案例解析丨 Spark Hive 自定义函数应用
摘要:Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数。
1. 简介
Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数。UDF使用场景:输入一行,返回一个结果,一对一,比如定义一个函数,功能是输入一个IP地址,返回一个对应的省份。UDTF使用场景: 输入一行,返回多行(hive),一对多, 而sparkSQL中没有UDTF, spark中用flatMap即可实现该功能。UDAF: 输入多行,返回一行, aggregate(主要用于聚合功能,比如groupBy,count,sum), 这些是spark自带的聚合函数,但是复杂相对复杂。
Spark底层其实以CatalogFunction结构封装了一个函数,其中FunctionIdentifier描述了函数名字等基本信息,FunctionResource描述了文件类型(jar或者file)和文件路径;Spark的SessionCatalog提供了函数注册,删除,获取等一些列接口,Spark的Executor在接收到函数执行sql请求时,通过缓存的CatalogFunction信息,找到CatalogFunction中对应的jar地址以及ClassName, JVM动态加载jar,并通过ClassName反射执行对应的函数。

图1. CatalogFunction结构体
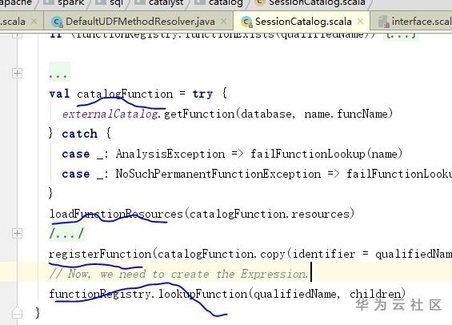
图2. 注册加载函数逻辑
Hive的HiveSessionCatalog是继承Spark的SessionCatalog,对Spark的基本功能做了一层装饰以适配Hive的基本功能,其中包括函数功能。HiveSimpleUDF对应UDF,HiveGenericUDF对应GenericUDF,HiveUDAFFunction对应AbstractGenericUDAFResolve以及UDAF,HiveGenericUDTF对应GenericUDTF
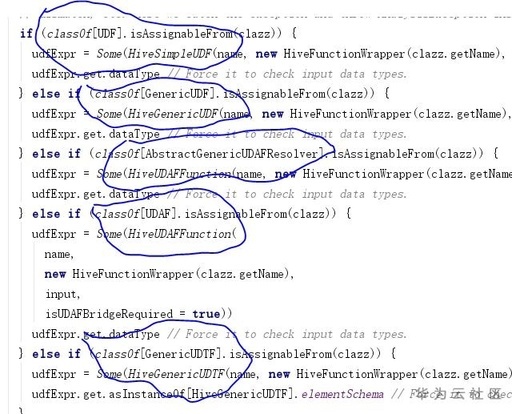
图3. Hive装饰spark函数逻辑
2. UDF
UDF是最常用的函数,使用起来相对比较简单,主要分为两类UDF:简单数据类型,继承UDF接口;复杂数据类型,如Map,List,Struct等数据类型,继承GenericUDF接口。
简单类型实现UDF时,可自定义若干个名字evaluate为的方法,参数和返回类型根据需要自己设置。因为UDF接口默认使用DefaultUDFMethodResolver去方法解析器获取方法,解析器是根据用户输入参数和写死的名字evaluate去反射寻找方法元数据。当然用户也可以自定义解析器解析方法。

图4. 自定义UDF简单示例
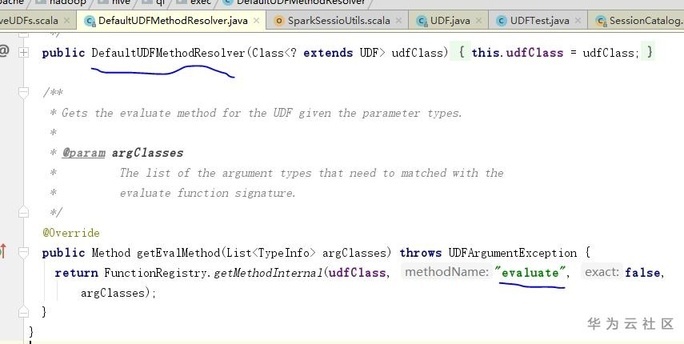
图5.默认UDF方法解析器
3. UDAF
UDAF是聚合函数,目前实现方式主要有三种:实现UDAF接口,比较老的简答实现方式,目前已经被废弃;实现UserDefinedAggregateFunction,目前使用比较普遍方式,按阶段实现接口聚集数据;实现AbstractGenericUDAFResolver,实现相对UserDefinedAggregateFunction方式稍微复杂点,还需要实现一个计算器Evaluator(如通用计算器GenericUDAFEvaluator),UDAF的逻辑处理主要发生在Evaluator。
UserDefinedAggregateFunction定义输入输出数据结构,实现初始化缓冲区(initialize),聚合单条数据(update),聚合缓存区(merge)以及计算最终结果(evaluate)。
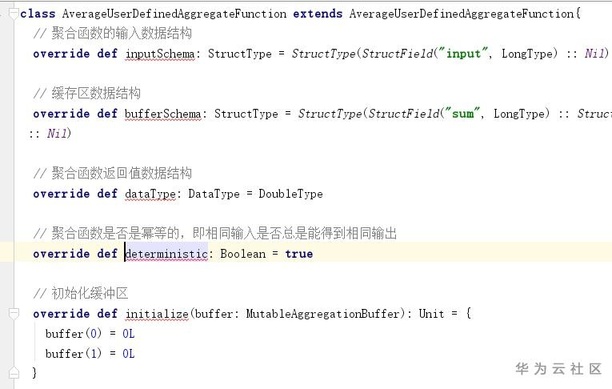

图6.自定义UDAF简单示例
4. UDTF
UDTF简单粗暴的理解是一行生成多行的自动函数,可以生成多行多列,又被称为表生成函数。目前实现方式是实现GenericUDTF接口,实现2个接口,initialize接口参数校验,列的定义,process接口接受一行数据,切割数据。


图7.自定义UDTF简单示例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号