
技术实操丨使用ModelArts和HiLens Studio完成云端验证及部署
前言
HiLens Studio公测也出来一阵子了,亮点很多,我前些天也申请了公测,通过后赶快尝试了一下,不得不说真的很不错啊,特别是支持云端编辑代码,调试,甚至可以直接运行程序,即使自己的HiLens不在身边,也可以得到程序运行结果,不仅仅是云端IDE这么简单,更是有云端硬件资源支撑,极大降低了开发者负担,开发者只需要一台可以联网的电脑就行了,可以快速验证,验证通过后,直接安装到自己的HiLens上就能应用了,真是太棒了。
我尝试了将以前做过的Demo通过HiLens Stuido开发,真的很不错,很简单就能完成,值得一提的是,HiLens Studio支持模型转换,再也不需要通过ModelArts的模型转换与压缩功能转换模型了,直接在HiLens Studio中就能完成了,直接用在项目中就行,省去了模型传输的麻烦,可以说这次的HiLens Studio是集大成之作,在得到模型原型(TensorFlow的.pb模型或Caffe的模型)后,后续的模型转换、代码编写,调试,到最后的安装部署,都可以通过HiLens Studio来完成,特别是支持在线调试运行,没有HiLens都可以调试,这对于以前的嵌入式或边缘计算开发来说,是不敢想象的,这都是得益于华为云强大的硬件支撑和技术支持。
闲话少说,这次,我通过HiLens Studio完成基于YOLOv3_Resnet18的行人检测,这里为了简单,只对行人进行检测,如果你希望可以检测更多类别的目标,可以使用更多类别的数据集训练,相应的参照本文提供的utils.py做简单的代码修改即可,代码都会给的,也会加必要的注释哦,而且完整技能发布在了ModelArts的AI市场,欢迎大家体验,如果有问题,可以在下面回帖哦,对了,该技能基于最新的固件版本测试,在云端控制管理台显示为1.0.9版本,其他版本下未测试,注意版本哦。技能在AI市场的链接:https://console.huaweicloud.com/modelarts/?region=cn-north-4#/aiMarket/aiMarketModelDetail/overview?modelId=9d906199-b467-4a7e-9521-bc6a3031cf7b&type=hilens
正文
重要前提:你已经申请了HiLens Studio公测,并通过。同时,华为云账户有一定余额或代金券,模型训练和OBS需要一定花费,比较少。
整体流程是创建数据集(公开数据集即可)---->模型训练---->在HiLens Studio中完成模型转换---->编辑代码---->在线调试---->安装部署。下面来逐一介绍一下
1. 创建数据集
这里使用的数据集较大,是基于VOC 2007数据集中Person类别基础,收集网络图片和各公开数据集整理而成,从OBS桶下载需要耗费大量Money,分享也不太方便。不过,没关系,可以使用官方提供的数据集,无需上传到OBS桶,直接从官方桶中拷贝即可,但缺点是该数据集有行人和车两类,且行人较少,主要是车辆,不太适合,大体数据分布如下:
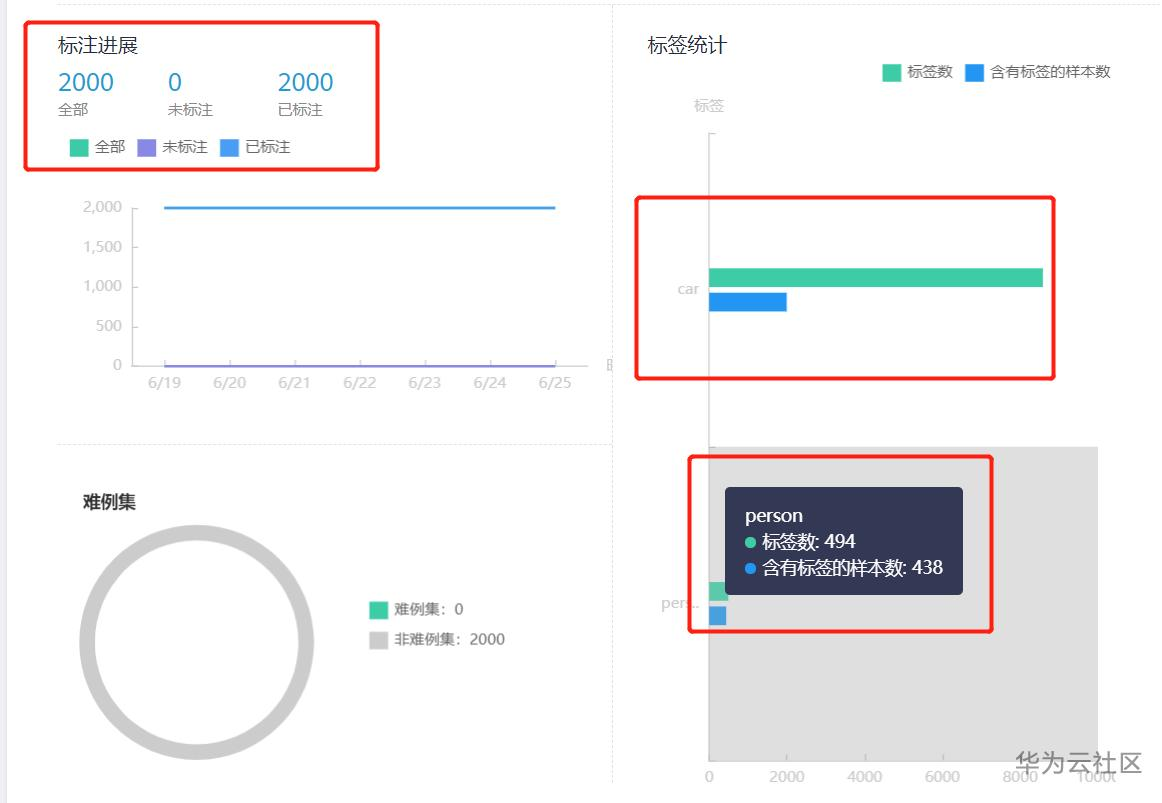
不过你可以考虑改为对车检测,或干脆直接人车检测(需要自己简单修改代码),可自行选择哦,关于如何获取该数据集,以及如何创建数据集,并发布数据集相关介绍较多,不在此赘述,可以参考这篇博客中的正文部分的方法哦,里面介绍了过程,链接为:https://bbs.huaweicloud.com/blogs/175189
