8种ETL算法汇总大全!看完你就全明白了
摘要:ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中。目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
1 ETL算法概览
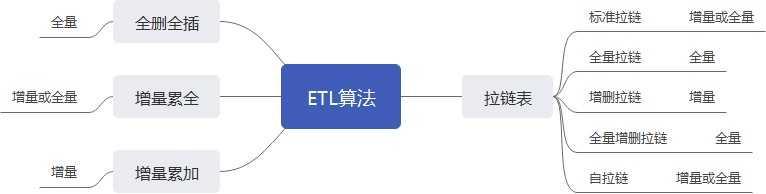
> 算法应用场景概览
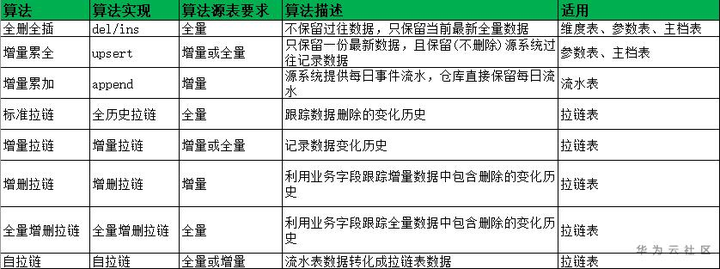
以上共计累积了8种ETL算法,其中主要分成4大类,增量累加、拉链算法是更符合数据仓库历史数据追踪的算法,但现实中基于业务及性能考虑,往往存在全删全插、增量累全算法的数据表应用。
2 全删全插模型
即Delete/Insert实现逻辑;
> 应用场景
主要应用在维表、参数表、主档表加载上,即适合源表是全量数据表,该数据表业务逻辑只需保存当前最新全量数据,不需跟踪过往历史信息。
> 算法实现逻辑
1.清空目标表;
2.源表全量插入;
> ETL代码原型 -- 1. 清理目标表 TRUNCATE TABLE <目标表>; -- 2. 全量插入 INSERT INTO <目标表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <关联数据> WHERE ***;
3 增量累全模型
即Upsert实现逻辑;
> 应用场景
主要应用在参数表、主档表加载上,即源表可以是增量或全量数据表,目标表始终最新最全记录。
> 算法实现逻辑
1.利用PK主键比对;
2.目标表和源表PK一致的变化记录,更新目标表;
3.源表存在但目标表不存在,直接插入;
> ETL代码原型
-- 1. 生成加工源表 Create temp Table <临时表> ***; INSERT INTO <临时表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <关联数据> WHERE *** ; -- 2. 可利用Merge Into实现累全能力,当前也可以采用分步Delete/Insert或Update/Insert操作 Merge INTO <目标表> As T1 (字段***) Using <临时表> as S1 on (***PK***) when Matched then update set Colx = S1.Colx *** when Not Matched then INSERT (字段***) values (字段*** ) ;
4 增量累加模型
即Append实现逻辑;
> 应用场景
主要应用在流水表加载上,即每日产生的流水、事件数据,追加到目标表中保留全历史数据。流水表、快照表、统计分析表等均是通过该逻辑实现。
> 算法实现逻辑
1.源表直接插入目标表;
> ETL代码原型
-- 1.插入目标表 INSERT INTO <目标表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <关联数据> WHERE ***;
5 全历史拉链模型
> 拉链表背景知识
概念
拉链表是一张至少存在PK字段、跟踪变化的字段、开链日期、闭链日期组成的数据仓库ETL数据表;
益处
根据开链、闭链日期可以快速提取对应日期有效数据;
对于跟踪源系统非事件流水类表数据,拉链算法发挥越大作用,源业务系统通常每日变化数据有限,通过拉链加工可以大大降低每日打快照带来的空间开销,且不损失数据变化历史;
示例,提取指定日期有效数据
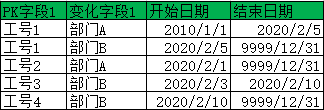
提取2020年2月5日当日有效数据
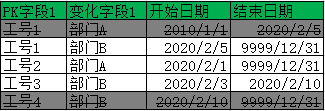
Select * From <目标表> Where 开始日期<=date'2020-02-05' And 结束日期 >date'2020-02-05';
最终提取到数据:
> 应用场景
全历史拉链,跟踪源表全量变化历史,若源表记录不存在,则说明数据闭链;根据PK新拉一条有效记录。
> 算法实现逻辑
1.提取当前有效记录;
2.提取当日源系统最新数据;
3.根据PK字段比对当前有效记录与最新源表,更新目标表当前有效记录,进行闭链操作;
4.根据全字段比对最新源表与当前有效记录,插入目标表;
> ETL代码原型
-- 1. 提取当前有效记录 Insert into <临时表-开链-pre> (不含开闭链字段***) Select 不含开闭链字段*** From <目标表> Where 结束日期 =date'<最大日期>'; ; -- 2. 提取当日源系统最新数据 <源表临时表-cur> -- 3 今天全部开链的数据,即包含今天全新插入、数据发生变化的记录 Insert Into <临时表-增量-ins> Select 不含开闭链字段*** From <源表临时表-cur> where (不含开闭链字段***) not in (Select 不含开闭链字段*** From <临时表-开链-pre> ); -- 4 今天需要闭链的数据,即今天发生变化的记录 Insert into <临时表-增量-upd> Select 不含开闭链字段***,开始时间 From <临时表-开链-pre> where (不含开闭链字段***) not in (Select 不含开闭链字段*** From <临时表-开链-cur> ); -- 5 更新闭链数据,即历史记录闭链(删除-插入替代更新) DELETE FROM <目标表> WHERE (PK***) IN (Select PK*** From <临时表-增量-upd>) AND 结束日期=date'<最大日期>'; INSERT INTO <目标表> (不含开闭链字段***,开始时间,结束日期) Select 不含开闭链字段***,开始时间,date'<数据日期>' From <临时表-增量-upd>; -- 6 插入开链数据,即当日新增记录 INSERT INTO <目标表> . (不含开闭链字段***,开始时间,结束日期) Select 不含开闭链字段***,date'<数据日期>',date'<最大日期>' From <临时表-增量-ins>;
