
Underlay网络:如何立住可靠又支持大规模无收敛的“人设”
摘要:Underlay网络要如何演进,才能满足5个9的指标?
这几年公有云业务急速上涨,network as a service理念越来越深入人心。云厂商给租户提供了越来越丰富的云服务,VPC、LB等服务功能越来越完善。这需要网络提供灵活编程的能力,可以针对租户的业务诉求迅速改变策略。而这一理念其实与传统的网络是背道而驰的。在传统网络观念中,信奉“稳定压倒一切”的套路,为了保证网络稳定,需要尽量减少对于网络的配置变更。那么,在云的环境下,网络如何自处才能满足既稳定又灵活的要求?
为满足云业务的需要,网络逐渐分化为underlay和overlay。Underlay网络就是传统数据中心的路由交换设备,依然信奉稳定压倒一切的理念,提供可靠的网络数据传输能力;overlay则是在其上封装的业务网络,更加跟服务贴近,通过VXLAN 或者GRE等协议封装,给租户提供一个易用的网络服务。Underlay网络和overlay网络即关联又解耦,两者相互关联又能独立演进。
今天主要是讲一下underlay网络的演进策略。Underlay网络是整个公有云的地基,承载网络不稳,业务便无SLA可言。特别随着云上承载的业务越来越庞大,客户越来越多,对于underlay网络的稳定性要求越来越高。Underlay网络要如何演进,才能满足5个9的指标?
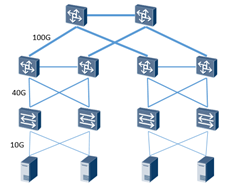
传统的“胖树”网络,结构简单,维护方便,但是随着组网规模的扩大,却存在很多问题。
1、 二层稳定性问题
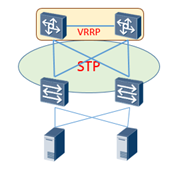
传统以POD为拓展交付单元的网络,POD使用大规格交换机做汇聚,POD内多为二层组网。破解二层环路的常用方案有2种:STP+VRRP、堆叠
VRRP+STP是传统数据中心最常用的组网方案,网关通过VRRP冗余,环路通过STP破环,真是传统网络的“黄金搭档”。然而,随着组网规模做大,当TOR的数量达到100台以上时,stp协议会面临较大挑战,计算偶然性错误,收敛时间慢等。100台TOR,按每台40个下行口计算,服务器双归接入,可以支持规模2K。规模也还算可观,可一旦STP出现问题,2K服务器全都受影响,就不太能接受了。
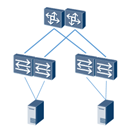
堆叠,堆叠可以直接规避掉环路的问题,维护起来也简单很多。可是堆叠终究也是一个大二层,大二层就存在风暴一起瘫的风险。并且堆叠系统无法平滑升级,一直是运维工程师心中的痛,汇聚一堆叠,升级的风险就太大了。
2、 带宽收敛问题
胖树结构,通过增加上层设备的线路带宽和线路数量的方式增加带宽。但随着规模的增加,下挂服务器越来越多,TOR越来越多,汇聚到核心的连线往往不足以实现无收敛组网。且再多的连线,都是从某台设备上出来的,此设备故障,带宽损失太严重。
3、 拓展性问题
按照AWS提供的数据,一个云数据中心的规模,在6W时的规模收益是最大的。而胖树方案要支持6W台服务器接入,基本不太可能。哪怕真的接上了,任何一台骨干设备故障,引起的网络问题是难以预计的。就跟电影《长城》中饕餮的阵型一样,所有饕餮都围绕兽王行动,兽王一死全军覆没。
那么在公有云的业务诉求中,underlay网络如何发展,才能满足它即可靠又支持大规模无收敛的“人设”呢?那当然是clos,scale out,anycast等潮流玩法(也没那么潮流,人家10年前就做出来了)
给大家分享一下google和Facebook的做法,这两家公司的组网堪称业绩标杆。
Google:
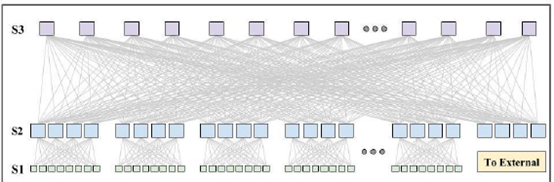
Google还是保留了类似于POD的概念,但他们的POD有4台汇聚,而且上行所对接的核心数量,想要多少有多少,完全超出了传统的范畴。N个核心之间与每一个POD汇聚之间都有互联,任意两个POD之间,有4*N条线路互通,任意一条挂掉,基本无影响。
POD四台汇聚,网关在哪里?这么多条线路,怎么做的管理和路由?
