GaussDB(DWS)应用实践丨负载管理与作业排队处理方法
摘要:本文用来总结一些GaussDB(DWS)在实际应用过程中,可能出现的各种作业排队的情况,以及出现排队时,我们应该怎么去判断是否正常,调整一些参数,让资源分配与负载管理更符合当前的业务;或者在作业阻塞的时候,怎么去处理这些情况,让业务立刻恢复正常。
概述
数据库系统的负载管理和资源管理,在整个系统中起着很重要的作用,比如很多用户的业务压力过大时,有时会导致连接数量被占满,有时会导致某种计算资源被占满,有时会导致存储空间被占满,这些情况都会导致整个集群进入异常甚至不可用的状态:正在执行的作业互相争抢CPU,会导致大家都不能好好执行;大量作业执行时,占用大量内存,很容易触发到内存瓶颈,造成作业内存不可用问题,导致业务报错等等。在不进行并发控制的情况下,这些情况都很可能会出现,影响到正常业务。
本文用来总结一些GaussDB(DWS)在实际应用过程中,可能出现的各种作业排队的情况,以及出现排队时,我们应该怎么去判断是否正常,调整一些参数,让资源分配与负载管理更符合当前的业务;或者在作业阻塞的时候,怎么去处理这些情况,让业务立刻恢复正常。
本文分为以下几个小节去介绍并解答以上问题:
- 一、负载管理简介:双层排队简述
- 二、常用视图以及使用方法介绍
- 三、负载管理常见问题以及处理
- 四、部分负载管理配置方案介绍
- 五、小结
一、负载管理简介:双层并发控制简述
DWS的负载管理分为两层,第一层为cn的全局并发控制,第二层为资源池级别的并发控制。在通过第一层控制的时候,会继续向前走到第二层资源池控制,根据资源池当前的负载资源情况决定作业继续执行或者排队。
DWS并发控制逻辑示意图如下:
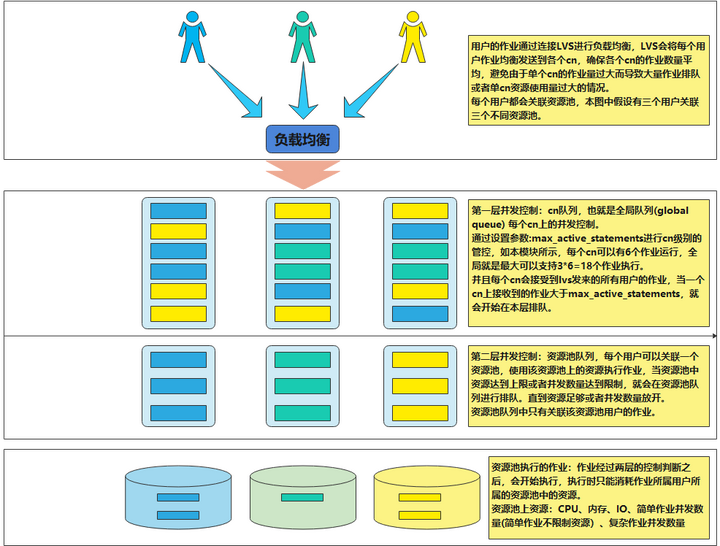
从本图的逻辑我们可以看到,实际作业执行中,可能会在两种队列中排队:
一种是全局队列(global queue),这种队列不区分简单和复杂作业,也不区分是DDL或者是普通语句,
一种是资源池队列(resource pool queue),用户下发的一般语句会根据资源消耗估算以及复杂程度在这里进行判断是否排队。
在两层队列的过滤下,DWS会筛选出当前能执行的语句,使其正常运行,运行时也会受到其所属资源池资源的限制(只能使用资源池配置的CPU、内存、IO配额)。
二、常用视图以及使用方法介绍
这里介绍几个常用视图以及SQL语句,可以迅速判断目前的业务出现问题的原因,受限根据以下视图可以看到目前的作业是不是在排队,之后要迅速分析为什么在排队,是因为负载管理各个参数配置问题,还是因为正在执行的语句占据了过多的资源导致的排队。
- pgxc_stat_activity(pg_stat_activity)
常用语句:
#查询当前执行时间最长的语句的排队状态,query_id(数据库中作业的唯一标识),以及详细的语句信息。 select coorname,usename, current_timestamp-query_start as duration, enqueue,query_id,query from pgxc_stat_activity where state='active' and usename <> 'Ruby' order by duration desc;
