR”--指令集,之后再由中间语言,利用后端程序和设备翻译为目标平台的汇编语言。
Rust代码执行:
1) Rust代码经过分词和解析,生成AST(抽象语法树)。
2) 然后把AST进一步简化处理为HIR(High-level IR),目的是让编译器更方便的做类型检查。
3) HIR会进一步被编译为MIR(Middle IR),这是一种中间表示,主要目的是:
a) 缩短编译时间;
b) 缩短执行时间;
c) 更精确的类型检查。
4) 最终MIR会被翻译为LLVM IR,然后被LLVM的处理编译为能在各个平台上运行的目标机器码。
Ø IR:中间语言
Ø HIR:高级中间语言
Ø MIR:中级中间语言
Ø LLVM :Low Level Virtual Machine,底层虚拟机。
LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time)
无疑,不同编译器的中间语言IR是不一样的,而IR可以说是集中体现了这款编译器的特征:他的算法,优化方式,汇编流程等等,想要完全掌握某种编译器的工作和运行原理,分析和学习这款编译器的中间语言无疑是重要手段。
由于中间语言相当于一款编译器前端和后端的“桥梁”,如果我们想进行基于LLVM的后端移植,无疑需要开发出对应目标平台的编译器后端,想要顺利完成这一工作,透彻了解LLVM的中间语言无疑是非常必要的工作。
LLVM相对于gcc的一大改进就是大大提高了中间语言的生成效率和可读性, LLVM的中间语言是一种介于c语言和汇编语言的格式,他既有高级语言的可读性,又能比较全面地反映计算机底层数据的运算和传输的情况,精炼而又高效。
1.1.1 MIR
MIR是基于控制流图(Control Flow Graph,CFG)的抽象数据结构,它用有向图(DAG)形式包含了程序执行过程中所有可能的流程。所以将基于MIR的借用检查称为非词法作用域的生命周期。
MIR由一下关键部分组成:
- l
基本块(Basic block,bb),他是控制流图的基本单位,
Ø 语句(statement)
Ø 终止句(Terminator)
- l
本地变量,占中内存的位置,比如函数参数、局部变量等。 - l
位置(Place),在内存中标识未知的额表达式。 - l
右值(RValue),产生值的表达式。
具体的工作原理见《Rust编程之道》的第158和159页。
可以在http://play.runst-lang.org中生成MIR代码。
1.1 Rust安装
Ø 方法一:见Rust官方的installation章节介绍。
实际上就是调用该命令来安装即可:curl https://sh.rustup.rs -sSf | sh
Ø 方法二:下载离线的安装包来安装,具体的可见Rust官方的Other Rust Installation Methods章节。
1.2 Rust编译&运行
1.2.1 Cargo包管理
Cargo是Rust中的包管理工具,第三方包叫做crate。
Cargo一共做了四件事:
- l 使用两个元数据(
metadata)文件来记录各种项目信息 - l 获取并构建项目的依赖关系
- l 使用正确的参数调用
rustc或其他构建工具来构建项目 - l 为Rust生态系统开发建议了统一标准的工作流
Cargo文件:
- l
Cargo.lock:只记录依赖包的详细信息,不需要开发者维护,而是由Cargo自动维护 - l
Cargo.toml:描述项目所需要的各种信息,包括第三方包的依赖
cargo编译默认为Debug模式,在该模式下编译器不会对代码进行任何优化。也可以使用--release参数来使用发布模式。release模式,编译器会对代码进行优化,使得编译时间变慢,但是代码运行速度会变快。
官方编译器rustc,负责将rust源码编译为可执行的文件或其他文件(.a、.so、.lib等)。例如:rustc box.rs
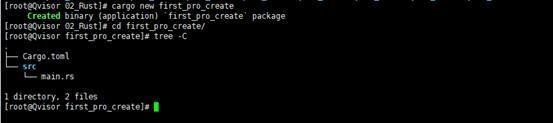
Rust还提供了包管理器Cargo来管理整个工作流程。例如:
lcargo newfirst_pro_create:创建名为first_pro_create的项目lcargo new --libfirst_lib_create:创建命令first_lib_create的库项目lcargo doclcargo doc --openlcargo testlcargo test -- --test-threads=1lcargo buildlcargo build --releaselcargo runlcargo install --pathlcargo uninstallfirst_pro_createlcargo new –bin use_regex
1.2.2 使用第三方包
Rust可以在Cargo.toml中的[dependencies]下添加想依赖的包来使用第三方包。
然后在src/main.rs或src/lib.rs文件中,使用extern crate命令声明引入该包即可使用。
例如:
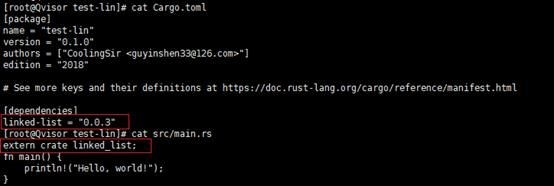
值得注意的是,使用extern crate声明包的名称是linked_list,用的是下划线“_”,而在Cargo.toml中用的是连字符“-”。其实Cargo默认会把连字符转换成下划线。
Rust也不建议以“-rs”或“_rs”为后缀来命名包名,而且会强制性的将此后缀去掉。
具体的见《Rust编程之道》的第323页。
1.4 Rust常用命令
1.5 Rust命令规范
Ø 函数: 蛇形命名法(snake_case),例如:func_name()
Ø 文件名: 蛇形命名法(snake_case),例如file_name.rs、main.rs
Ø 临时变量名:蛇形命名法(snake_case)
Ø 全局变量名:
Ø 结构体: 大驼峰命名法,例如:struct FirstName { name: String}
Ø enum类型: 大驼峰命名法。
Ø 关联常量:常量名必须全部大写。什么是关联常量见《Rust编程之道》的第221页。
Ø Cargo默认会把连字符“-”转换成下划线“_”。
