

自定义TBE算子入门,不妨从单算子开发开始
摘要:以单算子开发为例,带你了解算子开发及测试全流程。
为什么要自定义算子
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称Op)。算子是一个函数空间到函数空间上的映射O:X→X;从广义上讲,对任何函数进行某一项操作都可以认为是一个算子。于我们而言,我们所开发的算子是网络模型中涉及到的计算函数。在Caffe中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)中的卷积算法,是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,也是一个算子。

Ascend 模型转换导航
绝大多数情况下,由于昇腾AI软件栈支持绝大多数算子,开发者不需要进行自定义算子的开发,只需提供深度学习模型文件,通过离线模型生成器(OMG)转换就能够得到离线模型文件,从而进一步利用流程编排器(Matrix)生成具体的应用程序。既然如此,为什么还需要自定义算子呢?这是因为在模型转换过程中出现了算子不支持的情况,例如昇腾AI软件栈不支持模型中的算子、开发者想修改现有算子中的计算逻辑、或者开发者想自己开发算子来提高计算性能,这时就需要进行自定义算子的开发了。
TBE算子开发流程
昇腾AI软件栈提供了TBE算子开发框架,开发者可以基于此框架使用Python语言开发自定义算子。首先,我们来了解一下什么是TBE。TBE的全称为Tensor Boost Engine,即张量加速引擎,是一款华为自研的算子开发工具,用于开发能够运行在NPU(Neural-network Processing Unit:神经网络处理器)上的TBE算子,该工具是在业界著名的开源项目TVM(Tensor Virtual Machine)基础上扩展的,提供了一套Python API来实施开发活动。在本次开发实践中,NPU特指昇腾AI处理器。
通过TBE进行算子开发的方式有两种:特定域语言开发(DSL开发)和TVM原语开发(TIK开发)。DSL开发相对简单,适用于入门级的开发者。其特点是TBE工具提供自动优化机制,给出较优的调度流程,开发者仅需要了解神经网络和TBE DSL相关知识,便可指定目标生成代码,进一步被编译成专用内核。TIK开发难度较高,适用于对于TVM编程及达芬奇结构都非常了解的开发者使用。这种方式的接口偏底层,需开发者自己控制数据流及算子的硬件调度。作为入门课程,我们这次使用的DSL开发方式。
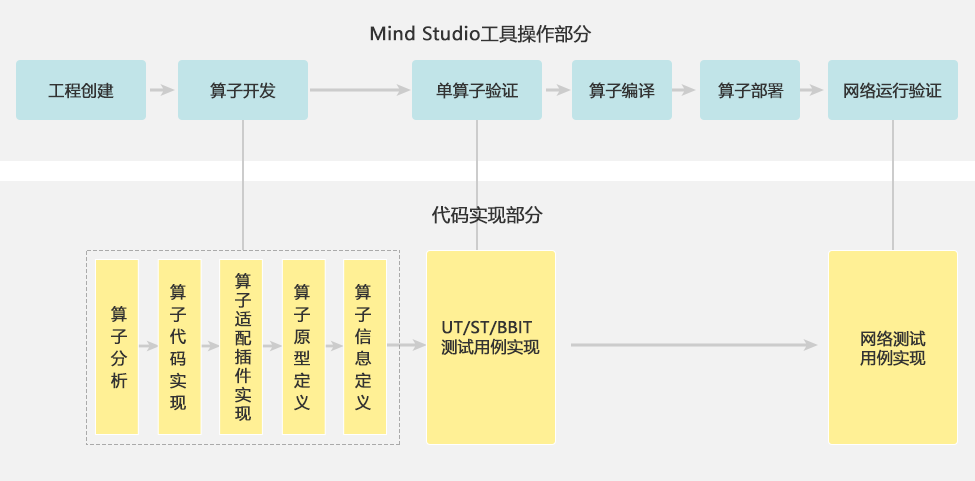
TBE算子开发流程
接下来,我们就以一个简单的单算子开发为例,了解一下开发过程。
- 目标:
用TBE-DSL方式开发一个Sqrt算子
- 确定算子功能:
Sqrt算子功能是对Tensor中每个原子值求开方,数学表达式为y=
- 确定使用的计算接口:
根据当前TBE框架可支持的计算描述API,可采用如下公式来表达Sqrt算子的计算过程

算子代码的实现可分为以下步骤:

1)算子入参

shape:Tensor的属性,表示Tensor的形状,用list或tuple类型表示,例如(3, 2, 3)、(4, 10);
dtype:Tensor的数据类型,用字符串类型表示,例如“float32”、“float16”、“int8”等。
2)输入Tensor占位符
data = tvm.placeholder(shape, name="data", dtype=input_dtype)
tvm.placeholder()是TVM框架的API,用来为算子执行时接收的数据占位,通俗理解与C语言中%d、%s一样,返回的是一个Tensor对象,上例中使用data表示;入参为shape,name,dtype,是为Tensor对象的属性。
3)定义计算过程

4)定义调度过程
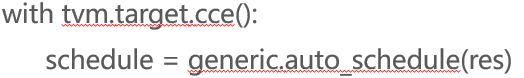
5)算子构建

6)测试验证
诶等一等,还没结束呢。只有在仿真环境中验证了算子功能的正确性,自定义算子的开发才算完成。
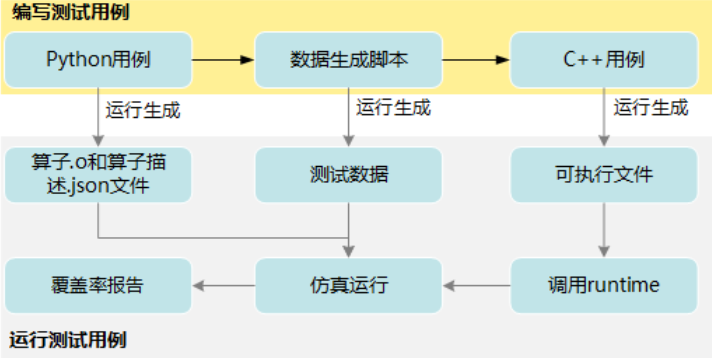
ST测试流程
我们需要用ST测试(即System Test系统测试)在仿真环境中测试算子逻辑的正确性以及能否正确地生成.o和.json文件。想知道具体是怎么测试的吗?与其看一大段枯燥的文字描述,不如来沙箱实验室亲自体验一番,一定更加直观。
读到这里,你是不是对自己的自定义算子开发能力更加有信心了?何不来华为云学院学课程、做实验、考证书来验证一下呢?喏,就是这门微认证啦:基于昇腾AI处理器的算子开发