根据该语句可以迅速判断出哪些语句执行时间很长,是什么样的语句执行很慢以及该语句的query_id,便于迅速进入下一步排查。
执行结果如下:
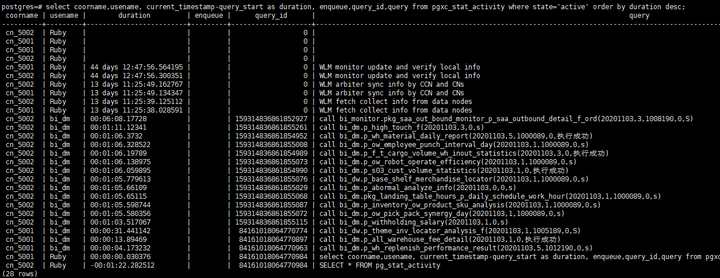
上图解说:图中为在没有作业的情况下查询,可以看到有几个WLM的语句已经执行了很多,不过这两个是内部常驻线程,所以不影响业务,也不会占用连接数等数据库资源。
其余的行可以看到有bi用户,在执行一些作业,时间大概1-6分钟左右。
- pg_session_wlmstat (记录每个cn的语句执行情况,资源使用情况,排队情况等信息)
常用语句:
#查询每个用户下的作业执行情况,排队情况以及作业的复杂情况和内存消耗情况。 select usename,enqueue,datname,status,attribute,count(*),sum(statement_mem) from pg_session_wlmstat group by 3,1,2,4,5 order by 1,3,4,5 ;
执行结果如下:

上图解说:
上图中说明当前连接的cn中有用户名为usr1的用户执行作业,并且在资源池上排队(第一节介绍的resourcepool队列),数据库为postgres,作业在排队所以当前status为pending状态。
其他字段包括作业的属性和当前使用内存资源的总和情况(根据该数值可以看出是否因为内存资源不足而进入排队状态)。作业在排队时候不涉及到资源消耗,因此可能没有具体数值。
- pgxc_thread_wait_status(查看数据库中各个线程的执行情况,当前在等待哪一步骤执行完成,在哪个实例等待,都可以通过该视图查询);
常用语句:
#在根据pgxc_stat_activity查询到具体执行时间长的语句之后,可以根据本视图查询: select * from pgxc_thread_wait_status where query_id = xxxxxxxx;
该语句可以查看执行慢语句的阻塞点,语句卡住时,可以通过该语句查看语句卡在了哪个步骤。
举例如下:

上图可以看到作业在wait io,此时可以检查下磁盘的读写速度是否,raid卡读写策略是否正常等等。
当出现排队的时候,wait_status一般的状态是waiting in ccn queue/waiting resourcepool queue等状态。
- 查询并发数量的方法,就是查看pgxc_stat_activity中,状态(state字段)是active的语句,enqueue字段为null的语句,除此之外,idle in transaction之类状态的语句,也会占用一个并发数量,因为一个事务块的业务还未提交,自然也算是正在执行的业务,对于这种情况,后续可以考虑进行一个处于此类状态的超时时间的控制。
三、负载管理常见问题
一般当业务上发现任务阻塞时,可以从后台查询部分语句排查目前的情况,此时要先看下现象上是什么情况,一般并发控制有以下几种现象,暂时先列出这么多,后续继续补充:
1. 业务反馈无法连接到数据库,比如DS连接一直转圈,过一段时间之后会超时报错。