2. 模型训练
说明一下,这里使用的是ModelArts中基于Ascend 910训练的YOLOv3_Resnet18。链接为:https://console.huaweicloud.com/modelarts/?region=cn-north-4#/aiMarket/aiMarketModelDetail/overview?modelId=7087008a-7eec-4977-8b66-3a7703e9fd22&type=algo ,同时,AI市场中有基GPU训练的YOLOv3_Resnet18和ModelArts预置算法中的YOLOv3_Resnet18,这两个应该也是可以的,只要最终得到.pb模型并能在HiLens Studio完成模型转换都应该没问题的哦,这两个算法链接分别为:https://console.huaweicloud.com/modelarts/?region=cn-north-4#/aiMarket/aiMarketModelDetail/overview?modelId=948196c8-3e7a-4729-850b-069101d6e95c&type=algo 和 https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0158.html#modelarts_23_0158__section185515526717
注意AI市场的算法需要先订阅(免费的哦),同步后才能创建训练,类似于你购买了该算法,并同步算法到自己的账户,相关介绍在博客中正文第三部分 模型训练中可查看,不过该博客讲的是YOLOv3_Darknet53,不是这里使用YOLOv3_Resnet18,不过没什么影响,只是名字不同,操作是类似的,链接:https://bbs.huaweicloud.com/blogs/175189
最后,提醒一下,无论使用哪种算法,都要用HiLens Studio来转换模型,不要使用ModelArts中的模型转换与压缩来做,因为我用的是最新的1.0.9固件版本,目前尝试,仅HiLens Studio转换模型才能正常使用。
3. 模型转换
对了,打开HiLens Studio需要一定时间,请耐心等待哦。
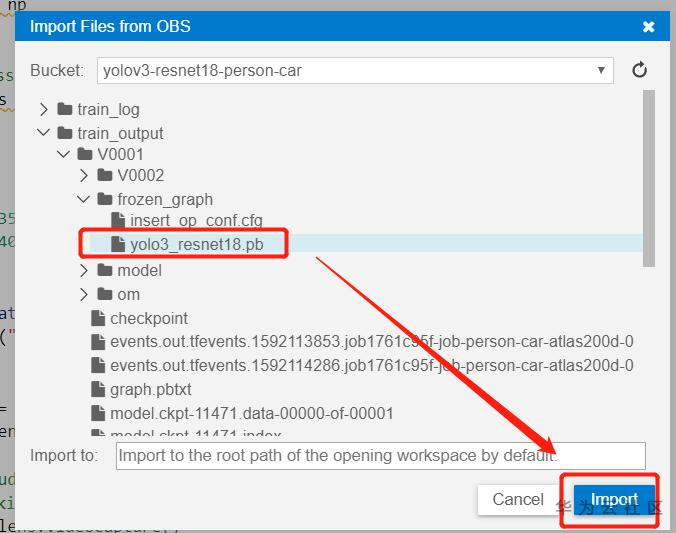
这里可以将模型训练输出到OBS桶的模型直接导入到HiLens Studio中,完成模型转换,非常方便,这真是极致的云端操作,将云服务发挥到了极致啊。当然,你也可以自己从本地电脑上传到HiLens Studio中哦。来看看怎么导入吧,很简单,选择Import Files from OBS,之后找到自己的模型存储再OBS的路径就行了,注意这里目前一次只能导入一个文件,所以需要两次操作,一次是导入.pb模型,一次是导入转换的配置文件,暂不能导入文件夹哦。
接下来选中文件,导入就行了:
再来一次,选资额.cfg配置文件哦:
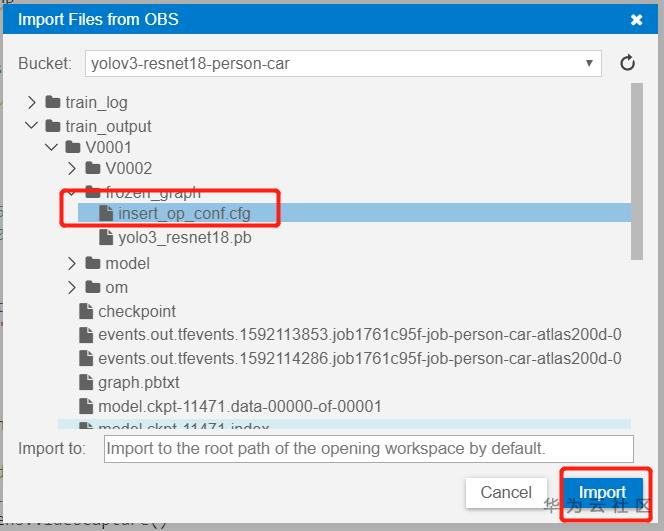
太棒了,你已经成功了一大半了哦,我们能在左侧目录下看到导入的文件了,默认是导入到根目录哦:
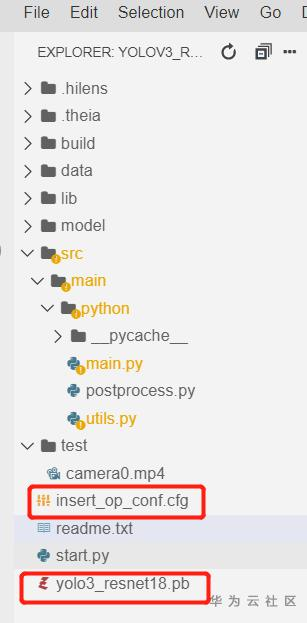
下面进行模型转换了,如果遇到什么问题,建议参考文档,不行的话,到论坛提问就好。
文档链接:https://support.huaweicloud.com/usermanual-hilens/hilens_02_0098.html
