MindSpore手写数字识别初体验,深度学习也没那么神秘嘛
摘要:想了解深度学习却又无从下手,不如从手写数字识别模型训练开始吧!
深度学习作为机器学习分支之一,应用日益广泛。语音识别、自动机器翻译、即时视觉翻译、刷脸支付、人脸考勤……不知不觉,深度学习已经渗入到我们生活中的每个角落,给生活带来极大便利。即便如此,依然有很多人觉得深度学习高深莫测、遥不可及,的确,它有深奥之处,非专业人士难以企及,但也有亲和力十足的一面,让没有基础的小白也能轻松上手,感受深度学习的魅力,接下来要介绍的手写数字识别模型训练正是如此。
手写数字识别初探
手写数字识别是计算机视觉中较为简单的任务,也是计算机视觉领域发展较早的方向之一,早期主要用于银行汇款、单号识别、邮政信件、包裹的手写、邮编识别等场景,目前手写数字识别已经达到了较高的准确率,得到大规模的推广与应用。虽然手写数字识别本身的领域比较狭窄,实用性有限,但是在它基础上发展起来的卷积神经网络等计算机视觉技术早已应用在更为复杂的任务中,因此,手写数字识别也成为计算机视觉领域衡量算法表现的一个基准任务。所以,通过这一实践场景来了解神经网络开发和训练,可谓再好不过了。如何使用深度学习框架MindSpore进行模型开发与训练?又如何在ModelArts平台训练一个可以用于识别手写数字的模型呢?让我们来一探究竟吧。
数据集的选择与准备
机器学习中的传统机器学习和深度学习都是数据驱动的研究领域,需要基于大量的历史数据对模型进行训练,再使用模型对新的数据进行推理和预测,因此数据是机器学习中的关键要素之一。
MNIST数据集是目前手写数字识别领域使用最为广泛的公开数据集,大部分识别算法都会基于它进行训练和验证。MNIST数据集包含0~9这10种数字,每一种数字都包含大量不同形态的手写数字图片训练集,分为训练集和测试集。训练集涵盖6万张手写数字图片,测试级涵盖1万张手写数字图片。每一张图片皆为经过尺寸标准化的黑白图像,是28*28像素,像素值为0或者1的二值化图像。MNIST数据集的原始图像是黑白的,但在实际训练中使用数据增强后的图片能够获得更好的训练效果。
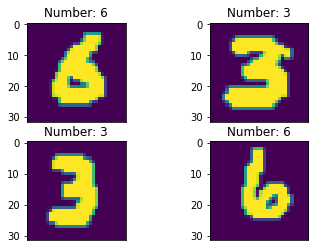
本次训练所使用的经过数据增强的图片
基于深度学习的识别方法
与传统的机器学习使用简单模型执行分类等任务不同,此次训练我们使用深度神经网络作为训练模型,即深度学习。深度学习通过人工神经网络来提取特征,不同层的输出常被视为神经网络提取出的不同尺度的特征,上一层的输出作为下一层的输入,层层连接构成深度神经网络。
