技术实操丨SoundNet迁移学习之由声音分类到语音情感识别
摘要:声音也是识别对象的一种重要数据源。其中根据声音来识别声音所处的环境也是语音识别的研究内容之一。
一、思路
1、SoundNet模型在视频数据中先预训练,视频任务可能是场景识别,可参考这篇文章SoundNet: Learning Sound Representations from Unlabeled Video。
2、迁移学习:5层的soundnet只取前3层作为迁移层,在新数据集中训练时保持着三层不变,其余两层随机初始化,再训练。
3、在新数据如IEMOCAP中fine-tuning
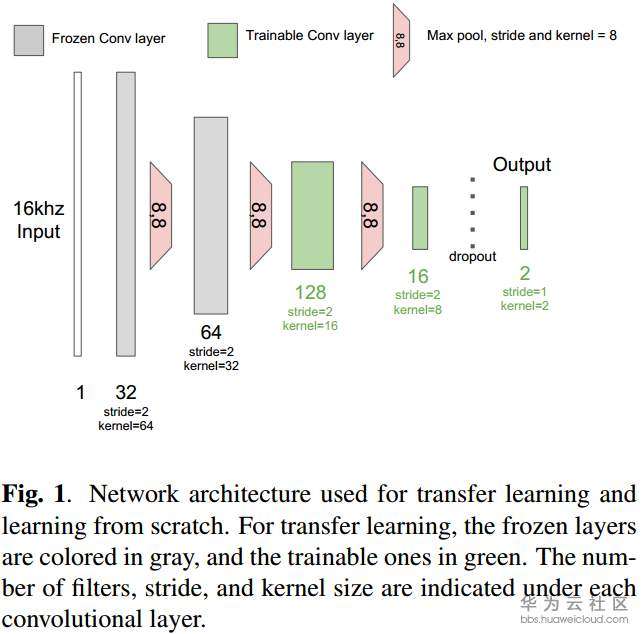
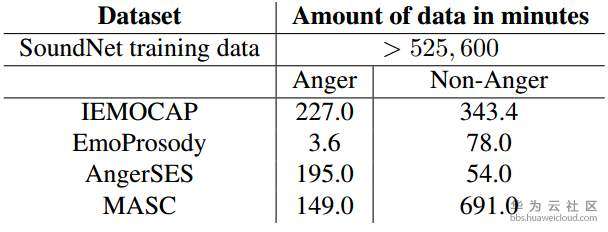
二、实验数据
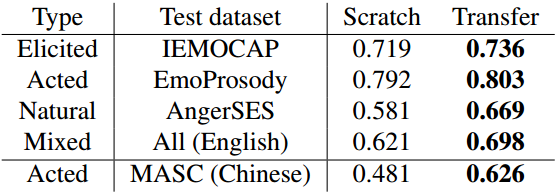
三、实验结果
评价指标:AUC
Scratch表示随机初始化的SoundNet。
四、总结
1、面对音频数据稀缺,给出了很好的解决思路,可根据SoundNet文章中的思路,先从视频数据入手,学习SoundNet参数,然后应用到自己的场景中;
2、跨语言迁移学习:文章中从英语场景迁移到汉语场景,效果比单一数据训练提升很大;
3、YFCC100m 、Google AudioSet可用于预训练模型。
参考文献:
[1] ElShaer M E A, Wisdom S, Mishra T. Transfer Learning From Sound Representations For Anger Detection in Speech[J]. arXiv preprint arXiv:1902.02120, 2019.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号