论坛链接:https://bbs.huaweicloud.com/forum/forum-771-1.html
基本转换操作在文档中做了详细的介绍,可以看出来工作人员还是很用心的哈:
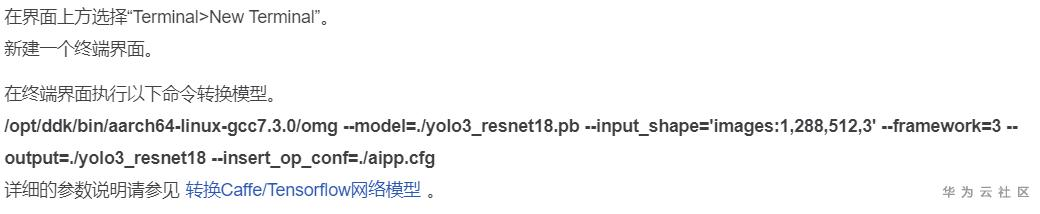
就是先在上面菜单栏开个终端,这个使用linux系统或者熟悉ModelArts的NoteBook的用户都应该比较熟悉了吧。之后用命令行转换模型。
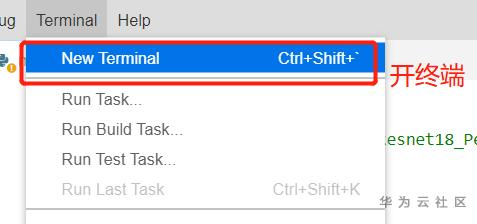
在界面最先面的终端输入如下命令即可:
/opt/ddk/bin/aarch64-linux-gcc7.3.0/omg --model=./yolo3_resnet18.pb --input_shape='images:1,352,640,3' --framework=3 --output=./yolo3_resnet18 --insert_op_conf=./insert_op_conf.cfg

如果你希望深入了解模型转换的设置,可以参考:
https://www.huaweicloud.com/ascend/doc/Atlas200DK/1.31.0.0(beta)/zh/zh-cn_topic_0211633857.html
因为模板默认从左侧目录文件夹model中调用模型(这一点,在代码中模型路径部分有写,而文件夹中的face_detection_demo.om是选择人脸检测模板自带的模型,关于模板问题,后面会讲的,可以自行删除哦),所以我们需要将生成的.om模型复制粘贴到该文件夹中,很简单的,直接选中.om模型,直接像在自己电脑上那样 在键盘使用快捷键Ctrl + C(表示复制选中文件), 之后选中model文件夹,使用Ctrl + V (表示粘贴)就行了,不得不说这个设计蛮人性化的哦,用户学习成本很低。
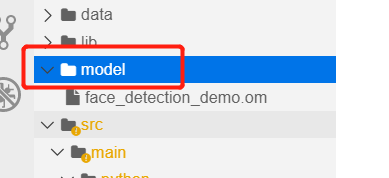
最终,我们得到这样界面,就行了:
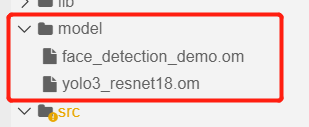
如果你不想自己训练,只是测试一下,这里提供了转换完成的.om模型,下载后,上传到HiLens Studio的model文件夹下即可使用:
链接:https://pan.baidu.com/s/1GT1BIvkQIDNCMP-YoVAssA
提取码:c4d3
4. 编辑代码
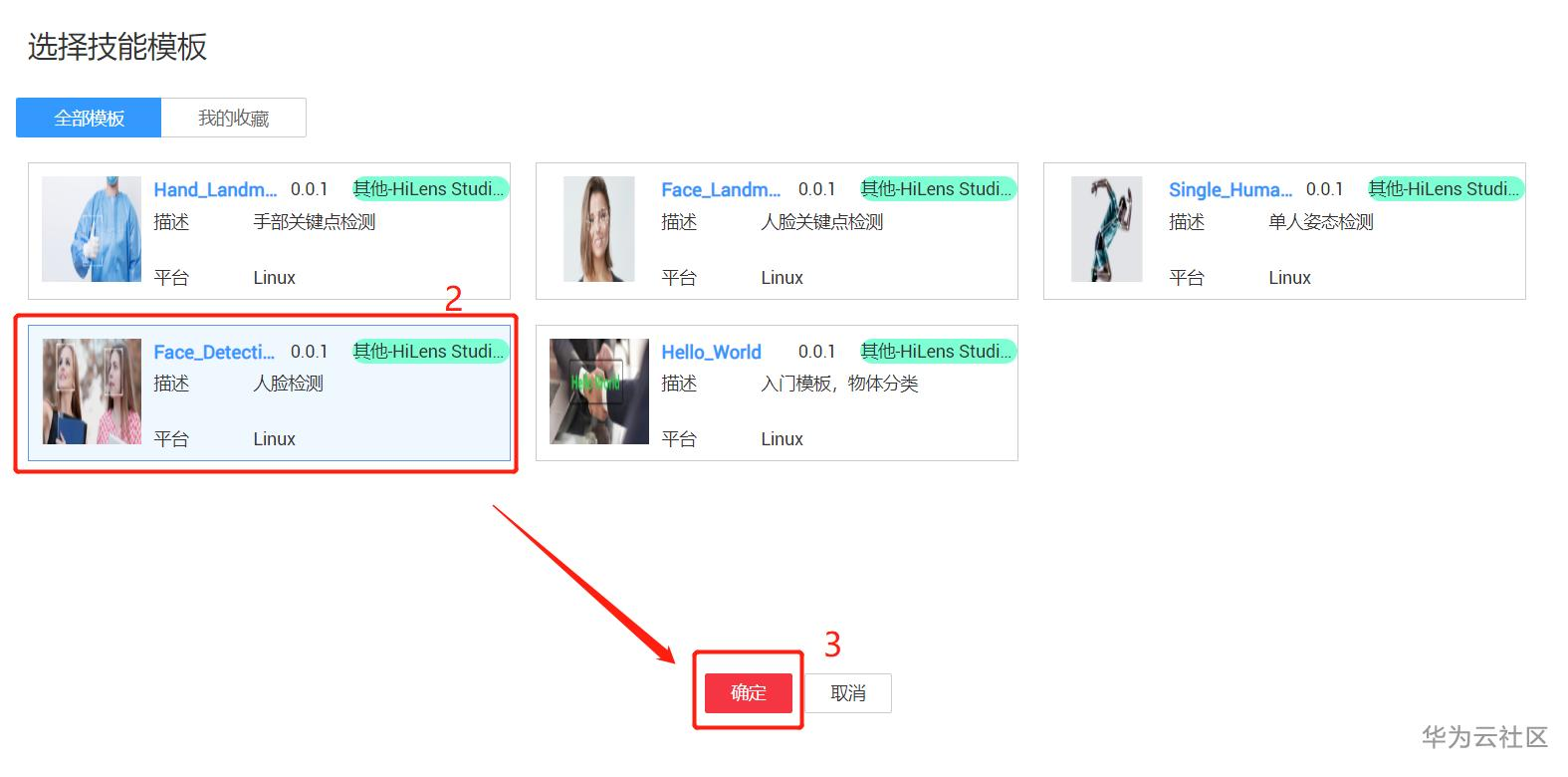
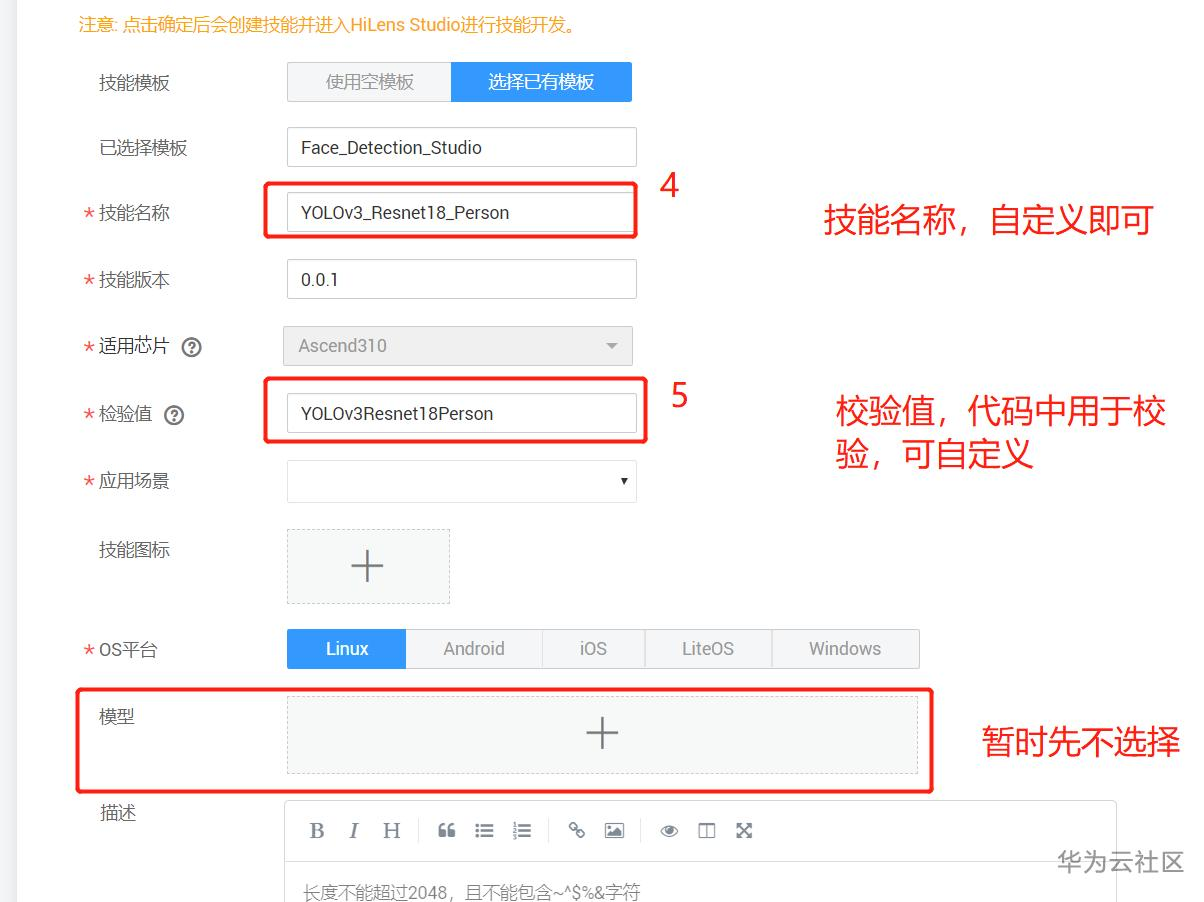
因为使用的是HiLens Studio,请再次确认已申请公测,并通过哦。相关编辑代码部分,比较简单。和大多数IDE类似,首先要创建工程,这里提供了很多模板,不过目前还不能创建空模板,所以自己选一个模板就行,我选的是人脸检测模板,选择后,点击确定就行了哦。之后的简单项目名称之类的,可参照下图哦。

创建之后,就能进入HiLens Studio类似于IDE的界面了,有点像PyCharm,感觉很不错,,可以切换主题哦,支持暗夜黑风格,这个切换就留给你自己去找找吧,不过都是英文界面哦。进入这里,大体可以看到这些东西,主要介绍了这里会用到的部分:
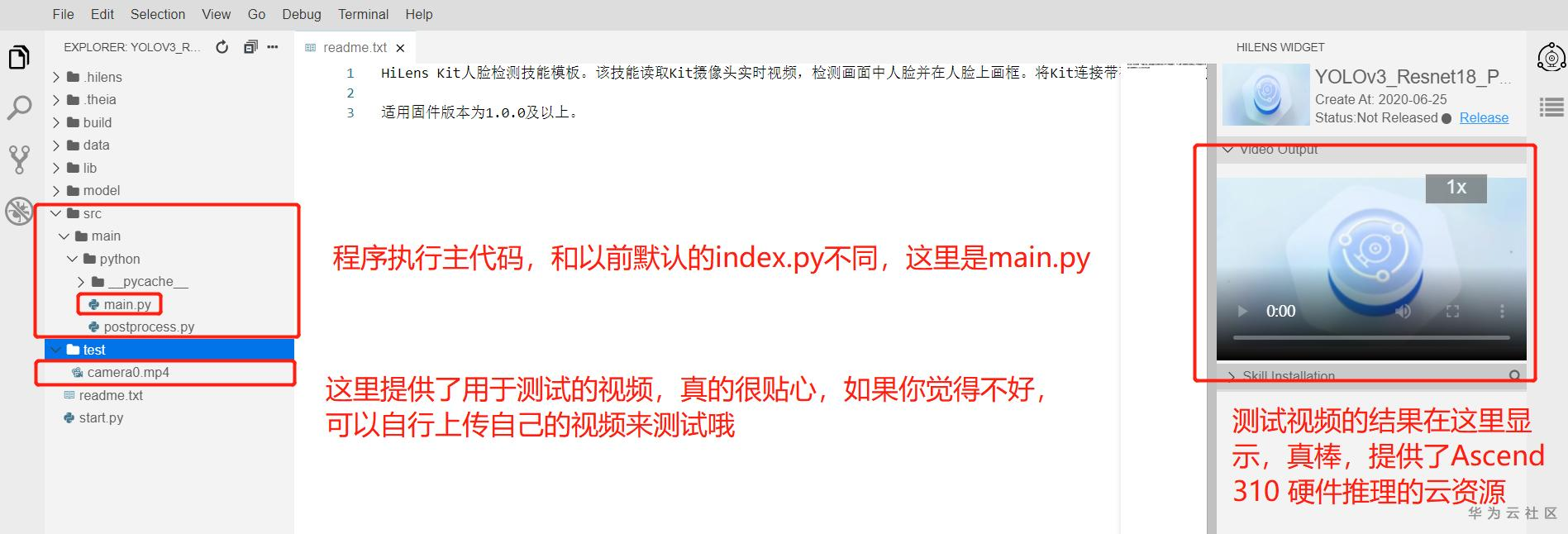
好了,这里我们首先要修改主程序main.py,为了代码的简介和模块化,将预处理和推理结果解析部分单独写为一个utils.py文件,方便理解程序运行架构,这里没什么具体要介绍的,直接上代码吧,如果有问题的话,可以在下面评论提问哦。
