让你的产品更懂世界:如何提升场景文本识别中的语言模型
摘要:语言模型即根据当前语境的上下文推断当前句子的意思。
目录:
- 语言模型定义
- 基于深度学习的解决思路
- 语言模型的问题
- 未来展望
一、语言模型定义
1. 什么是语言模型?
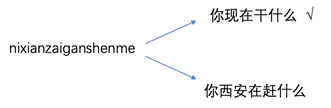
图1
如图1所示,顾名思义,语言模型即根据当前语境的上下文推断当前句子的意思。具体的标准定义为:对于语言序列w1, w2, …wn,语言模型就是计算该序列的概率即P(w1, w2, …wn)。
2. 为什么需要语言模型?
文本图像中包含两层信息:视觉纹理信息和语言信息。由于单纯根据视觉纹理信息进行文字识别缺少了对上下文的字符语义信息的挖掘,时常会导致错误的文本识别结果(之后会详细说明)。因此如何获得鲁棒的语言信息来提升识别性能成为了最近场景文本识别任务中比较受欢迎的思路。
3. 统计语言模型(n-gram)
由链式法则可以得到:
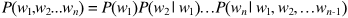
可以通过采用极大似然估计来计算每个词出现的条件概率,但是对于任意长的自然语言语句,根据极大似然估计直接计算P(wn |w1, w2, …wn-1)显然不现实(计算量太大)。因此为了解决这个问题,n-gram语言模型引入马尔可夫假设(Markov assumption),即假设当前词出现的概率只依赖于前 n-1 个词,可以得到:
n=1 unigram:
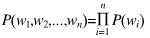
n=2 bigram:
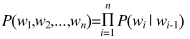
…
因此,综上可以看出,基于n-gram的语言模型有如下优点:1)完全包含了前n-1个词的全部信息。2)可解释性强。对应也有缺点:1)缺乏长期依赖关系。2)参数空间随着n增大指数型增长。3)单纯的基于统计频次,泛化能力差。
二、基于深度学习的解决思路
在目前基于深度学习的语言模型结构主要包括三个类别:基于RNN的语言模型,基于CNN的语言模型和基于Transformer的语言模型。接下来我会对它们进行依次介绍,并且逐一分析他们的优缺点。
1.通过RNN的语言模型结构
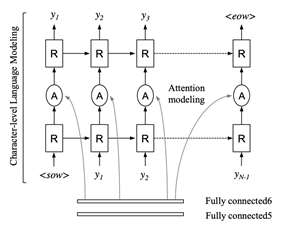
图2 基于RNN的语言模型结构
随着深度学习的发展,在受到NLP(Natural Language Processing)等任务的启发,Lee等人[1]在视觉特征建模之后,通过引入RNN(Recurrent Neural Networks)代替传统的n-gram进行语言模型建模(图2所示)。RNN通过自回归的方式(Auto Regression),在t时间步读取的是t-1步的状态,即预测当前时间步时会考虑上一时间步的信息,同时通过注意力的方式在glimpse向量中关注对应位置字符的视觉信息。该方法省去了繁琐的n-gram计算过程,在目前的场景文本识别框架中占据了主导的地位。
但是基于RNN的语言模型结构存在2个问题:1)梯度消失/爆炸的问题。2)串行计算效率慢。因此,最近的方法对RNN的语言建模方式进行了改进(上下文记忆力差的问题,因为在部分最近的工作中证明对中/短文本影响不大,所以在这里没有考虑)。
2. 通过CNN的语言模型结构
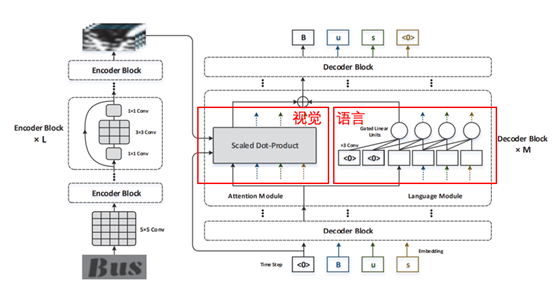
图3 视觉和语言模型集成的网路框架
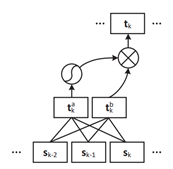
图4 基于CNN的语言模型结构
为了避免了由RNN造成的梯度消失/爆炸的问题,Fang等人[2]采用了全卷积神经网络的结构,并通过一个并行的分支单独学习语言信息(图3),通过将视觉和语言信息集成的方法提升了识别结果。
基于CNN的语言模型如图4所示,给定 ,输出向量 由下式获得:

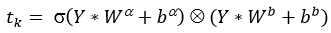
sk-2 和 sk-1 是之前时间步对应的向量,因此,该结构可以看成一个近似的bigram语言模型。但是由于该语言模型也是串行的操作过程,导致其计算效率也较慢。
