

宿舍晚上温度高,那是你没听“鬼故事”
摘要:天热嘛,出身冷汗就好了。这次给大家准备了一个AI鬼故事生成器,保证用完让你瑟瑟发抖。
Hello大家好,我是B站UP主苏苏思量,最近又要开学了。
不禁让我想起之前读书时候,宿舍没空调,晚上睡不着的经历。
所以,用代码为大家排忧解难的我又来了!
天热嘛,出身冷汗就好了。

这次给大家准备了一个AI鬼故事生成器,保证用完让你瑟瑟发抖。
这个生成器的本质就是喂给AI模型一些鬼故事后,让它进行自由文本生成。
文末有福利哦,千万不要错过!
说起生成中文,这次我用的是OPENAI发布的GPT 2模型结合pytorch来进行训练。
首先设置输入参数,包括词库地址,是否预处理,学习率,最短字数等等等等。
然后声明一个全新的GPT2模型。
为了在稍后的迭代中看到实时进度条,还得加一个tqdm模块。
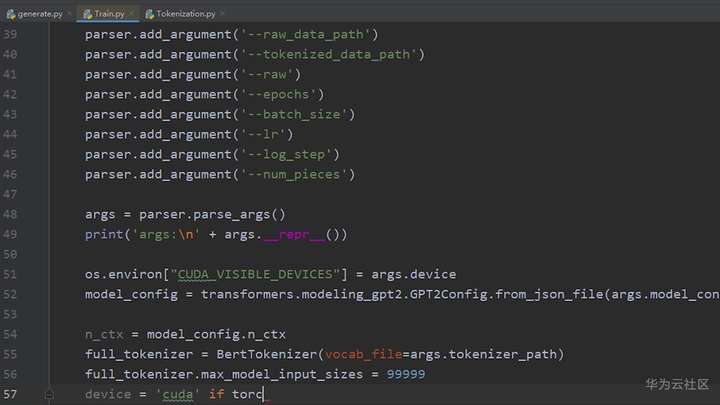
但是!
我的个人电脑配置是英特尔i7加英伟达GEFORCE GTX的GPU。
之前用几百K的数据训练一个SVM都得将近一小时。这次训练这么高级的模型,不得跑一周吗!