main.py主代码
# -*- coding: utf-8 -*- # !/usr/bin/python3 # SkillFramework 1.0.0 YOLOv3_Resnet18_Person import cv2 import numpy as np import os import hilens # 这个postprocess没用哈 from postprocess import im_detect_nms import utils # 网络输入尺寸 input_height = 352 input_width = 640 def main(work_path): hilens.init("YOLOv3Resnet18Person") # 参数要与创建技能时填写的检验值保持一致! # 模型路径 model_path = os.path.join(work_path, 'model/yolo3_resnet18.om') model = hilens.Model(model_path) # hilens studio中VideoCapture如果不填写参数,则默认读取test/camera0.mp4文件, # 在hilens kit中不填写参数则读取本地摄像头 camera = hilens.VideoCapture() display_hdmi = hilens.Display(hilens.HDMI) # 图像通过hdmi输出到屏幕 while True: try: # 1. 读取摄像头输入(yuv nv21) input_nv21 = camera.read() # 2. 转为RGB格式 input_rgb = cv2.cvtColor(input_nv21, cv2.COLOR_YUV2RGB_NV21) # src_image_height = input_bgr.shape[0] # src_image_width = input_bgr.shape[1] img_preprocess, img_w, img_h = utils.preprocess(input_rgb) # 缩放为模型输入尺寸 # 3. 模型推理 output = model.infer([img_preprocess.flatten()]) # 4. 结果输出 bboxes = utils.get_result(output, img_w, img_h) # 获取检测结果 output_rgb = utils.draw_boxes(input_rgb, bboxes) # 在图像上画框 # 5. 输出图像,必须是yuv nv21形式 output_nv21 = hilens.cvt_color(output_rgb, hilens.RGB2YUV_NV21) display_hdmi.show(output_nv21) except Exception: break if __name__ == "__main__": main(os.getcwd())
这里还要创建一个前面提到的utils.py文件,很简单哦,来上图:
创建后,utils.py的代码如下,如果你想检测更多类别,比如同时检测任何车,可参考我在下面代码最后加的注释部分:
# -*- coding: utf-8 -*- # !/usr/bin/python3 # utils for mask detection import cv2 import math import numpy as np # 检测模型输入尺寸 net_h = 352 net_w = 640 # 检测模型的类别 class_names = ["person"] class_num = len(class_names) # 检测模型的anchors,用于解码出检测框 stride_list = [8, 16, 32] anchors_1 = np.array([[10,13], [16,30], [33,23]]) / stride_list[0] anchors_2 = np.array([[30,61], [62,45], [59,119]]) / stride_list[1] anchors_3 = np.array([[116,90], [156,198], [163,326]]) / stride_list[2] anchor_list = [anchors_1, anchors_2, anchors_3] # 检测框的输出阈值、NMS筛选阈值和人形/人脸区域匹配阈值 conf_threshold = 0.3 iou_threshold = 0.4 cover_threshold = 0.8 # 图片预处理:缩放到模型输入尺寸 def preprocess(img_data): h, w, c = img_data.shape new_image = cv2.resize(img_data, (net_w, net_h)) return new_image, w, h def overlap(x1, x2, x3, x4): left = max(x1, x3) right = min(x2, x4) return right - left # 计算两个矩形框的IOU def cal_iou(box1, box2): w = overlap(box1[0], box1[2], box2[0], box2[2]) h = overlap(box1[1], box1[3], box2[1], box2[3]) if w <= 0 or h <= 0: return 0 inter_area = w * h union_area = (box1[2] - box1[0]) * (box1[3] - box1[1]) + (box2[2] - box2[0]) * (box2[3] - box2[1]) - inter_area return inter_area * 1.0 / union_area # 计算两个矩形框的IOU与box2区域的比值 def cover_ratio(box1, box2): w = overlap(box1[0], box1[2], box2[0], box2[2]) h = overlap(box1[1], box1[3], box2[1], box2[3]) if w <= 0 or h <= 0: return 0 inter_area = w * h small_area = (box2[2] - box2[0]) * (box2[3] - box2[1]) return inter_area * 1.0 / small_area # 使用NMS筛选检测框 def apply_nms(all_boxes, thres): res = [] for cls in range(class_num): cls_bboxes = all_boxes[cls] sorted_boxes = sorted(cls_bboxes, key=lambda