Ø Rust也不建议以“-rs”或“_rs”为后缀来命名包名,而且会强制性的将此后缀去掉。
二、Rust语法
2.1 疑问&总结
2.1.1 Copy语义 && Move语义(Move语义必须转移所有权)
类型越来越丰富,值类型和引用类型难以描述全部情况,所以引入了:
Ø 值语义(Value Semantic)
复制以后,两个数据对象拥有的存储空间是独立的,互不影响。
基本的原生类型都是值语义,这些类型也被称为POD(Plain old data)。POD类型都是值语义,但是值语义类型并不一定都是POD类型。
具有值语义的原生类型,在其作为右值进行赋值操作时,编译器会对其进行按位复制。
Ø 引用语义(Reference Semantic)
复制以后,两个数据对象互为别名。操作其中任意一个数据对象,则会影响另外一个。
智能指针Box<T>封装了原生指针,是典型的引用类型。Box<T>无法实现Copy,意味着它被rust标记为了引用语义,禁止按位复制。
引用语义类型不能实现Copy,但可以实现Clone的clone方法,以实现深复制。
在Rust中,可以通过是否实现Copy trait来区分数据类型的值语义和引用语义。但为了更加精准,Rust也引用了新的语义:复制(Copy)语义和移动(Move)语义。
Ø Copy语义:对应值语义,即实现了Copy的类型在进行按位复制时是安全的。
Ø Move语义:对应引用语义。在Rust中不允许按位复制,只允许移动所有权。
2.1.2 哪些实现了Copy
Ø 结构体 :当成员都是复制语义类型时,不会自动实现Copy。
Ø 枚举体 :当成员都是复制语义类型时,不会自动实现Copy。
结构体 && 枚举体:
1) 所有成员都是复制语义类型时,需要添加属性#[derive(Debug,Copy,Clone)]来实现Copy。
2) 如果有移动语义类型的成员,则无法实现Copy。
Ø 元组类型 :本身实现了Copy。如果元素均为复制语义类型,则默认是按位复制,否则执行移动语义。
Ø 字符串字面量 &str: 支持按位复制。例如:c = “hello”; 则c就是字符串字面量。
2.1.3 哪些未实现Copy
Ø 字符串对象String :to_string() 可以将字符串字面量转换为字符串对象。
2.1.4 哪些实现了Copy trait
Ø 原生整数类型
对于实现Copy的类型,其clone方法只需要简单的实现按位复制即可。
2.1.5 哪些未实现Copy trait
Ø Box<T>
实现了Copy trait,有什么作用?
实现Copy trait的类型同时拥有复制语义,在进行赋值或者传入函数等操作时,默认会进行按位复制。
Ø 对于默认可以安全的在栈上进行按位复制的类型,就只需要按位复制,也方便管理内存。
Ø 对于默认只可在堆上存储的数据,必须进行深度复制。深度复制需要在堆内存中重新开辟空间,这会带来更多的性能开销。
2.1.6 哪些是在栈上的?哪些是在堆上的?
2.1.7 let绑定
Ø Rust声明的绑定默认为不可变。
Ø 如果需要修改,可以用mut来声明绑定是可变的。
2.2 数据类型
很多编程语言中的数据类型是分为两类:
Ø 值类型
一般是指可以将数据都保存在同一位置的类型。例如数值、布尔值、结构体等都是值类型。
值类型有:
l原生类型l结构体l枚举体
Ø 引用类型
会存在一个指向实际存储区的指针。比如通常一些引用类型会将数据存储在堆中,而栈中只存放指向堆中数据的地址(指针)。
引用类型有:
l普通引用类型l原生指针类型
2.2.1 基本数据类型
布尔类型
bool类型只有两个值:true和false。
基本数字类型
主要关注取值范围,具体的见《Rust编程之道》的第26页。
字符类型
用单引号来定义字符(char)类型。字符类型代表一个Unicode标量值,每个字节占4个字节。
数组类型
数组的类型签名为[T; N]。T是一个泛型标记,代表数组中元素的某个具体类型。N代表数组长度,在编译时必须确定其值。
数组特点:
- l 大小固定
- l 元素均为同类型
- l 默认不可变
切片类型
切片(Slice)类型是对一个数组的引用片段。在底层,切片代表一个指向数组起始位置的指针和数组长度。用[T]类型表示连续序列,那么切片类型就是&[T]和&mut[T]。
具体的见《Rust编程之道》的第30页。
str字符串类型
字符串类型str,通常是以不可变借用的形式存在,即&str(字符串切片)。
Rust将字符串分为两种:
1) &str :固定长度字符串
2) String :可以随意改变其长度。
&str字符串类型由两部分组成:
1) 指向字符串序列的指针;
2) 记录长度的值。
&str存储于栈上,str字符串序列存储于程序的静态只读数据段或者堆内存中。
&str是一种胖指针。
never类型
never类型,即!。该类型用于表示永远不可能有返回值的计算类型。
其他(此部分不属于基本数据类型)
此部分不属于基本数据类型,由于编排问题,暂时先放在此处。
胖指针
胖指针:包含了动态大小类型地址信息和携带了长度信息的指针。
具体的见《Rust编程之道》的第54页。
零大小类型
零大小类型(Zero sized Type,ZST)的特点是:它们的值就是其本身,运行时并不占用内存空间。
单元类型和单元结构体大小为零,由单元类型组成的数组大小也是零。
ZST类型代表的意义是“空”。
底类型
底类型其实是介绍过的never类型,用叹号(!)表示。它的特点是:
- l 没有值
- l 是其他任意类型的子类型
如果说ZST类型表示“空”的话,那么底类型就表示“无”。
底类型无值,而且它可以等价于任意类型。
具体的见《Rust编程之道》的第57页。
2.2.2 复合数据类型
元组
Rust提供了4中复合数据类型:
l元组(Tuple)l结构体(Struct)l枚举体(Enum)l联合体(Union)
先来介绍元组。元组是一种异构有限序列,形如(T,U,M,N)。所谓异构,就是指元组内的元素可以是不同类型。所谓有限,是指元组有固定的长度。
- l 空元组:
() - l 只有一个值时,需要加逗号:
(0,)
结构体
Rust提供了3中结构体:
l具名结构体l元组结构体l单元结构体
例如:
Ø 具名结构体:
struct People { name: &’static str, }