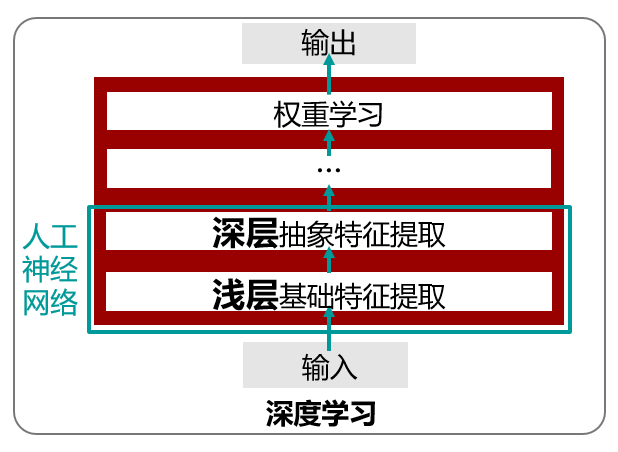
深度学习工作原理
1994年,Yann LeCun发布了结合反向传播的卷积神经网络 LeNet, 其在手写数字识别领域效果远超其他模型。1998年,Yann LeCun等人构建的卷积神经网络LeNet-5在手写数字识别问题中取得成功 ,被誉为卷积神经网络的“Hello Word”。LeNet-5以及在此之后产生的变体定义了现代卷积神经网络的基本结构,可谓入门级神经网络模型。本次实践使用的模型正是LeNet-5。
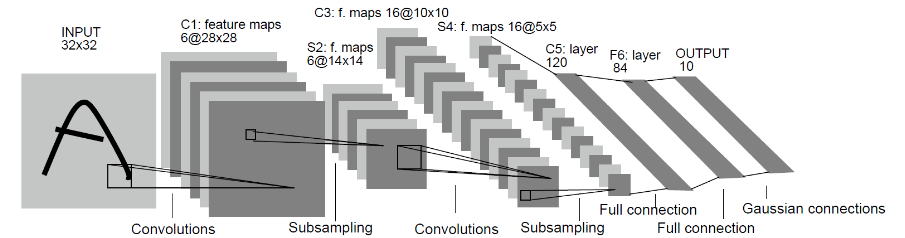
LeNet-5结构
LeNet-5由输入层、卷积层、池化层和全连接层组成。输入层用于输入数据;卷积层通过卷积运算对输入进行局部特征提取;池化层通过下采样的方式降低特征图的分辨率,从而降低输出对位置和形变的敏感度,同时还可降低网络中的参数和计算量;全连接层将局部特征通过权值矩阵组装成完整的图像,完成特征空间到真实类别空间的映射,最终的图像分类便是由全连接层完成的。有了这样一个神经网络后,我们还需要用大量数据集对它进行不断地训练,才能对输入数据有较为准确的预测结果,这一过程便依赖于华为自研的深度学习框架MindSpore。
MindSpore的“学习”过程
MindSpore当前已经部署在ModelArts的开发环境和训练环境中,同时提供了阈值算法供开发者直接使用,它的学习过程如下图所示,简单总结一下:
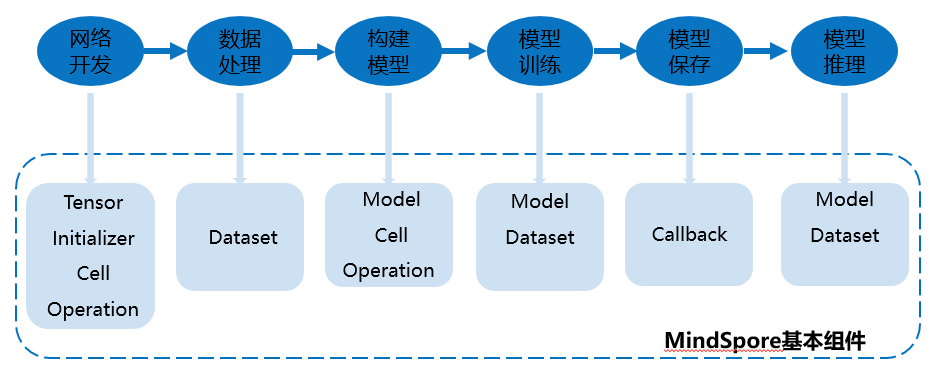
1. 使用MindSpore提供的基本模块进行前线网络开发
2. 对数据进行处理和增强以便得到更好的数据输入
3. 利用前线网络构建训练模型,并进行模型保存和推理
说起来可能平淡无奇,但是实验终究需要自己亲自动手才能体会其中的无限乐趣。
看到这里,想必各种背景知识和原理大家已经略知一二,如果你已经跃跃欲试,那就快来华为云学院学习微认证课程《使用MindSpore训练手写数字识别模型》吧。对了,悄悄告诉你,这个实验现在还是免费的哟,来华为云学院沙箱实验室就能即刻体验。从原理到实践,带你全方位了解手写数字模型训练全过程,快速上手深度学习,速来!
本文分享自华为云社区《MindSpore手写数字识别初体验,深度学习也没那么神秘嘛》,原文作者:学院小助 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号