d: d[5])[::-1] p = dict() for i in range(len(sorted_boxes)): if i in p: continue truth = sorted_boxes[i] for j in range(i+1, len(sorted_boxes)): if j in p: continue box = sorted_boxes[j] iou = cal_iou(box, truth) if iou >= thres: p[j] = 1 for i in range(len(sorted_boxes)): if i not in p: res.append(sorted_boxes[i]) return res # 从模型输出的特征矩阵中解码出检测框的位置、类别、置信度等信息 def decode_bbox(conv_output, anchors, img_w, img_h): def _sigmoid(x): s = 1 / (1 + np.exp(-x)) return s _, h, w = conv_output.shape pred = conv_output.transpose((1,2,0)).reshape((h * w, 3, 5+class_num)) pred[..., 4:] = _sigmoid(pred[..., 4:]) pred[..., 0] = (_sigmoid(pred[..., 0]) + np.tile(range(w), (3, h)).transpose((1,0))) / w pred[..., 1] = (_sigmoid(pred[..., 1]) + np.tile(np.repeat(range(h), w), (3, 1)).transpose((1,0))) / h pred[..., 2] = np.exp(pred[..., 2]) * anchors[:, 0:1].transpose((1,0)) / w pred[..., 3] = np.exp(pred[..., 3]) * anchors[:, 1:2].transpose((1,0)) / h bbox = np.zeros((h * w, 3, 4)) bbox[..., 0] = np.maximum((pred[..., 0] - pred[..., 2] / 2.0) * img_w, 0) # x_min bbox[..., 1] = np.maximum((pred[..., 1] - pred[..., 3] / 2.0) * img_h, 0) # y_min bbox[..., 2] = np.minimum((pred[..., 0] + pred[..., 2] / 2.0) * img_w, img_w) # x_max bbox[..., 3] = np.minimum((pred[..., 1] + pred[..., 3] / 2.0) * img_h, img_h) # y_max pred[..., :4] = bbox pred = pred.reshape((-1, 5+class_num)) pred[:, 4] = pred[:, 4] * pred[:, 5:].max(1) # 类别 pred = pred[pred[:, 4] >= conf_threshold] pred[:, 5] = np.argmax(pred[:, 5:], axis=-1) # 