Ø 元组结构体:字段没有名称,只有类型:
struct Color(i32, i32, i32);
当一个元组结构体只有一个字段的时候,称为New Type模式。例如:
struct Integer(u32);
Ø 单元结构体:没有任何字段的结构体。单元结构体实例就是其本身。
struct Empty;
结构体更新语法
使用Struct更新语法(..)从其他实例创建新实例。当新实例使用旧实例的大部分值时,可以使用struct update语法。 例如:
#[derive(Debug,Copy,Clone)] struct Book<’a> { name: &’a str, isbn: i32, version: i32, } let book = Book { name: “Rust编程之道”, isbn: 20181212, version: 1 }; let book2 = Book {version: 2, ..book};
注:
- l 如果结构体使用了移动语义的成员字段,则不允许实现Copy。
- l Rust不允许包含了String类型字段的结构体实现Copy。
- l 更新语法会转移字段的所有权。
枚举体
该类型包含了全部可能的情况,可以有效的防止用户提供无效值。例如:
enum Number { Zero, One, }
Rust还支持携带类型参数的枚举体。这样的枚举值本质上属于函数类型,他可以通过显式的指定类型来转换为函数指针类型。例如:
enum IpAddr { V4(u8, u8, u8, u8), V6(String), }
枚举体在Rust中属于非常重要的类型之一。例如:Option枚举类型。
联合体
2.2.3 常用集合类型
线性序列:向量
在Rust标准库std::collections模块下有4中通用集合类型,分别如下:
- 线性序列:
向量(Vec)、双端队列(VecDeque)、链表(LinkedList) - Key-Value映射表:
无序哈希表(HashMap)、有序映射表(BTreeMap) - 集合类型:
无序集合(HashSet)、有序集合(BTreeSet) - 优先队列:
二叉堆(BinaryHeap)
具体的见《Rust编程之道》的第38页和271页。
向量也是一种数组,和基本数据类型中的数组的区别在于:向量可动态增长。
示例:
let mut v1 = vec![]; let mut v2 = vec![0; 10]; let mut v3 = Vec::new();
vec!是一个宏,用来创建向量字面量。
线性序列:双端队列
双端队列(Double-ended Queue,缩写Deque)是一种同时具有队列(先进先出)和栈(后进先出)性质的数据结构。
双端队列中的元素可以从两端弹出,插入和删除操作被限定在队列的两端进行。
示例:
use std::collections::VecDeque; let mut buf = VecDeque::new(); buf.push_front(1); buf.get(0); buf.push_back(2);
线性序列:链表
Rust提供的链表是双向链表,允许在任意一端插入或弹出元素。最好使用Vec或VecDeque类型,他们比链表更加快速,内存访问效率更高。
示例:
use std::collections::LinkedList; let mut list = LinkedList::new(); list.push_front(‘a’); list.append(&mut list2); list.push_back(‘b’);
Key-Value映射表:HashMap和BTreeMap
HashMap<K, V>=> 无序BTreeMap<K, V>=> 有序
其中HashMap要求key是必须可哈希的类型,BTreeMap的key必须是可排序的。
Value必须是在编译期已知大小的类型。
示例:
use std::collections::BTreeMap; use std::collections::HashMap; let mut hmap = HashMap::new(); let mut bmap = BTreeMap::new(); hmap.insert(1,”a”); bmap.insert(1,”a”);
集合:HashSet和BTreeSet
HashSet<K>和BTreeSet<K>其实就是HashMap<K, V>和BTreeMap<K, V>把Value设置为空元组的特定类型。
- l 集合中的元素应该是唯一的。
- l
HashSet中的元素都是可哈希的类型,BTreeSet中的元素必须是可排序的。 - l
HashSet应该是无序的,BTreeSet应该是有序的。
示例:
use std::collections::BTreeSet; use std::collections::HashSet; let mut hset = HashSet::new(); let mut bset = BTreeSet::new(); hset.insert(”This is a hset.”); bset.insert(”This is a bset”);
优先队列:BinaryHeap
Rust提供的优先队列是基于二叉最大堆(Binary Heap)实现的。
示例:
use std::collections::BinaryHeap; let mut heap = BinaryHeap::new(); heap.peek(); => peek是取出堆中最大的元素 heap.push(98);
容量(Capacity)和大小(Size/Len)
无论是Vec还是HashMap,使用这些集合容器类型,最重要的是理解容量(Capacity)和大小(Size/Len)。
容量是指为集合容器分配的内存容量。
大小是指集合中包含的元素数量。
2.2.4 Rust字符串
Rust字符串分为以下几种类型:
- l
str:表示固定长度的字符串 - l
String:表示可增长的字符串 - l
CStr:表示由C分配而被Rust借用的字符串。这是为了兼容windows系统。 - l
