五个Taurus垃圾回收compactor优化方案,减少系统资源占用
简介
TaurusDB是一种基于MySQL的计算与存储分离架构的云原生数据库,一个集群中包含多个存储几点,每个存储节点包含多块磁盘,每块磁盘对应一个或者多个slicestore的内存逻辑结构来管理. 在taurus的slicestore中将数据划为多个slice进行管理,每个slice的大小是10G,Taurus架构图如下:
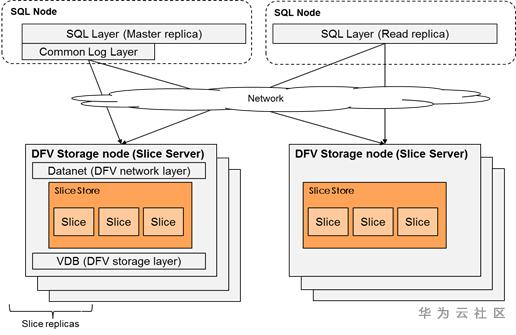
TauruDB的存储层支持append-only写和随机读,最小数据存储逻辑单元为plog,每个slice中包含多个plog,默认每个plog的大小为64M。slice中的plog主要用来存放page。Plog中存放中不同版本的page,有些老page已经过期,需要删除;有些page是新page,需要被保留下来。
Compator主要用来清理plog中过期的page,把一个plog上所有没有过期的page搬移到一个新plog,老的plog删除掉。
Compactor的任务需要频繁访问内存中索引结构和读写plog中的page页,这两部分都属于整个系统中关键资源,锁竞争的压力比较大,会直接影响性能,所以compactor的优化方案主要围绕减少内存访问和磁盘IO,需要考虑以下几个点:
A、 选取的清理的plog集最优问题,每次回收需要搬运有效page,搬运的有效page数越少,磁盘IO就越小。如何每次调度都选取到垃圾量最大的一批plog;
B、 垃圾量是否分布均匀,如何让垃圾集中到一起,回收垃圾集中的plog,提高回收效率;
C、 回收周期是固定的,怎么样保证在每个周期内,都能取到最优plog集。
当前,我们提出了几个可以有效减少page搬运数,从而达到减少IO目的的方案。
关键点1:全局调度
全局调度的方案增大plog垃圾量的排序范围,从slice的范围增大到slicestore的范围。因为考虑到后面需要针对单个磁盘进行“加速回收”,所以不扩大到一个存储节点的全局范围。
全局调度方案按照slicestore来选取回收plog,先遍历所有的slicestore,然后在slicestore内部进行垃圾量排序,选取最多的若干个plog进行回收;
优点:有效避免一个slicestore中由于垃圾分布不均匀引起的plog的无效搬运,减少对plog的读写产生的IO;
缺点:排序范围增大后,排序算法会增加CPU的消耗;
关键点2:排序算法优化
原始方案中在slice内部对plog按照垃圾量排序采用C++标准库排序(std::sort),该算法内部基于快速排序、插入排序和堆排序实现。原始方案中每个slice中最多存有160个plog,小数据量的排序或许效率影响不大,但是一个slicestore中存储成百上千的slice,排序算法的效率问题就值得关注。
Taurus设计了一种topN算法,能够提升该场景下的效率。假设需要在n个元素中选取m个最大的元素,两种算法的时间复杂度和空间复杂度:
C++标准库排序时间复杂度为O(nlogn),空间复杂度为O(nlogn);
topN算法排序时间复杂度为O(nlogm),空间复杂度为O(1);
Compactor应用场景中,n和m相差几个数量级,topN算法在时间和空间上都更具优势。
优点:减少时间复杂度和空间复杂度;
关键点3:调度数优化
公共线程池分配给compactor的线程数是固定的,每个周期调度器生成一次任务。原始方案中compactor的每次生成的任务数由slice个数决定,会导致任务队列中的任务数过多或者过少。过多的话会失去时效性,也就是说plog的垃圾量会随着时间改变,如果在队列等待执行的时间太长,可能就不是当前最高垃圾量的plog,同时一次挑选的plog个数太多,会增加算法的时间和空间复杂度;过少的话,compactor线程没有跑满,会导致垃圾回收速度降低。
调度数优化也是基于全局调度优化,调度策略只需要保证在一个调度周期内,任务队列中任务数刚好满足compactor线程执行。假设有8个slicestore,分配了24个执行线程,每个线程每个调度周期完成一个plog的回收,则每个调度周期每个slicestore只需要生成3个任务。
调度数优化即记录公共线程池中正在执行和准备执行的任务数,跟据记录决定本轮调度生成多少个回收任务,从而保证执行线程刚好够用,且不多不少。
优点:保证垃圾回收速度,最优回收的plog集,有效的减少page的搬运量。
关键点4:冷热分区优化
在数据库系统中,数据的更新并不是相同频率,一些数据页更新或者写入会更加频繁(例如系统页),这部分页面被称作热页,另外一些更新不频繁的称作冷页。如果把冷页和热页混合放到一起,就会导致更高的写放大。举个简单的例子,假设有100个热页和10个冷页,冷页基本不更新但是每次垃圾回收,都需要重复把冷页搬运一次。如果把冷页单独写入一个plog,那么在垃圾回收阶段,就可以减少重复搬运这部分冷页,达到减少IO放大的效果。
优点:提高垃圾回收的效率和速度。
缺点:需要额外的内存记录热度信息。
关键点5:磁盘逃生优化
为了后台线程比如备份、快照、垃圾回收、页面回放等线程有足够的磁盘空间运行,在磁盘容量使用到达一定阈值,会置Full标志位,同时停止前台IO。在极端情况下,磁盘使用到阈值前台IO会出现断崖式下跌为零:
为了避免在磁盘容量达到一定阈值之后前台IO完全停止,在磁盘使用率未达到阈值时,就应该有相应的处理机制。比如说在磁盘使用率未达阈值时,增加如下处理:
A、 降低前台IO,减少磁盘的压力;
B、 加速垃圾回收,也就是TaurusDB中的compactor机制;
A点不涉及compactor的功能,所以本文先不涉及,下面主要介绍两种加速机制:
1.修改写IO优先级
Compactor作为后台线程,考虑到整个系统的效率,正常运行时plog写IO优先级默认为low。在加速回收阶段,plog的IO需要修改为high。
2.提高执行速度
前文可知,公共线程池为compactor分配固定数目执行线程,而且运行过程中只支持扩容不支持恢复。如果压缩其他后台任务的执行线程,对整个系统的影响太大,量也不易控制。所以不考虑。
考虑到过程中不能扩容,那就初始化就扩容,通过控制调度任务数控制任务执行速度。例如,假设compactor的运行线程在正常场景下为4个,加速状态下需要增加到8个。可以在公共线程池中先分配8个线程,在正常场景下,控制任务队列为4个,另外4个线程处于wait状态,只会占用文件句柄,并不影响CPU。而在加速状态下,控制任务队列中的任务数为8,就可以实现上述的加速逻辑。
所以,提升写IO的优先级能够加速page的搬运,提升垃圾回收速度。通过控制调度任务数控制任务执行速度却很难控制很精准,上下会有一定的小波动。
最后
以上提到的垃圾回收compactor优化方案中,磁盘逃生优化能够处理磁盘容量紧急情况。目前根据本地测试,在500G的小数据集情况下,IO放大能减少到原来的1/6。系统资源占用减少到原来的1/3。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号