置信度 all_boxes = [[] for ix in range(class_num)] for ix in range(pred.shape[0]): box = [int(pred[ix, iy]) for iy in range(4)] box.append(int(pred[ix, 5])) box.append(pred[ix, 4]) all_boxes[box[4]-1].append(box) return all_boxes # 从模型输出中得到检测框 def get_result(model_outputs, img_w, img_h): num_channel = 3 * (class_num + 5) all_boxes = [[] for ix in range(class_num)] for ix in range(3): pred = model_outputs[2-ix].reshape((num_channel, net_h // stride_list[ix], net_w // stride_list[ix])) anchors = anchor_list[ix] boxes = decode_bbox(pred, anchors, img_w, img_h) all_boxes = [all_boxes[iy] + boxes[iy] for iy in range(class_num)] res = apply_nms(all_boxes, iou_threshold) return res # 在图中画出检测框,输出类别信息,注意这里对person类别绘制矩形框 def draw_boxes(img_data, bboxes): thickness = 2 font_scale = 1 text_font = cv2.FONT_HERSHEY_DUPLEX for bbox in bboxes: label = int(bbox[4]) x_min = int(bbox[0]) y_min = int(bbox[1]) x_max = int(bbox[2]) y_max = int(bbox[3]) score = bbox[5] # 1: person 蓝色 if label == 0: # print(x_min, y_min, x_max, y_max) cv2.rectangle(img_data, (x_min, y_min), (x_max, y_max), (0, 0, 255), thickness) # cv2.putText(img_data, 'person', (x_min, y_min - 20), text_font, font_scale, (255, 255, 0), thickness) # cv2.putText(img_data, score, (50, 50), text_font, font_scale, (255, 255, 0), thickness) # 2: ''' if label == 1: # print(x_min, y_min, x_max, y_max) cv2.rectangle(img_data, (x_min, y_min), (x_max, y_max), (255, 0, 0), thickness) # cv2.putText(img_data, 'person', (x_min, y_min - 20), text_font, font_scale, (255, 255, 0), thickness) # cv2.putText(img_data, score, (50, 50), text_font, font_scale, (255, 255, 0), thickness) else: # print("[INFO] Hi, find others.") pass ''' return img_data
好,至此,基本代码部分就完成了。