- 此时可以开始排查当前的配置情况,一般连接不到数据库,其实是一种表象,主要是因为作业已经进入了排队的状态,语句本身就有很多在排队,无法执行,此时用ds连接之后,ds本身就会下发语句查询一些系统表之类的信息,所以也会进入排队的状态,在客户层面的影响就是ds一直处于一个连接中的状态,实际上是ds的连接在数据库中。
- 查询参数配置,看当前每个cn可以接受的最大并发数量是多少:
- show max_active_statements;
如果当前cn的活跃作业超过这个参数,会出现语句排队的情况,主要排队情况为waiting in global queue,如下图所示,下图情况中,max_active_statements=6。

- 查看业务连接是否主要只连接一个cn,可以同样通过查询pgxc_stat_activity判断coorname,查看是否大量的语句都是集中在某一个cn上执行,当语句下发集中在某个cn上时,这个cn的并发数量也只是max_active_statements设置的大小,举个例子:如果业务连接3个cn,每个cn的max_active_statements设置都是10,那么最大可以同时运行30个作业;如果这30个作业都下发到一个cn上,那么就有20个排队,同时只能执行10个,会大大影响执行效率,同时也会造成这种看似无法连接到该cn的现象。
- 解决方法:
- 业务负载不均:配置LVS,均衡业务,避免负载不均导致的排队。
- max_active_statements参数设置过小:在资源负载允许的情况下继续调大,如果资源达到瓶颈,继续放大可能会导致资源争抢,效果不大。
- 连接被空闲事务占用:如上图中情况,可以看到有很多连接的状态都是idle in transaction,这种状态处于事务块完成但是没有提交,也会占用一个并发,导致其余作业并发量减小,导致排队。此类情况需要排查业务应用的执行情况,整改业务,避免处于这种空闲还占用并发的情况。严重阻塞业务的情况,紧急处理可以将该类语句直接terminate掉。
- 确实已经有很多作业在执行,资源使用也已经达到一个瓶颈,这时候就需要去扩容或者降低业务量,来避免这种情况出现。
2. 作业长时间执行不出来,并且有很多作业在排队,整体业务受到阻塞。
- 此类情况可以继续使用上述查询pgxc_stat_activity的语句,查看语句的运行情况,结果可能如下:
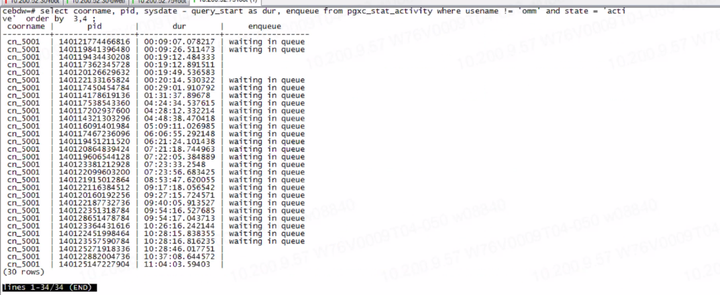
如图:图中最下方的两个作业,执行时间已经达到了11小时,但是仍然没有执行完,后面还有未执行的语句在排队。整体对于客户来说就是数据库已经hang死了,什么作业都执行不出来。
排查步骤
- 排查当前集群是否在使用动态自适应功能,查看如下参数:
show enable_dynamic_workload; //查看该参数目前是否为打开状态(2020年的版本都是默认打开)
- 如果该参数打开,那么就要查看这几个正在运行作业目前的内存使用情况,大概率正是因为这几个作业一直使用着内存不释放,才会出现整体的排队情况。
通过连接cn 5001查询视图:
select * from pg_session_wlmstat where threadid = $query_id;

该视图可以看到某个语句使用了多大的内存,statement_mem字段可以看到我这个语句是使用了1G,但是实际情况中,1个语句使用几十个语句的情况很多。当一个或者几个语句的内存达到整个集群的总体可用内存上限,或者达到资源池上限的时候,就会使这些语句后面的语句开始排队。资源不放,排队不止。