CString:表示由Rust分配且可以传递给C函数使用的C字符串,同样用于和C语言交互。 - l
OsStr:表示和操作系统相关的字符串。这是为了兼容windows系统。 - l
OsString:表示OsStr的可变版本。与Rust字符串可以相互交换。 - l
Path:表示路径,定义于std::path模块中。Path包装了OsStr。 - l
PathBuf:跟Path配对,是path的可变版本。PathBuf包装了OsString。
str属于动态大小类型(DST),在编译期并不能确定其大小。所以在程序中最常见的是str的切片(Slice)类型&str。
&str代表的是不可变的UTF-8字节序列,创建后无法再为其追加内容或更改其内容。&str类型的字符串可以存储在任意地方:
Ø 静态存储区
Ø 堆分配
Ø 栈分配
具体的见《Rust编程之道》的第249页。
String类型本质是一个成员变量为Vec<u8>类型的结构体,所以它是直接将字符内容存放于堆中的。
String类型由三部分组成:
Ø 执行堆中字节序列的指针(as_ptr方法)
Ø 记录堆中字节序列的字节长度(len方法)
Ø 堆分配的容量(capacity方法)
2.2.4.1 字符串处理方式
Rust中的字符串不能使用索引访问其中的字符,可以通过bytes和chars两个方法来分别返回按字节和按字符迭代的迭代器。
Rust提供了另外两种方法:get和get_mut来通过指定索引范围来获取字符串切片。
具体的见《Rust编程之道》的第251页。
2.2.4.2 字符串修改
Ø 追加字符串:push和push_str,以及extend迭代器
Ø 插入字符串:insert和insert_str
Ø 连接字符串:String实现了Add<&str>和AddAssign<&str>两个trait,所以可以使用“+”和“+=”来连接字符串
Ø 更新字符串:通过迭代器或者某些unsafe的方法
Ø 删除字符串:remove、pop、truncate、clear和drain
具体的见《Rust编程之道》的第255页。
2.2.4.3 字符串的查找
Rust总共提供了20个方法涵盖了以下几种字符串匹配操作:
Ø 存在性判断
Ø 位置匹配
Ø 分割字符串
Ø 捕获匹配
Ø 删除匹配
Ø 替代匹配
具体的见《Rust编程之道》的第256页。
2.2.4.4 类型转换
Ø parse:将字符串转换为指定的类型
Ø format!宏:将其他类型转成成字符串
2.2.5 格式化规则
- l 填充字符串宽度:
{:5},5是指宽度为5 l截取字符串:{:.5}l对齐字符串:{:>}、{:^}、{:<},分别表示左对齐、位于中间和右对齐l{:*^5}使用*替代默认空格来填充
- l 符号
+:表示强制输出整数的正负符号 - l 符号
#:用于显示进制的前缀。比如:十六进制0x - l 数字
0:用于把默认填充的空格替换成数字0 - l
{:x}:转换成16进制输出 - l
{:b}:转换成二进制输出 l{:.5}:指定小数点后有效位是5- l
{:e}:科学计数法表示
具体的见《Rust编程之道》的第265页。
2.2.6 原生字符串声明语法:r”…”
原生字符串声明语法(r”…”)可以保留原来字符串中的特殊符号。
具体的见《Rust编程之道》的第270页。
2.2.7 全局类型
Rust支持两种全局类型:
- l
普通常量(Constant) - l
静态变量(Static)
区别:
- l 都是在
编译期求值的,所以不能用于存储需要动态分配内存的类型 - l 普通常量
可以被内联的,它没有确定的内存地址,不可变 - l 静态变量
不能被内联,它有精确的内存地址,拥有静态生命周期 - l 静态变量可以通过内部包含UnsafeCell等容器
实现内部可变性 - l 静态变量还有其他限制,具体的见《Rust编程之道》的第326页
- l 普通常量也不能引用静态变量
在存储的数据比较大,需要引用地址或具有可变性的情况下使用静态变量。否则,应该优先使用普通常量。
但也有一些情况是这两种全局类型无法满足的,比如想要使用全局的HashMap,在这种情况下,推荐使用lazy_static包。利用lazy_static包可以把定义全局静态变量延迟到运行时,而非编译时。
2.3 trait
trait是对类型行为的抽象。trait是Rust实现零成本抽象的基石,它有如下机制:
- l trait是Rust唯一的接口抽象方式;
- l 可以静态分发,也可以动态分发;
- l 可以当做标记类型拥有某些特定行为的“标签”来使用。
示例:
struct Duck; struct Pig; trait Fly { fn fly(&self) -> bool; } impl Fly for Duck { fn fly(&self) -> bool { return true; } } impl Fly for Pig { fn fly(&self) -> bool { return false; } }
静态分发和动态分发的具体介绍可见《Rust编程之道》的第46页。
trait限定
以下这些需要继续深入理解第三章并总结。待后续继续补充。
trait对象
标签trait
Copy trait
Deref解引用
as操作符
From和Into
2.4 指针
2.3.1 引用Reference
用&和& mut操作符来创建。受Rust的安全检查规则的限制。
引用是Rust提供的一种指针语义。引用是基于指针的实现,他与指针的区别是:指针保存的是其指向内存的地址,而引用可以看做某块内存的别名(Alias)。
在所有权系统中,引用&x也可以称为x的借用(Borrowing)。通过&操作符来完成所有权租借。
2.3.2 原生指针(裸指针)
*const T和*mut T。可以在unsafe块下任意使用,不受Rust的安全检查规则的限制。
2.3.3 智能指针
实际上是一种结构体,只是行为类似指针。智能指针是对指针的一层封装,提供了一些额外的功能,比如自动释放堆内存。
智能指针区别于常规结构体的特性在于:它实现了Deref和Drop这两个trait。
Ø Deref:提供了解引用能力
Ø Drop:提供了自动析构的能力
2.3.3.1 智能指针有哪些
