

实践案例丨ACL2020 KBQA 基于查询图生成回答多跳复杂问题
摘要:目前复杂问题包括两种:含约束的问题和多跳关系问题。本文对ACL2020 KBQA 基于查询图生成的方法来回答多跳复杂问题这一论文工作进行了解读,并对相关实验进行了复现。

1、摘要
1.1 复杂问题
1)带约束的问题
2)多跳关系问题
1.2 提出一种改进的阶段式查询图生成方法
1.3 三份数据集上达到SOTA:CWQ、WQSP、CQ
2、介绍
2.1 复杂问题
(1)单跳关系带约束的问题
- Who was the first president of the U.S.?
- 单跳关系:“president_of”
- 已知实体:“U.S.”
- 约束词:“first”
(2)多跳关系问题
- Who is the wife of the founder of Facebook?
- 两跳关系:“wife_of”、“founder_of”
2.2 解决方法:考虑更长的关系路径,但是搜索空间会随着路径的变长呈指数性增长
2.3 挑战:如何限制搜索空间?以前也有一些方法,提出的只考虑匹配的最佳关系,而不是所有关系。但是没有同时处理两种类型的复杂问题。
2.4 方案:束搜索(beam search)
2.5改进:路径扩展 + 合并约束,串行 → 并行,有效地减少了搜索空间
3、方法
3.1、预备工作
(1)KB
- K={(h,r,t)}
- h,t 来自实体集合 E
- r 来自关系集合 R
(2)KBQA:给定一个问题Q,从KB中找到一个答案a
3.2、阶段查询图方法
(1)四种类型的节点,如下图所示
- A grounded entity 接地实体/对齐实体:KB中已存在的一个实体,至少有一个(阴影矩形)
- An existential variable 未接地实体/存在变量/中间变量:0个或者多个(无阴影矩形)
- A lambda variable 未接地实体/未知变量:表示答案,有且只有一个(圆形)
- An aggregation funciton 聚合函数:最大/最小/求和等操作,0个或者多个(菱形)
(2)查询图的边是KB中的 r
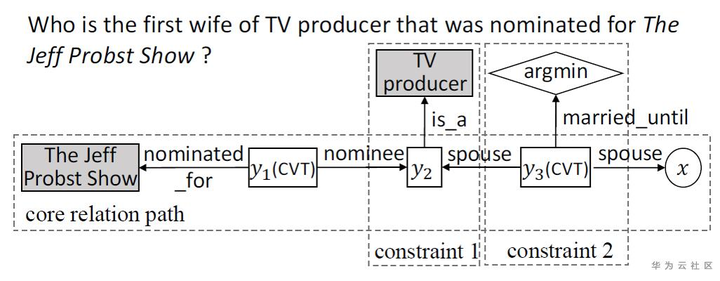
(3)查询图的生成过程就是SPARQL查询语句生成的过程,如下图所示。注:与上图例子不完全符合。
其中,ns:m.0k2kfpc 是接地实体的MID(Freebase),?name3 是未知变量,?e1、?e2、?e3、?e4 等是中间变量。