- 处理方法
应急处理:及时将卡住的语句terminate,释放其占用的资源,后续进行优化之后再执行,优化手段很多,包括计划调优,analyze等操作,都可以避免一个语句占用太大内存,也可以提升执行效率。
3. 全局资源可用内存很多,资源使用很小,并发数量也没有达到上限,但是查询显示很多作业处于排队状态。
举例:查询pgxc_stat_activity时,语句的执行状态如下:可以看到,所有语句都在waiting in ccn queue,只有两个语句在运行。此时集群设置的max_active_statements是40,但是该用户实际活跃数量只有2个。
举例:查询pgxc_stat_activity时,语句的执行状态如下:可以看到,所有语句都在waiting in ccn queue,只有两个语句在运行。此时集群设置的max_active_statements是40,但是该用户实际活跃数量只有2个。
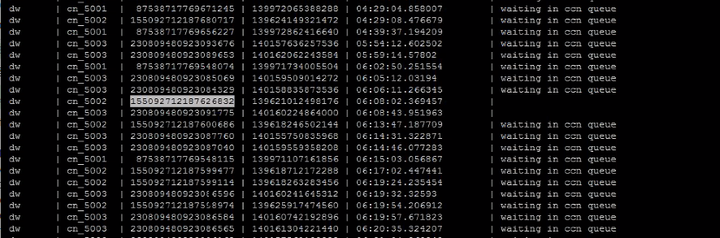
- 首先,出现出现waiting in ccn queue的情况,就一定是开启了内存自适应功能(enable_dynamic_workload=on)。此时只有两种情况,第一种是全局资源不足,会排队,第二种是用户所属的资源池内存不足,也会排队。
- 根据图中的现象,我们看到很多语句都在排队,这时候要查询一个排队视图:select * from pg_stat_get_workload_struct_info();
这个视图可以清晰看到作业是在哪里排队:
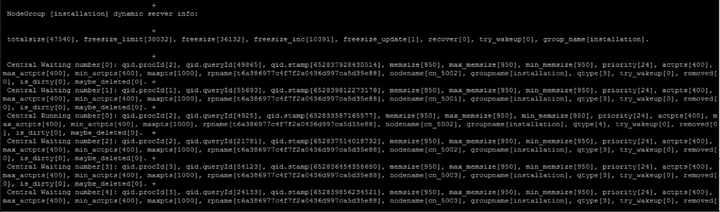
首先,上图中有totalsize,这个就是总体可用的最大内存,freesize_limit:执行语句可用的最大内存,freesize:当前可用的最大内存。
所以可以得出结论,此时不是在全局排队,全局内存freesize足够,那么作业就是在资源池排队,资源池排队也会显示waiting in ccn queue。
- 此时查询pg_session_wlmstat视图,可以看到正在运行的为dw用户,正在运行的语句占用的内存为两条各1G。
可以通过界面或者后台查看一下,这个用户对应的租户上,是不是做了内存资源限制:
查看租户界面内存配置如下:
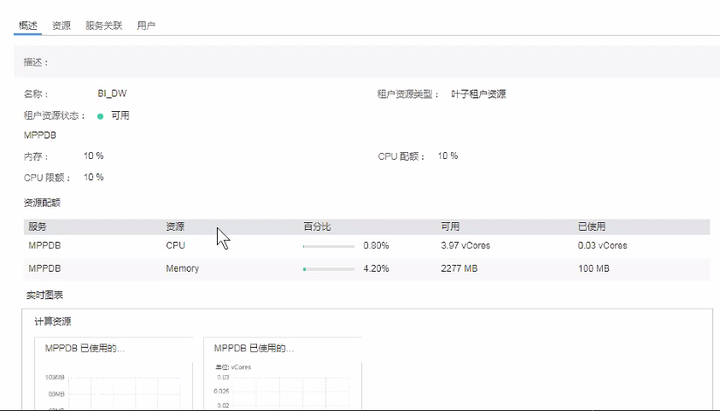
可以看到图中给这个租户或者说给这个用户所在的资源池配置了10%的内存配额,一共是2277MB,即2G左右。
因此这种场景下,内存资源只能满足当前两个语句的执行,其余属于该用户的语句都会进行排队。
- 处理办法:
- 方法一、此类问题,若在资源允许的情况下,可以适当调大租户相关的内存资源,让更多语句能够同时运行。
- 方法二、优化相关语句的执行效率,缩短执行时间,让语句可以高效执行,避免大量堆积。
4.执行的作业基本都是一个用户的,其余用户的作业基本都在排队中无法执行。
举例:之前某局点出现高并发DDL的情况,该类高并发DDL在全局并发计数中会受到统计,占用max_active_statements中的并发数量。