智能指针拥有资源的所有权,而普通引用只是对所有权的借用。
Rust中的值默认被分配到栈内存。可以通过Box<T>将值装箱(在堆内存中分配)。
Ø String
Ø Vec
String类型和Vec类型的值都是被分配到堆内存并返回指针的,通过将返回的指针封装来实现Deref和Drop。
Ø Box<T>
Box<T>是指向类型为T的堆内存分配值的智能指针。当Box<T>超出作用域范围时,将调用其析构函数,销毁内部对象,并自动释放堆中的内存。
Ø Arc<T>
Ø RC<T>
单线程引用计数指针,不是线程安全的类型。
可以将多个所有权共享给多个变量,每当共享一个所有权时,计数就会增加一次。具体的见《Rust编程之道》的第149页。
Ø Weak<T>
是RC<T>的另一个版本。
通过clone方法共享的引用所有权称为强引用,RC<T>是强引用。
Weak<T>共享的指针没有所有权,属于弱引用。具体的见《Rust编程之道》的第150页。
Ø Cell<T>
实现字段级内部可变的情况。
适合复制语义类型。
Ø RefCell<T>
适合移动语义类型。
Cell<T>和RefCell<T>本质上不属于智能指针,只是提供内不可变性的容器。
Cell<T>和RefCell<T>使用最多的场景就是配合只读引用来使用。
具体的见《Rust编程之道》的第151页。
Ø Cow<T>
Copy on write:一种枚举体的智能指针。Cow<T>表示的是所有权的“借用”和“拥有”。Cow<T>的功能是:以不可变的方式访问借用内容,以及在需要可变借用或所有权的时候再克隆一份数据。
Cow<T>旨在减少复制操作,提高性能,一般用于读多写少的场景。
Cow<T>的另一个用处是统一实现规范。
2.3.4 解引用deref
解引用会获得所有权。
解引用操作符: *
哪些实现了deref方法
Ø Box<T>:源码见《Rust编程之道》的第147页。
Ø Cow<T>:意味着可以直接调用其包含数据的不可变方法。具体的要点可见《Rust编程之道》的第155页。
Ø
Box<T >支持解引用移动, Rc<T>和Arc<T>智能指针不支持解引用移动。
2.4 所有权机制(ownership):
Rust中分配的每块内存都有其所有者,所有者负责该内存的释放和读写权限,并且每次每个值只能有唯一的所有者。
在进行赋值操作时,对于可以实现Copy的复制语义类型,所有权并未改变。对于复合类型来说,是复制还是移动,取决于其成员的类型。
例如:如果数组的元素都是基本的数字类型,则该数组是复制语义,则会按位复制。
2.4.1 词法作用域(生命周期)
match、for、loop、while、if let、while let、花括号、函数、闭包都会创建新的作用域,相应绑定的所有权会被转移,具体的可见《Rust编程之道》的第129页。
函数体本身是独立的词法作用域:
Ø 当复制语义类型作为函数参数时,会按位复制。
Ø 如果是移动语义作为函数参数,则会转移所有权。
2.4.2 非词法作用域声明周期
借用规则: 借用方的生命周期不能长于出借方的生命周期。用例见《Rust编程之道》的第157页。
因为以上的规则,经常导致实际开发不便,所以引入了非词法作用域生命周期(Non-Lexical Lifetime,NLL)来改善。
MIR是基于控制流图(Control Flow Graph,CFG)的抽象数据结构,它用有向图(DAG)形式包含了程序执行过程中所有可能的流程。所以将基于MIR的借用检查称为非词法作用域的生命周期。
2.4.2 所有权借用
使用可变借用的前提是:出借所有权的绑定变量必须是一个可变绑定。
在所有权系统中,引用&x也可以称为x的借用(Borrowing)。通过&操作符来完成所有权租借。所以引用并不会造成绑定变量所有权的转移。
引用在离开作用域之时,就是其归还所有权之时。
Ø 不可变借用(引用)不能再次出借为可变借用。
Ø 不可变借用可以被出借多次。
Ø 可变借用只能出借一次。
Ø 不可变借用和可变借用不能同时存在,针对同一个绑定而言。
Ø 借用的生命周期不能长于出借方的生命周期。具体的举例见《Rust编程之道》的第136页。
核心原则:共享不可变,可变不共享。
因为解引用操作会获得所有权,所以在需要对移动语义类型(如&String)进行解引用时需要特别注意。
2.4.3 生命周期参数
编译器的借用检查机制无法对跨函数的借用进行检查,因为当前借用的有效性依赖于词法作用域。所以,需要开发者显式的对借用的生命周期参数进行标注。
2.4.3.1 显式生命周期参数
Ø 生命周期参数必须是以单引号开头;
Ø 参数名通常都是小写字母,例如:'a;
Ø 生命周期参数位于引用符号&后面,并使用空格来分割生命周期参数和类型。
标注生命周期参数是由于borrowed pointers导致的。因为有borrowed pointers,当函数返回borrowed pointers时,为了保证内存安全,需要关注被借用的内存的生命周期(lifetime)。
标注生命周期参数并不能改变任何引用的生命周期长短,它只用于编译器的借用检查,来防止悬垂指针。即:生命周期参数的目的是帮助借用检查器验证合法的引用,消除悬垂指针。
例如:
&i32; ==> 引用 &'a i32; ==> 标注生命周期参数的引用 &'a mut i32; ==> 标注生命周期参数的可变引用 允许使用&'a str;的地方,使用&'static str;也是合法的。 对于'static:当borrowed pointers指向static对象时需要声明'static lifetime。 如: static STRING: &'static str = "bitstring";
2.4.3.2 函数签名中的生命周期参数
fn foo<'a>(s: &'a str, t: &'a str) -> &'a str;
函数名后的<'a>为生命周期参数的声明。函数或方法参数的生命周期叫做输入生命周期(input lifetime),而返回值的生命周期被称为输出生命周期(output lifetime)。
规则:
Ø 禁止在没有任何输入参数的情况下返回引用,因为会造成悬垂指针。
Ø 从函数中返回(输出)一个引用,其生命周期参数必须与函数的参数(输入)相匹配,否则,标注生命周期参数也毫无意义。