下面可以检测测试了,这里提供一段来自MOT多目标挑战赛的视频片段供测试,需要自己上传到HiLens Studio上,十分简单,和本地电脑操作没什么区别,邮件单机左侧空白目录部分,弹出菜单,选择上传即可,对开发者十分友好啊:
视频分辨率1920 * 1080,约136M,不过很快就能上传完成,华为云的带宽和上传速度还是很不错的,不过这也与你自己的网络环境有关的。
视频下载链接为:
链接:https://pan.baidu.com/s/1RWUGpYvAQuP6icY0iDkgEw
提取码:iwpo
注意:需要将视频改名为camera0.mp4(选中视频,邮件弹出菜单,选择Rename即可),之后到左侧目录test文件夹下,将该文件夹下的camera0.mp4视频删除,再将刚才改名为camera0.mp4的视频(就是我们上传的视频)拷贝到test文件夹下。
最终我们得到如下的几个重要文件:
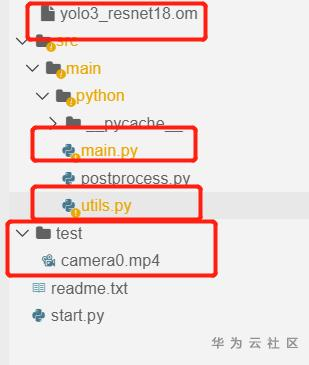
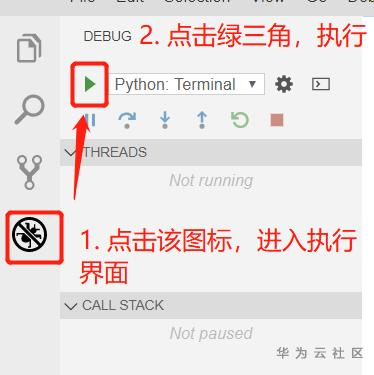
接下来,就可以执行程序测试了:
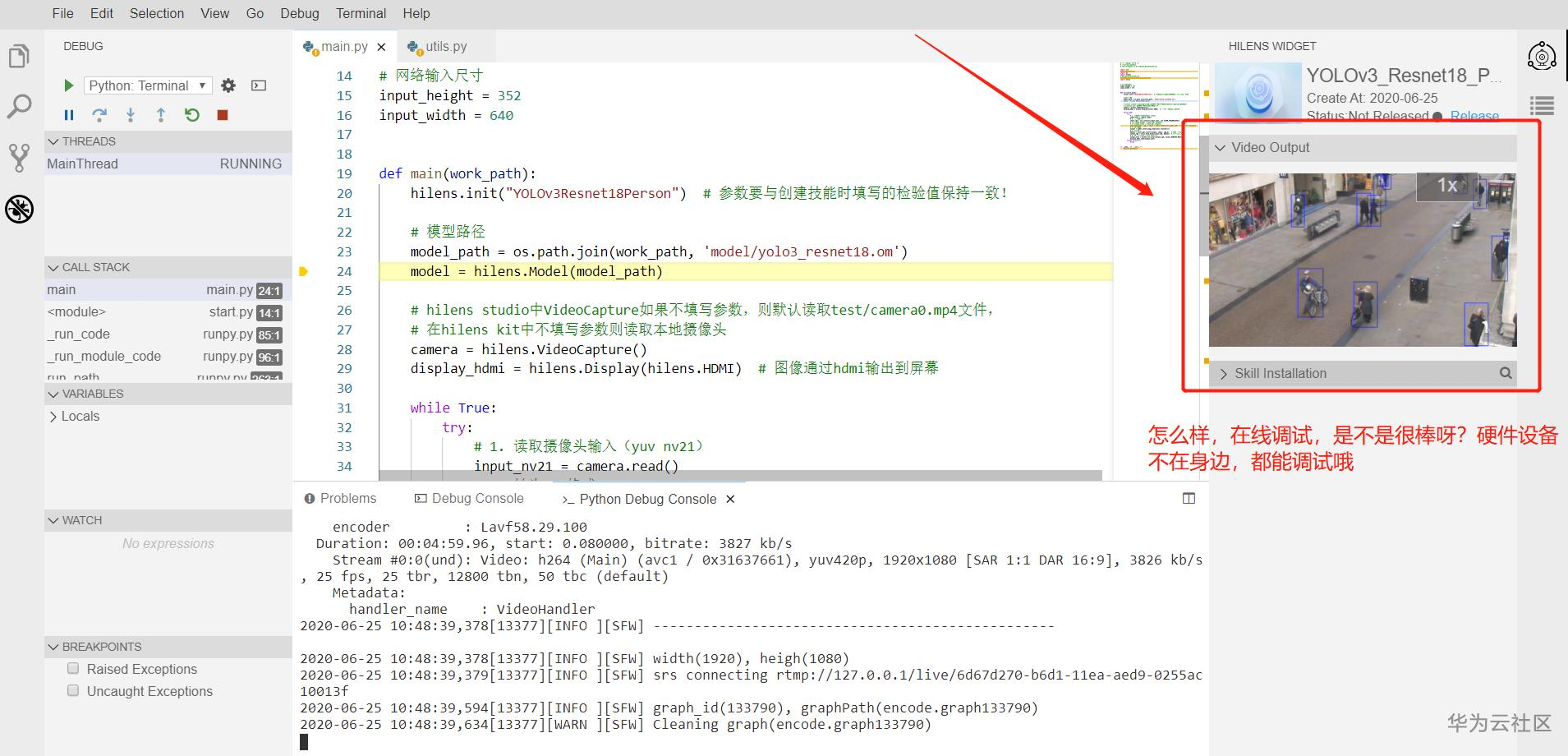
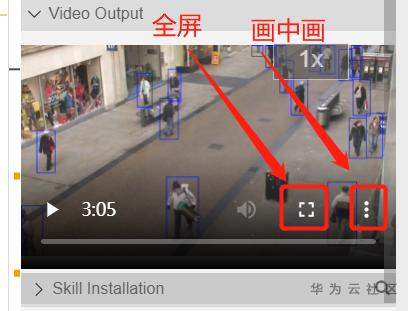
之后,在右上角部分的视频框中就能看到运行结果了,如果你觉得不方便,还可以全屏观看,甚至画中画模式观看都可以呀,在画中画模式下,你可以边做其他的事情,边小窗口观看视频,类似于手机端的分屏操作。
全屏模式效果展示:
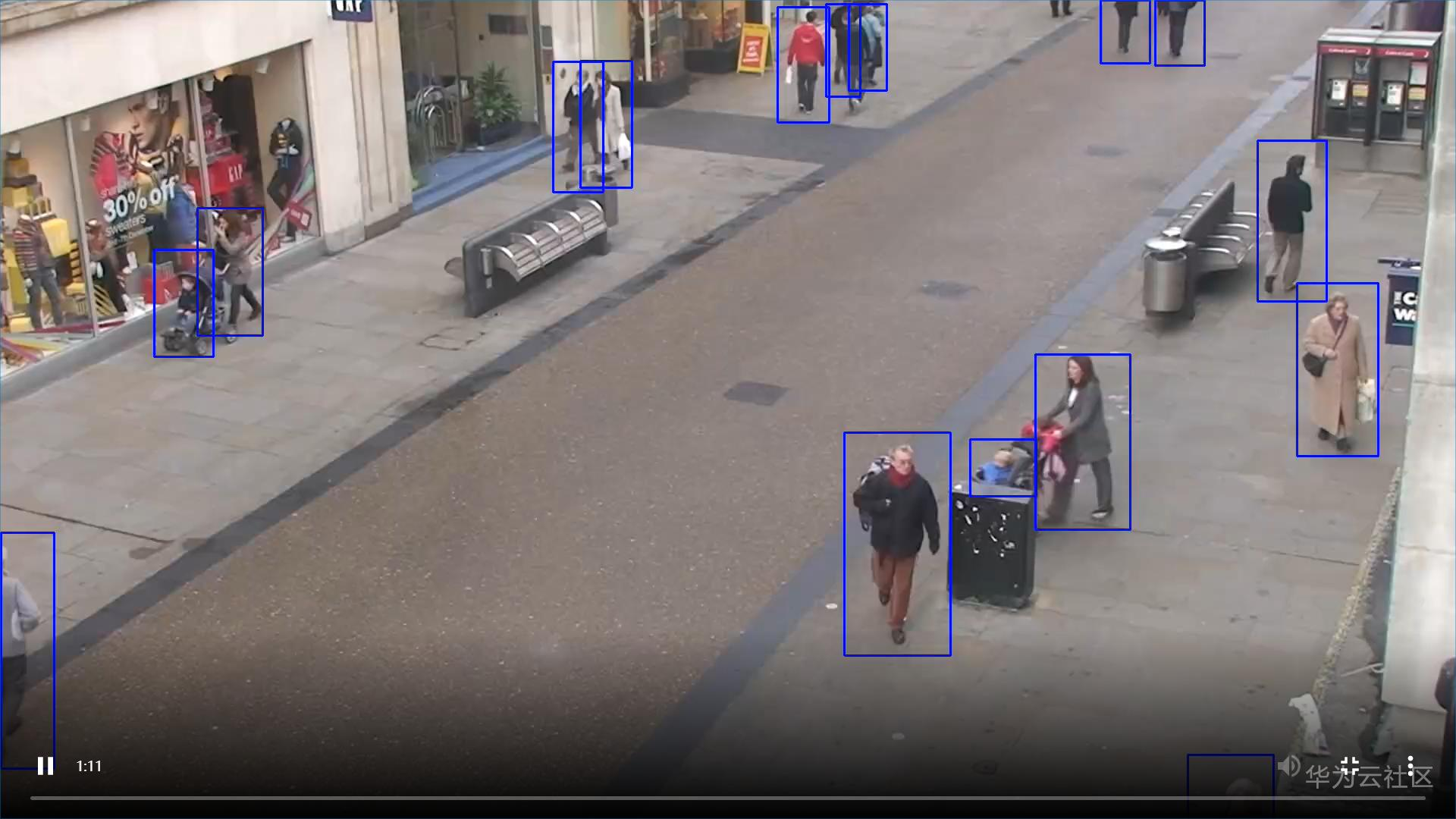
画中画模式效果展示(视频可任意拖拽位置哦):
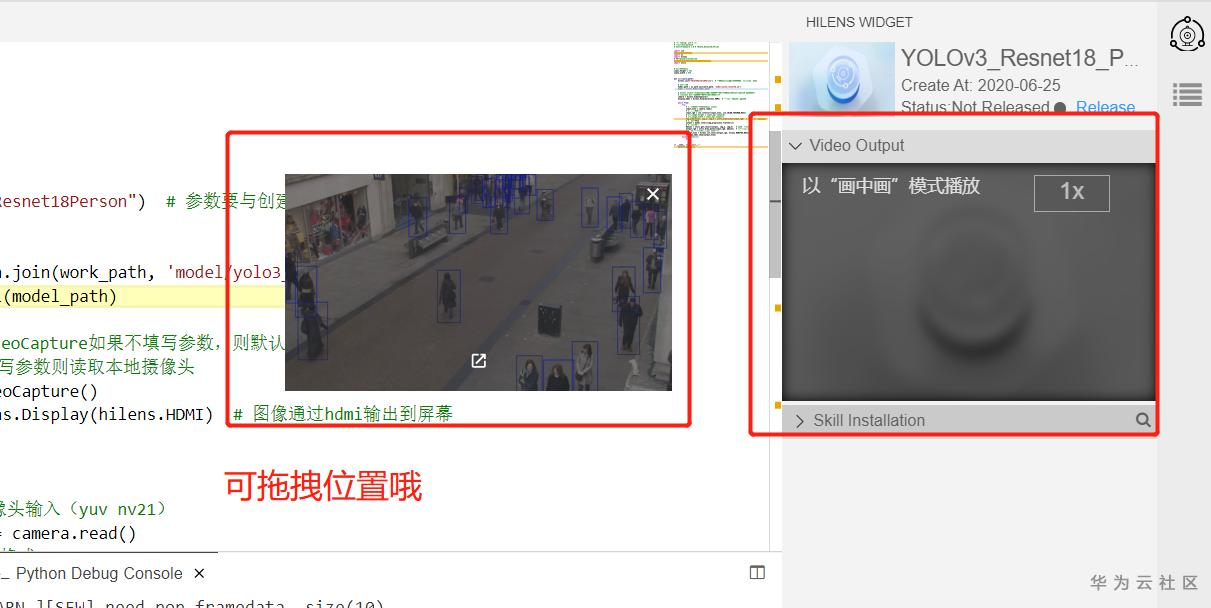
上面两种模式的操作十分简单,和在腾讯、爱奇艺、B站等视频网站操作类似:
最终效果如下面视频所示,这里非常抱歉,由于我是屏幕录制的,且没有切换到全屏模式,不太清晰,建议大家自己试试,在自己的HiLens Studio里看会很清晰的,同时,附上B站视频链接,以防下面视频失效,无法观看:https://www.bilibili.com/video/BV1E5411Y73r/
如果你想安装到HiLens Kit上,和原先的操作台类似,在上面视频播放界面下面就有选线的,大体如下,仍然是先安装,后启动就行了:
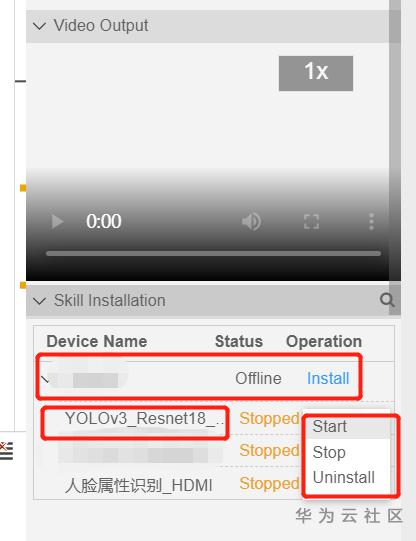
至此,大功告成,总的来说,HiLens Stuio如开篇所说的,集大成之作,非常好用,这类云端IDE十分新颖,创新型强,极大降低了对开发者本地配置的要求,甚至几十没有硬件设备,也可以调试程序,是边缘计算开发者的福音呀,这是从HiLens,到华为云,再到华为公司,很多人长期积累努力的结果,很不错,这也算华为全栈全场景AI解决方案的一部分吧,期待更加强大,加油。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号