比如:max_active_statements=20,其中某用户一直持续不停地下发DDL,此时在DWS设计ap场景并未涉及此类场景。会出现该20个并发设置普遍被该用户占用的情况,其他用户可能出现连不上的情况。
这种场景下,即时再调大并发,也会再被该用户的DDL语句占用。
处理方案:
针对高并发DDL的不合理业务场景进行优化,比如把连续创建删除临时表的动作,改为对永久表的操作,此时就可以极大幅度减少DDL并发数量,保证自身业务以及其余用户业务的正常连接和运行。
四、部分场景配置方案
1. 限制单用户并发
用户的作业分为以下几种,DDL/DML/以及常规查询,在DWS的视角中,常规查询有分为简单查询和复杂查询。
对于DWS的两层管控,受到第一层管控的有DDL、start transaction、DML、常规查询等,基本是所有语句,只有内部线程的语句(比如WLM线程)以及超级用户权限的用户执行的作业。
受到第二层管控的语句,主要是可以从优化器获取到具体执行计划以及执行代价的语句。
除了DDL/start transaction 之类的语句,以及部分白名单语句,此类语句都是视为基本不消耗资源,并且不会造成阻塞的语句。
针对目前的管控机制来说,可以将单个用户关联到一个单独的资源池,这个资源池不设置内存配置,只设置并发配置,达到进行作业管控的效果。
具体步骤及解释如下:
1.在所有节点创建好控制组
gs_ssh -c "gs_cgroup -c -S class_a" gs_ssh -c "gs_cgroup -c -S class_a -G workload_a"
2.创建业务资源池(此时可以同步设置max_dop参数,active_statements会限制复杂作业的并发数量,max_dop参数会限制简单作业的并发数量)
create resource pool p1 with (control_group="class_a:workload_a"); alter resource pool p1 with (active_statements=10,mem_percent=0,max_dop=1);
3.关联用户与该资源池
ALTER USER testuser RESOURCE POOL 'p1';
五、小结
并发管理的用处,主要是为了防止用户跑太多的作业,导致集群负载过大,资源发生争抢,系统不能稳定运行,会因为资源出现各种问题,CPU/内存/IO,哪一个都是让人头疼的问题,并发控制也可以同步控制某一个用户的并发作业,避免因为一个用户的作业数量太大,导致其他用户在使用数据库的时候出现问题。
负载管理最主要的现象就是会出现作业排队的情况,排队是否合理,是否因为不合理的参数配置导致大量的业务阻塞;或者配置正常,但是没有达到上限就出现排队,本文的主要目的就是解决此类问题,或者及时定界到是什么原因导致了阻塞。
实际使用过程中,许多时候出现排队的情况,都可能和正在执行的语句有关,正在执行的语句占用着这个位置,又执行不完,其余语句自然会排队。因此我们碰到语句大量阻塞的情况,要迅速定界到是因为什么而造成阻塞,怎么样能恢复正常使用。找到问题的语句后,要及时去将它做一些适当的调优,避免再次执行到这个语句,还会出现一样的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号