6 增量拉链模型
> 应用场景
增量拉链,目的是追踪数据增量变化历史,根据PK比对新拉一条开链数据;
> 算法实现逻辑
1.提取上日开链数据;
2.PK相同变化记录,关闭旧记录链,开启新记录链;
3.PK不同,源表存在,新增开链记录
> ETL代码原型
-- 1. 提取当前有效记录 Insert into <临时表-开链-pre> (不含开闭链字段***) Select 不含开闭链字段*** From <目标表> Where 结束日期 =date'<最大日期>'; -- 2. 提取当日源系统增量记录 <源表临时表-cur> -- 3. 提取当日源系统新增记录 Insert into <临时表-增量-ins> Select 不含开闭链字段*** From <临时表-开链-cur> where (***PK***) not in (select ***PK*** from <临时表-开链-pre>); -- 4. 提取当日源系统历史变化记录 Insert into <临时表-增量-upd> Select 不含开闭链字段*** From <临时表-开链-cur> inner join <临时表-开链-pre> on (***PK 等值***) where (***变化字段 非等值***); -- 5. 更新历史变化记录,关闭历史旧链,开启新链 update <目标表> AS T1 SET <***变化字段 S1赋值***>,结束日期 = date'<数据日期>' FROM <临时表-增量-upd> AS S1 WHERE ( <***PK 等值***> ) AND T1.结束日期 =date'<最大日期>' ; INSERT INTO <目标表> (不含开闭链字段***,开始时间,结束日期) SELECT 不含开闭链字段***,date'<数据日期>',date'<最大日期>' FROM <临时表-增量-upd>; -- 6. 插入全新开链数据 INSERT INTO <目标表> (不含开闭链字段***,开始时间,结束日期) SELECT 不含开闭链字段***,date'<数据日期>',date'<最大日期>' FROM <临时表-增量-ins>;
7 增删拉链模型
> 应用场景
主要是利用业务字段跟踪增量数据中包含删除的变化历史。
> 算法实现逻辑
1.提取上日开链数据;
2.提取源表非删除记录;
3.PK相同变化记录,关闭旧记录链,开启新记录链;
4.PK比对,源表存在,新增开链记录;
5.提取源表删除记录;
6.PK比对,旧开链记录存在,关闭旧记录链;
> ETL代码原型
-- 1. 清理目标表《待续...》 TRUNCATE TABLE <目标表>; -- 2. 全量插入 INSERT INTO <目标表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <关联数据> WHERE ***;
8 全量增删拉链模型
> 应用场景
主要是利用业务字段跟踪全量数据中包含删除的变化历史。
> 算法实现逻辑
1.提取上日开链数据;
2.提取源表非删除记录;
3.PK相同变化记录,关闭旧记录链,开启新记录链;
4.PK比对,源表存在,新增开链记录;
5.提取源表删除记录;
6.PK比对,旧开链记录存在,关闭旧记录链;
7.PK比对,提取旧开链存在但源表不存在记录,关闭旧记录链;
> ETL代码原型
-- 1. 清理目标表,《待续...》 TRUNCATE TABLE <目标表>; -- 2. 全量插入 INSERT INTO <目标表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <关联数据> WHERE ***;
9 自拉链模型
> 应用场景
主要将流水表数据转化成拉链表数据。
> 算法实现逻辑
借助源表业务日期字段,和目标表开链、闭链日期比对,首尾相接,拉出全历史拉链;
> ETL代码原型
-- 1. 清理目标表,《待续...》 TRUNCATE TABLE <目标表>; -- 2. 全量插入 INSERT INTO <目标表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <关联数据> WHERE ***;
10 其它说明
1.根据数据仓库最佳实践,所有数据表通常还会包含一些控制字段,即插入日期、更新日期、更新源头字段,这样对于数据变化敏感的数据仓库,可以进一步追踪数据变化历史;
2.ETL算法本身是为了更好服务于数据加工过程,实际业务实现过程中,并不局限于传统算法,即涉及到更多适应业务的自定义的ETL算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号