3. 通过Transformer的语言模型结构
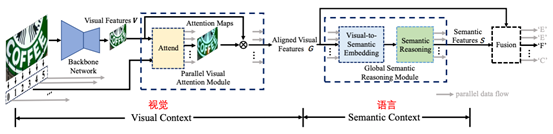
图5 视觉语言模型解耦的网络结构
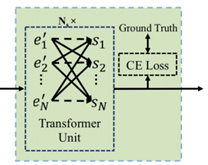
图6 基于transformer的语言模型结构
Yu等人[3]将语言模型从视觉部分解耦,然后在两个独立的结构中分别进行进行视觉和语言模型的建模,最后通过融合视觉和语言信息进行文本预测(图5所示)。在语言模型部分,该方法采用了Transformer的结构(图6所示),通过Transformer中的mask来模拟语言结构中的顺序和逆序的建模过程,最终自适应地融合视觉和语言信息进行识别。由于Transformer的结构特点,识别过程不同的时间步并行操作,提升了识别效率。
三、语言模型的问题

图7 语言信息帮助提升识别结果的效果图(上:没有语言模型。下:加入语言模型。)
语言模型能够帮助在视觉信息不充足的情况下,提升识别的结果。如图7所示,语言模型提取的语言信息能够有效地帮助在视觉缺失,模糊,噪声的情况下实现准确的识别结果。虽然语言模型提升效果显著,但是也存在着以下几个问题:1)OC(outside vocabulary)问题。2)计算复杂度高。
针对OC问题,Wan等人[4]指出了目前基于注意力的方法容易在训练集中没有出现过的词汇中识别错误,且精度和在测试过程中使用训练集中出现过的词汇的效果之间gap远大于基于分割的识别方法,因此如何获得一个鲁棒的语言模型是一种挑战。对于计算量问题,虽然目前Transformer应用于识别是一种趋势,且能够通过并行计算提升识别效率,但是对于长文本的识别,其计算量增加明显(RNN为线性增长,Transformer为平方增长)。
四、未来展望
语言模型最近是场景文本识别领域比较热门的研究方向,在我看来语言模型部分以后的研究大致会分为两个方向:1)结构。即如何通过搭建更强壮的语言模型捕捉更鲁邦的语言信息。2)能力。如何降低OC问题的影响。3)计算量。如何在低计算量的前提下提取有效的语言信息。
最近的方法中,仅通过捕捉视觉特征也能取得不错的效果(基于视觉特征匹配[5])。对于无序的识别(车牌识别),Yue等人[6]引入了位置信息增强视觉特征进行识别。因此,在作者看来,未来的文本识别发展一定是多元化的,即视觉和语言模型并行发展,针对不同的具体任务会有不同的改进。
参考文献
[1] Chen-Yu Lee and Simon Osindero. Recursive recurrent nets with attention modeling for ocr in the wild. CVPR, 2016.
[2] Fang S, Xie H, Zha Z J, et al. Attention and language ensemble for scene text recognition with convolutional sequence modeling. MM, 2018.
[3] Yu D, Li X, Zhang C, et al. Towards accurate scene text recognition with semantic reasoning networks. CVPR. 2020.
[4] Wan Z, Zhang J, Zhang L, et al. On Vocabulary Reliance in Scene Text Recognition. CVPR, 2020.
[5] Zhang C, Gupta A, Zisserman A. Adaptive Text Recognition through Visual Matching. ECCV, 2020.
[6] Yue X, Kuang Z, Lin C, et al. RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition. ECCV, 2020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号