为了提高训练效率,还是得上云,来吧华为云ModelArts在线写码在线调试。
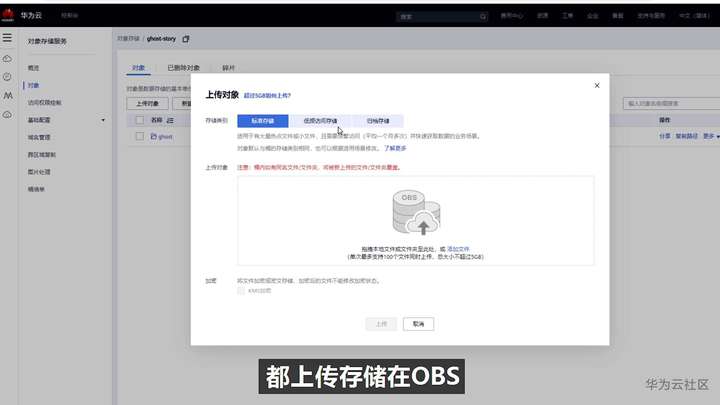
首先把刚刚的文件都上传存储在OBS。
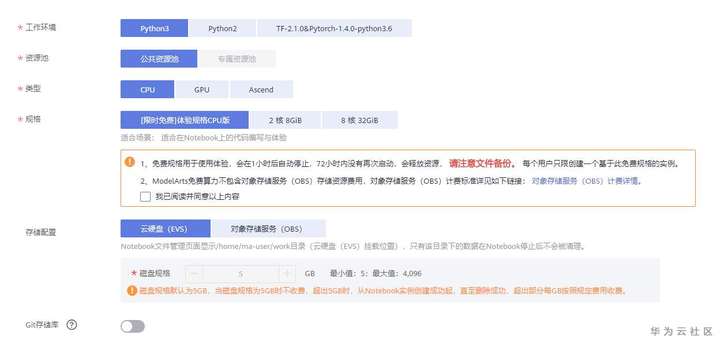
然后回到ModelArts,左侧“开发环境”-“notebook”,这里既可以选择免费体验版,也可以选择付费加速版(结尾有福利,可以领取免费试用付费版哦)。
在本地读取指定路径下的文件要写成这样:
model_config = transformers.modeling_gpt2.GPT2Config.from_json_file("文件在本地的地址")
在modelArts的notebook里要使用华为云的moxing包
import moxing as mox mox.file.make_dirs('/cache') mox.file.copy_parallel('obs://{obs桶名称}/{桶内文件地址}', '{执行机中地址}') model_config = transformers.modeling_gpt2.GPT2Config.from_json_file(''{执行机中地址}'')
在本地读去用户传进来的参数的时候,是这样的:
args = parser.parse_args()
但是在modelArts的notebook里调试的时候,要改成这样。
args, unparsed = parser.parse_known_args()
Notebook支持分块执行,调试起来也更加轻松。
接着把数据按照刚刚设置的epoch和batch size分割。
然后传递给pytorch去构建张量。
接着设置前向传播,损失函数,反向传播,优化步骤。
全部设置好,之后,就可以开始训练啦!
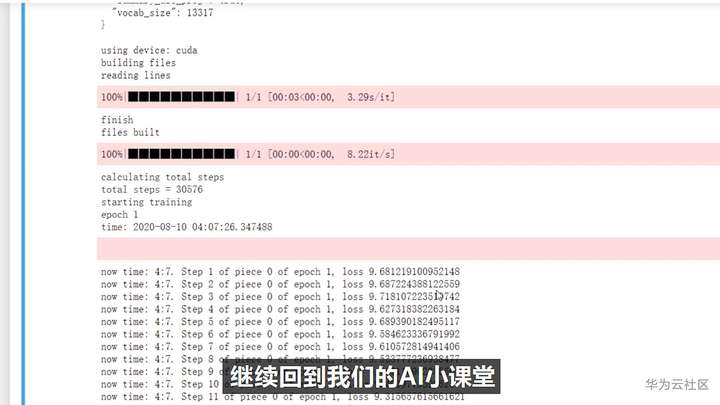
果然烧别人家的GPU就是不心疼,本来可能要一周的项目,很快就训练好了。
现在来试一下给你们的开学礼物的效果吧。
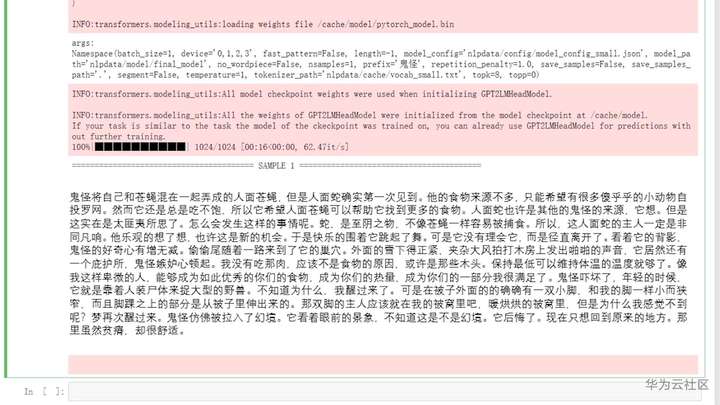
附件给大家提供了所有文件和一个简化版的训练文本(只有几百K,训练起来很快,方便大家快速拿到结果,早点来抢礼物哟)
只需要把nlpdata文件夹里的数据传到OBS,然后把notebook1.py中的代码复制到ModelArts的notebook中的第一个模块,然后点击run;
接着把notebook2.py中的代码复制到下一个模块,然后把里面我的OBS文件地址,改成你的OBS内文件地址,点击run,就开始训练啦!
训练结束后,把notebook3.py中的代码复制到下一个模块,把里面我的文件的OBS文件地址,改成你的OBS内文件地址,点击run,就能生成属于你的鬼故事啦!
为了感谢大家对我的支持,特意为大家带来了2个福利,并且还有机会获得精美奖品哦(业界良心,全国包邮),欢迎大家参与。