要做成这样的组网,肯定不是改改连线方式就能搞定的。underlay的网关需要下沉到TOR上,TOR上行汇聚直接跑动态路由协议,汇聚和核心之间也跑动态路由协议,形成多条等价路径。报文可以随意转发,条条大路通罗马。
传统的OSPF、BGP等动态路由协议,能支持的ECMP路径毕竟是受限的。Google自己改造了传统的动态路由协议,让他可以支持更多地等价路径,更快速地发现线路问题。
Facebook:
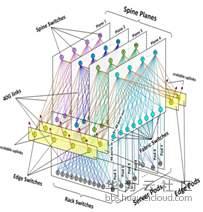
上图是Facebook典型的乐高组网,分了多个层次多个平面。下层的每一个平面对应了一个POD,POD的汇聚有自己组成多个平面与核心之间组成一个上一级POD。
这样看可能会有点晕,我们简化一下如下:

- 每一个POD有48台TOR,每台服务器只出1根线接入到1台TOR
- 每一台TOR上行对接4个汇聚,每一个汇聚上行对接48个核心
- 任意2台服务器之间,有4*48=192条通路
- 任意1台TOR故障,软件自己做冗余,业务不受影响
- 任意1台汇聚或核心故障,业务基本不感知
这样的组网,业务跑在上面,是不是有一种很踏实的感觉。
总结一下这两家公司网络的特点:
1、去中心化,不再存在唯一的汇聚或者核心,而是拓展了多台
2、网关下沉到TOR,TOR以上为路由转发,抑制二层广播域扩散
3、多条等价路径,核心汇聚之间线路冗余高,任何一台设备一条线路故障基本无影响
以上是我们可以直接从物理图上看出来的,而在“看不到”的地方,还做了更多地优化:
1、 硬件设备控制器,所有设备统一管理,配置标准化
2、 设备监控信息上报通道,任何链路皆有完善监控
3、 流量调度能力,线路有拥塞,流量调度到其他链路
当然,还有好多优化,是笔者无法知道的,但这些优化肯定都有一个共同的目的:网络更加稳定。
互联网的设计理念,永远不相信单点的可靠性。要通过冗余设计,达到任何一个节点故障,均无法影响整体业务的目的。基础网络也是如此,随着云上承载的业务越来越多,若底层网络不稳定,受损的业务会越来越多,造成的损失不是扛可以扛过去的。所有底层网络的设计理念,必然要围绕“无论如何业务都不能down”的方向努力。Google、Facebook的组网算是我们的先驱,国内的各个云厂商其实也在用类似的组网方案。
物理架构的fabric,带来的是工程上的可靠性。而很多的故障模式,物理架构不一定能cover住。还必须要设计出与之匹配的软件,才能更好的保证网络的稳定运行。相比于物理架构来说,监控、调度等软件能力的补齐更加重要。
现在越来越多的公司在推行“白牌”交换机,其实是把传统交换机的系统打开了,给传统封闭的交换机系统打上API接口,可以通过编程系统直接调度,获取内部更多信息,以方便针对各种情况,做出调整。比如,交换机丢包分析,远程抓包,指定流监控,指定流调度等能力。
传统的交换机,虽然功能齐全,但是相对于公有云来说,齐全的功能未必不是一种累赘。刚好齐全的功能,加上开放可编程的系统,才是云的需要。你看,AWS都要自己出交换机了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号