3.3、阶段查询图生成的一般过程
1)从问句中的一个接地实体(topic entity)开始,识别一条核心关系路径(core relation path),将主题实体连接到一个lambda变量;
2)给核心关系路径添加一个或多个约束,这个约束包含一个接地实体或者一个带关系的聚合函数;
3)生成候选查询图,度量和问句的相似度,排序(CNN等神经网络);
4)取top1,在知识图谱上执行查询图,获得答案。
注:核心关系路径,在其他论文里叫核心推理链,或者叫基本查询图
3.4、动机
(1)问题:
- 已有方法只考虑单个关系或两个关系的核心路径,无法解决多关系约束问题;
- 如果允许核心关系路径变长,搜索空间会剧增;
- CWQ数据集上,每个问题三跳情况下会有10000条路径。
(2)束搜索(beam search)
- 在生成 t+1 跳关系路径时,只保留 top-K 个 t 跳关系路径,即每次路径只生成 K 个;
- 已有方法忽视了约束这个条件,只考虑通过路径减少搜索空间;
- 问题中的约束也可以帮助减少搜索空间,引导核心路径朝正确的方法生成。
(3)改进的阶段式查询图生成方法
- 在附加约束前,不需要生成所有的核心关系路径;
- 束搜索和语义匹配结合,得到一个更小的搜索空间。
- 给定一个部分核心路径 (The Jeff Probst Show, nominated for, y1, nominee, y2),如果在y2上扩展一个关系,需要考虑KB中连接y2的所有关系,但是如果先加一个约束(is a, TV producer),将只考虑电视制片人被提名为xx show的人。
3.5、查询图生成
(1)束搜索生成查询图
- 假设第 t 次迭代生成了 K 个查询图,表示为 G_t;
- 第 t+1 次迭代,对于每个图 g∈G_t,使用三个操作 {extend, connect, aggregate} 增加一条边和一个节点,如下图所示;
- 所有生成的图集合表示为 G′_(t+1) ,使用得分函数排序,取 top-K 个 ,得到候选查询图 G_(t+1);
- 继续迭代,直到没有 g∈G_(t+1) 得分比 g∈G_t 高。

(2)扩展操作(extend)
- 增加一个关系;
- 如果当前查询图只有一个主题实体 e,扩展操作就增加 e 的一个关系 r ,另一端作为lambda变量 x ;
- 如果当前查询图含有一个lambda变量 x ,扩展操作就将 x 转成一个existential变量 y ,找到 y 的关系 r ,生成新的lambda变量 x 。
(3)连接操作(connect)
- 除了主题实体外,问题中经常会出现一些其他的接地实体 e ;
- 连接操作将这个接地实体 e 链接到 lambda 变量 x 或者与 x 连接的existential变量。
(4)聚合操作(aggregate)
- 预定义一个关键词集合,检测约束词;
- 聚合操作将约束词作为一个节点连接 lambda 变量 x 或者与 x 连接的existential变量。
(5)方法的创新性:扩展操作可以应用在连接或者聚合操作后面,以前的方法不行。
- 以前:扩展 → 扩展 →......→ 扩展 → 连接或聚合
- 现在:扩展、连接、聚合 → 扩展、连接、聚合 →......→ 扩展、连接、聚合
3.6、查询图排序
(1)方法:第 t 次迭代,排序候选查询图 G′_t,通过生成一个7维的特征向量,输入到全连接层,计算分数。
(2)特征
第1维:
- 基于BERT的语义匹配模型;(Pytorch版:https://github.com/huggingface/transformers)
- 将查询图 g∈G′_t 转成一个词序列,按照图的生成顺序
- 忽视中间变量和未知变量
- 下图的查询图生成的序列:(the, jeff, probst, show, nominated, for, nominee).

第2维:所有接地实体的实体链接得分累加和;(谷歌的实体链接工具:https://developers.google.com/knowledge-graph)
第3维:接地实体的数量;
第4维:实体类型的数量;
第5维:时间表达式的数量;
第6维:最高级表达式的数量;
第7维:答案实体的数量。
(3)强化学习方法,学习决策函数。
4、实验
(1)数据
- ComplexWebQuestons (CWQ) 数据量:34689
- WebQuestionsSP (WQSP) 数据量:4737
- ComplexQuestions (CQ) 数据量:2100
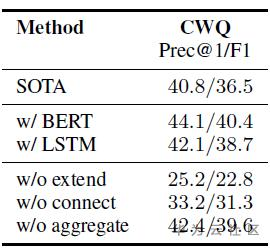
(2)结果

(3)消融实验
模型性能的提升,不仅仅与BERT有关。
论文:Lan Y, Jiang J. Query Graph Generation for Answering Multi-hop Complex Questions from Knowledge Bases[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 969-974.
链接:https://www.aclweb.org/anthology/2020.acl-main.91/
代码:https://github.com/lanyunshi/Multi-hopComplexKBQA