对于多个输入参数的情况,也可以标注不同的生命周期参数。具体的举例见《Rust编程之道》的第139页。
2.4.3.3 结构体定义中的生命周期参数
结构体在含有引用类型成员的时候也需要标注生命周期参数,否则编译失败。
例如:
struct Foo<'a> { part: &'a str, }
这里生命周期参数标记,实际上是和编译器约定了一个规则:
结构体实例的生命周期应短于或等于任意一个成员的生命周期。
2.4.3.4 方法定义中的生命周期参数
结构体中包含引用类型成员时,需要标注生命周期参数,则在impl关键字之后也需要声明生命周期参数,并在结构体名称之后使用。
例如:
impl<'a> Foo<'a> { fn split_first(s: &'a str) -> &'a str { … } }
在添加生命周期参数'a之后,结束了输入引用的生命周期长度要长于结构体Foo实例的生命周期长度。
注:枚举体和结构体对生命周期参数的处理方式是一样的。
2.4.3.5 静态生命周期参数
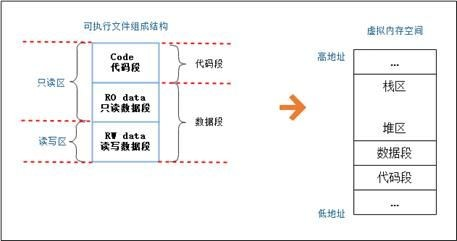
静态生命周期 'static:是Rust内置的一种特殊的生命周期。'static生命周期存活于整个程序运行期间。所有的字符串字面量都有生命周期,类型为& 'static str。
字符串字面量是全局静态类型,他的数据和程序代码一起存储在可执行文件的数据段中,其地址在编译期是已知的,并且是只读的,无法更改。
2.4.3.6 省略生命周期参数
满足以下三条规则时,可以省略生命周期参数。该场景下,是将其硬编码到Rust编译器重,以便编译期可以自动补齐函数签名中的生命周期参数。
生命周期省略规则:
- l 每一个在输入位置省略的生命周期都将成为一个不同的生命周期参数。即对应一个唯一的生命周期参数。
- l 如果只有一个输入的生命周期位置(无论省略还是没省略),则该生命周期都将分配给输出生命周期。
- l 如果有多个输入生命周期位置,而其中包含着 &self 或者 &mut self,那么 self 的生命周期都将分配给输出生命周期。
以上这部分规则还没理解透彻,需要继续熟读《Rust编程之道》的第143页。
2.4.3.7 生命周期限定
生命周期参数可以向trait那样作为泛型的限定,有以下两种形式:
- l
T: 'a,表示T类型中的任何引用都要“获得”和'a一样长。 - l
T: Trait + 'a,表示T类型必须实现Trait这个trait,并且T类型中任何引用都要“活的”和'a一样长。
具体的举例见《Rust编程之道》的第145页。
2.4.3.8 trait对象的生命周期
具体的举例见《Rust编程之道》的第146页。
2.4.3.9 高阶生命周期
Rust还提供了高阶生命周期(Higher-Ranked Lifetime)方案,该方案也叫高阶trait限定(Higher-Ranked Trait Bound,HRTB)。该方案提供了for<>语法。
for<>语法整体表示此生命周期参数只针对其后面所跟着的“对象”。
具体的可见《Rust编程之道》的第192页。
2.5 并发安全与所有权
2.5.1 标签trait:Send和Sync
Ø 如果类型T实现了Send: 就是告诉编译器该类型的实例可以在线程间安全传递所有权。
Ø 如果类型T实现了Sync:就是向编译器表明该类型的实例在多线程并发中不可能导致内存不安全,所以可以安全的跨线程共享。
2.5.2 哪些类型实现了Send
2.5.3 哪些类型实现了Sync
2.6 原生类型
Rust内置的原生类型 (primitive types) 有以下几类:
- l
布尔类型:有两个值true和false。 - l
字符类型:表示单个Unicode字符,存储为4个字节。 - l
数值类型:分为有符号整数 (i8, i16, i32, i64, isize)、 无符号整数 (u8, u16, u32, u64, usize) 以及浮点数 (f32, f64)。 - l
字符串类型:最底层的是不定长类型str,更常用的是字符串切片&str和堆分配字符串String, 其中字符串切片是静态分配的,有固定的大小,并且不可变,而堆分配字符串是可变的。 - l
数组:具有固定大小,并且元素都是同种类型,可表示为[T; N]。 - l
切片:引用一个数组的部分数据并且不需要拷贝,可表示为&[T]。 - l
元组:具有固定大小的有序列表,每个元素都有自己的类型,通过解构或者索引来获得每个元素的值。 - l
指针:最底层的是裸指针const T和mut T,但解引用它们是不安全的,必须放到unsafe块里。 - l
函数:具有函数类型的变量实质上是一个函数指针。 - l
元类型:即(),其唯一的值也是()。
2.7 函数
2.7.1 函数参数
- l 当函数参数按值传递时,会转移所有权或者执行复制(Copy)语义。
- l 当函数参数按引用传递时,所有权不会发生变化,但是需要有生命周期参数(符合规则时不需要显示的标明)。
2.7.2 函数参数模式匹配
- l
ref:使用模式匹配来获取参数的不可变引用。 - l
ref mut:使用模式匹配来获取参数的可变引用。 - l 除了ref和ref mut,函数参数也可以使用通配符来忽略参数。
具体可见《Rust编程之道》的第165页。
2.7.3 泛型函数
函数参数并未指定具体的类型,而是用了泛型T,对T只有一个Mult trait限定,即只有实现了Mul的类型才可以作为参数,从而保证了类型安全。
泛型函数并未指定具体类型,而是靠编译器来进行自动推断的。如果使用的都是基本原生类型,编译器推断起来比较简单。如果编译器无法自动推断,就需要显式的指定函数调用的类型。
2.7.4 方法和函数
方法代表某个实例对象的行为,函数只是一段简单的代码,它可以通过名字来进行调用。方法也是通过名字来进行调用,但它必须关联一个方法接受者。
2.7.5 高阶函数
高阶函数是指以函数作为参数或返回值的函数,它是函数式编程语言最基础的特性。
具体可见《Rust编程之道》的第168页。
2.8 闭包Closure
闭包通常是指词法闭包,是一个持有外部环境变量的函数。
外部环境是指闭包定义时所在的词法作用域。
外部环境变量,在函数式编程范式中也被称为自由变量,是指并不是在闭包内定义的变量。
将自由变量和自身绑定的函数就是闭包。
闭包的大小在编译期是未知的。
2.8.1 闭包的基本语法
闭包由管道符(两个对称的竖线)和花括号(或圆括号)组成。
Ø 管道符里是闭包函数的参数,可以向普通函数参数那样在冒号后添加类型标注,也可以省略。例如:let add = |a, b| -> i32 { a + b };
Ø 花括号里包含的是闭包函数执行体,花括号和返回值也可以省略。
例如:let add = |a, b| a + b;
Ø 当闭包函数没有参数只有捕获的自由变量时,管道符里的参数也可以省略。
例如: let add = || a + b;
2.8.2 闭包的实现
闭包是一种语法糖。闭包不属于Rust语言提供的基本语法要素,而是在基本语法功能之上又提供的一层方便开发者编程的语法。
闭包和普通函数的差别就是闭包可以捕获环境中的自由变量。
闭包可以作为函数参数,这一点直接提升了Rust语言的抽象表达能力。当它作为函数参数传递时,可以被用作泛型的trait限定,也可以直接作为trait对象来使用。
闭包无法直接作为函数的返回值,如果要把闭包作为返回值,必须使用trait对象。
2.8.3 闭包与所有权
闭包表达式会由编译器自动翻译为结构体实例,并为其实现Fn、FnMut、FnOnce三个trait中的一个。
lFnOnce:会转移方法接收者的所有权。没有改变环境的能力,只能调用一次。- l
FnMut:会对方法接收者进行可变借用。有改变环境的能力,可以多次调用。 - l
Fn:会对方法接收者进行不可变借用。没有改变环境的能力,可以多次调用。
Ø 如果要实现Fn,就必须实现FnMut和FnOnce;
Ø 如果要实现FnMut,就必须实现FnOnce;
Ø 如果要实现FnOnce,就不需要实现FnMut和Fn。
2.8.3.1 捕获环境变量的方式
- l 对于
复制语义类型,以不可变引用(&T)来进行捕获。 - l 对于
移动语义类型,执行移动语义,转移所有权来进行捕获。 - l 对于
可变绑定,并且在闭包中包含对其进行修改的操作,则以可变引用(&mut T)来进行捕获。
具体可见《Rust编程之道》的第178页。
Rust使用move关键字来强制让闭包所定义环境中的自由变量转移到闭包中。
2.8.3.2 规则总结
- l 如果闭包中没有捕获任何环境变量,则默认自动实现
Fn。 - l 如果闭包中捕获了复制语义类型的环境变量,则:
Ø 如果不需要修改环境变量,无论是否使用move关键字,均会自动实现Fn。
Ø 如果需要修改环境变量,则自动实现FnMut。
- l 如果闭包中捕获了移动语义类型的环境变量,则:
Ø 如果不需要修改环境变量,而且没有使用move关键字,则会自动实现FnOnce。
Ø 如果不需要修改环境变量,而且使用move关键字,则会自动实现Fn。
Ø 如果需要修改环境变量,则自动实现FnMut。
- l
FnMut的闭包在使用move关键字时,如果捕获变量是复制语义类型的,则闭包会自动实现Copy/Clone。如果捕获变量是移动语义类型的,则闭包不会自动实现Copy/Clone。
2.9 迭代器
Rust使用的是外部迭代器,也就是for循环。外部迭代器:外部可以控制整个遍历进程。
Rust中使用了trait来抽象迭代器模式。Iterator trait是Rust中对迭代器模式的抽象接口。
迭代器主要包含:
- l
next方法:迭代其内部元素 - l
关联类型Item - l
size_hint方法:返回类型是一个元组,该元组表示迭代器剩余长度的边界信息。
示例:
let iterator = iter.into_iter(); let size_lin = iterator.size_hint(); let mut counter = Counter { count: 0}; counter.next();
Iter类型迭代器,next方法返回的是Option<&[T]>或Option<&mut [T]>类型的值。for循环会自动调用迭代器的next方法。for循环中的循环变量则是通过模式匹配,从next返回的Option<&[T]>或Option<&mut [T]>类型中获取&[T]或&mut [T]类型的值。
Iter类型迭代器在for循环中产生的循环变量为引用。
IntoIter类型的迭代器的next方法返回的是Option<T>类型,在for循环中产生的循环变量是值,而不是引用。
示例:
let v = vec![1, 2, 3];for i in v { …} let v = vec![1, 2, 3];for i in v { …} let v = vec![1, 2, 3];for i in v { …} let v = vec![1, 2, 3];for i in v { …}
l Intoiter :转移所有权,对应self为了确保size_hint方法可以获得迭代器长度的准确信息,Rust引入了两个trait,他们是Iterator的子trait,均被定义在std::iter模块中。
- l
ExactSizeIterator:提供了两个额外的方法len和is_empty。 - l
TrustedLen:像一个标签trait,只要实现了TrustLen的迭代器,其size_hint获取的长度信息均是可信的。完全避免了容器的容量检查,提升了性能。
2.9.1 IntoIterator trait
如果想要迭代某个集合容器中的元素,必须将其转换为迭代器才可以使用。
Rust提供了FromIterator和IntoIterator两个trait,他们互为反操作。
- l
FromIterator:可以从迭代器转换为指定类型。 - l
IntoIterator:可以从指定类型转换为迭代器。
Intoiter可以使用into_iter之类的方法来获取一个迭代器。into_iter的参数时self,代表该方法会转移方法接收者的所有权。而还有其他两个迭代器不用转移所有权。具体的如下所示:
- l
Iter:获取不可变借用,对应&self - l
IterMut:获得可变借用,对应&mut slef
2.9.2 哪些实现了Iterator的类型?
只有实现了Iterator的类型才能作为迭代器。
实现了IntoIterator的集合容器可以通过into_iter方法来转换为迭代器。
实现了IntoIterator的集合容器有:
lVec<T>l&’a [T]l&’a mut [T]=> 没有为[T]类型实现IntoIterator- l
2.9.3 迭代器适配器
通过适配器模式可以将一个接口转换成所需要的另一个接口。适配器模式能够使得接口不兼容的类型在一起工作。
适配器也叫包装器(Wrapper)。
迭代器适配器,都定义在std::iter模块中:
- l
Map:通过对原始迭代器中的每个元素调用指定闭包来产生一个新的迭代器。 - l
Chain:通过连接两个迭代器来创建一个新的迭代器。 - l
Cloned:通过拷贝原始迭代器中全部元素来创建新的迭代器。 - l
Cycle:创建一个永远循环迭代的迭代器,当迭代完毕后,再返回第一个元素开始迭代。 - l
Enumerate:创建一个包含计数的迭代器,它返回一个元组(i,val),其中i是usize类型,为迭代的当前索引,val是迭代器返回的值。 - l
Filter:创建一个机遇谓词判断式过滤元素的迭代器。 - l
FlatMap:创建一个类似Map的结构的迭代器,但是其中不会包含任何嵌套。 - l
FilterMap:相当于Filter和Map两个迭代器一次使用后的效果。 - l
Fuse:创建一个可以快速遍历的迭代器。在遍历迭代器时,只要返回过一次None,那么之后所有的遍历结果都为None。该迭代器适配器可以用于优化。 - l
Rev:创建一个可以反向遍历的迭代器。
具体可见《Rust编程之道》的第202页。
Rust可以自定义迭代器适配器,具体的见《Rust编程之道》的第211页。
2.10 消费器
迭代器不会自动发生遍历行为,需要调用next方法去消费其中的数据。最直接消费迭代器数据的方法就是使用for循环。
Rust提供了for循环之外的用于消费迭代器内数据的方法,叫做消费器(Consumer)。
Rust标准库std::iter::Iterator中常用的消费器:
- l
any:可以查找容器中是否存在满足条件的元素。 - l
fold:该方法接收两个参数,第一个为初始值,第二个为带有两个参数的闭包。其中闭包的第一个参数被称为累加器,它会将闭包每次迭代执行的结果进行累计,并最终作为fold方法的返回值。 - l
collect:专门用来将迭代器转换为指定的集合类型。 lalllfor_eachlposition
2.11 锁
- l
RwLock读写锁:是多读单写锁,也叫共享独占锁。它允许多个线程读,单个线程写。但是在写的时候,只能有一个线程占有写锁;而在读的时候,允许任意线程获取读锁。读锁和写锁不能被同时获取。 - l
Mutex互斥锁:只允许单个线程读和写。
三、 Rust属性
Ø #[lang = “drop”] : 将drop标记为语言项
Ø #[derive(Debug)] :
Ø #[derive(Copy, Clone)] :
Ø #[derive(Debug,Copy,Clone)] :
Ø #[lang = “owned_box”] : Box<T>与原生类型不同,并不具备类型名称,它代表所有权唯一的智能指针的特殊性,需要使用lang item来专门识别。
Ø #[lang = “fn/fn_mut/fn_once”] :表示其属于语言项,分别以fn、fn_mut、fn_once名称来查找这三个trait。
l fn_once:会转移方法接收者的所有权
l fn_mut:会对方法接收者进行可变借用
l fn:会对方法接收者进行不可变借用
Ø #[lang = “rust_pareen_sugar”] :表示对括号调用语法的特殊处理。
Ø #[must_use=”iterator adaptors are lazy ……”] :用来发出警告,提示开发者迭代器适配器是惰性的。
四、内存管理
4.1 内存回收
drop-flag:在函数调用栈中为离开作用域的变量自动插入布尔标记,标注是否调用析构函数,这样,在运行时就可以根据编译期做的标记来调用析构函数。
实现了Copy的类型,是没有析构函数的。因为实现了Copy的类型会复制,其生命周期不受析构函数的影响。
需要继续深入理解第4章并总结,待后续补充。
五、unicode
Unicode字符集相当于一张表,每个字符对应一个非负整数,该数字称为码点(Code Point)。
这些码点也分为不同的类型:
- l 标量值
- l 代理对码点
- l 非字符码点
- l 保留码点
- l 私有码点
标量值是指实际存在对应字符的码位,其范围是0x0000~0xD7FF和0xE000~0x10FFFF两段。
Unicode字符集的每个字符占4个字节,使用的存储方式是:码元(Code Unit)组成的序列。
码元是指用于处理和交换编码文本的最小比特组合。
Unicode字符编码表:
- l
UTF-8=>1字节码元 - l
UTF-16=>2字节码元 - l
UTF-32=>4字节码元
Rust的源码文件.rs的默认文本编码格式是UTF-8。
六、Rust附录
字符串对象常用的方法