
数据湖&数据仓库,别再傻傻分不清了
摘要:什么是数据湖?它有什么作用?今天将由华为云技术专家从理论出发,将问题抽丝剥茧,从技术维度娓娓道来。
什么是数据湖
如果需要给数据湖下一个定义,可以定义为这样:数据湖是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。
数据湖从企业的多个数据源获取原始数据,并且针对不同的目的,同一份原始数据还可能有多种满足特定内部模型格式的数据副本。因此,数据湖中被处理的数据可能是任意类型的信息,从结构化数据到完全非结构化数据。
企业对数据湖寄予厚望,希望它能帮助用户快速获取有用信息,并能将这些信息用于数据分析和机器学习算法,以获得与企业运行相关的洞察力。
数据湖与企业的关系
数据湖能给企业带来多种能力,例如,能实现数据的集中式管理,在此之上,企业能挖掘出很多之前所不具备的能力。
另外,数据湖结合先进的数据科学与机器学习技术,能帮助企业构建更多优化后的运营模型,也能为企业提供其他能力,如预测分析、推荐模型等,这些模型能刺激企业能力的后续增长。
企业数据中隐藏着多种能力,然而,在重要数据能够被具备商业数据洞察力的人使用之前,人们无法利用它们来改善企业的商业表现。
数据湖如何帮助企业
长期以来,企业一直试图找到一个统一的模型来表示企业中所有实体。这个任务有极大的挑战性,原因有很多,下面列举了其中的一部分:
1. 一个实体在企业中可能有多种表示形式,因此可能不存在某个完备的模型来统一表示实体。
2. 不同的企业应用程序可能会基于特定的商业目标来处理实体,这意味着处理实体时会采用或排斥某些企业流程。
3. 不同应用程序可能会对每个实体采用不同的访问模式及存储结构。
这些问题已困扰企业多年,并阻碍了业务处理、服务定义及术语命名等事务的标准化。
从数据湖的角度来看,我们正在以另外一种方式来看待这个问题。使用数据湖,隐式实现了一个较好的统一数据模型,而不用担心对业务程序产生实质性影响。这些业务程序则是解决具体业务问题的“专家”。数据湖基于从实体所有者相关的所有系统中捕获的全量数据来尽可能“丰满”地表示实体。
因为在实体表示方面更优且更完备,数据湖确实给企业数据处理与管理带来了巨大的帮助,使得企业具备更多关于企业增长方面的洞察力,帮助企业达成其商业目标。
数据湖的优点
企业会在其多个业务系统中产生海量数据,随着企业体量增大,企业也需要更智能地处理这些横跨多个系统的数据。
一种最基本的策略是采用一个单独的领域模型,它能精准地描述数据并能代表对总体业务最有价值的那部分数据。这些数据指的是前面提到的企业数据。
对企业数据进行了良好定义的企业当然也有一些管理数据的方法,因此企业数据定义的更改能保持一致性,企业内部也很清楚系统是如何共享这些信息的。
在这种案例中,系统被分为数据拥有者(data owner)及数据消费者(data consumer)。对于企业数据来说,需要有对应的拥有者,拥有者定义了数据如何被其他消费系统获取,消费系统扮演着消费者的角色。
一旦企业有了对数据和系统的明晰定义,就可以通过该机制利用大量的企业信息。该机制的一种常见实现策略是通过构建企业级数据湖来提供统一的企业数据模型,在该机制中,数据湖负责捕获数据、处理数据、分析数据,以及为消费者系统提供数据服务。
数据湖能从以下方面帮助到企业:
1. 实现数据治理(data governance)与数据世系。
2. 通过应用机器学习与人工智能技术实现商业智能。
3. 预测分析,如领域特定的推荐引擎。
4. 信息追踪与一致性保障。
5. 根据对历史的分析生成新的数据维度。
6. 有一个集中式的能存储所有企业数据的数据中心,有利于实现一个针对数据传输优化的数据服务。
7. 帮助组织或企业做出更多灵活的关于企业增长的决策。
在本节中,我们讨论数据湖应该具备哪些能力。后续将会讨论和评述数据湖是如何工作的,以及应该如何去理解其工作机制。
数据湖是如何工作的
为了准确理解数据湖能给企业带来哪些好处,理解数据湖的工作机制以及构建功能齐全的数据湖需要哪些组件就显得尤为重要了。在一头扎进数据湖架构细节之前,不妨先来了解数据湖背景中的数据生命周期。
在一个较高的层面来看,数据湖中数据生命周期如图所示。

上述生命周期也可称为数据在数据湖中的多个不同阶段。每个阶段所需的数据和分析方法也有所不同。数据处理与分析既可按批量(batch)方式处理,也可以按近实时(near-real-time)方式处理。
数据湖的实现需要同时支持这两种处理方式,因为不同的处理方式服务于不同的场景。处理方式(批处理或近实时处理)的选择也依赖数据处理或分析任务的计算量,因为很多复杂计算不可能在近实时处理模式中完成,而在一些案例中,则不能接受较长的处理周期。
同样,存储系统的选择还依赖于数据访问的要求。例如,如果希望存储数据时便于通过SQL查询访问数据,则选择的存储系统必须支持SQL接口。
如果数据访问要求提供数据视图,则涉及将数据存储为对应的形式,即数据可以作为视图对外提供,并提供便捷的可管理性和可访问性。
最近出现的一个日渐重要的趋势是通过服务(service)来提供数据,它涉及在轻量级服务层上对外公开数据。每个对外公开的服务必须准确地描述服务功能并对外提供数据。此模式还支持基于服务的数据集成,这样其他系统可以消费数据服务提供的数据。
当数据从采集点流入数据湖时,它的元数据被捕获,并根据其生命周期中的数据敏感度从数据可追溯性、数据世系和数据安全等方面进行管理。
数据世系被定义为数据的生命周期,包括数据的起源以及数据是如何随时间移动的。它描述了数据在各种处理过程中发生了哪些变化,有助于提供数据分析流水线的可见性,并简化了错误溯源。可追溯性是通过标识记录来验证数据项的历史、位置或应用的能力。——维基百科
数据湖与数据仓库的区别
很多时候,数据湖被认为与数据仓库是等同的。实际上数据湖与数据仓库代表着企业想达成的不同目标。
下表中显示了两者的关键区别。
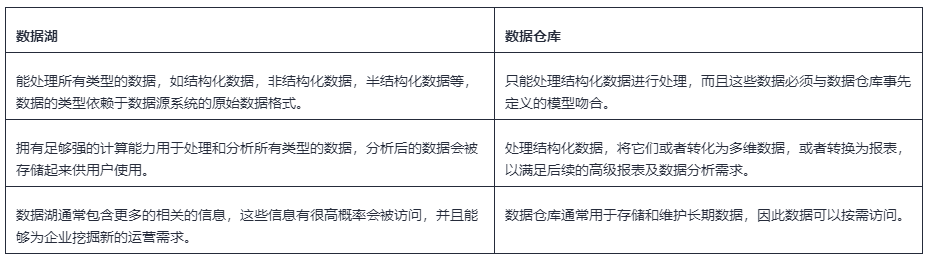
从图表来看,数据湖与数据仓库的差别很明显。然而,在企业中两者的作用是互补的,不应认为数据湖的出现是为了取代数据仓库,毕竟两者的作用是截然不同的。
数据湖的构建方法
不同的组织有不同的偏好,因此它们构建数据湖的方式也不一样。构建方法与业务、处理流程及现存系统等因素有关。
简单的数据湖实现几乎等价于定义一个中心数据源,所有的系统都可以使用这个中心数据源来满足所有的数据需求。虽然这种方法可能很简单,也很划算,但它可能不是一个非常实用的方法,原因如下:
1. 只有当这些组织重新开始构建其信息系统时,这种方法才可行。
2. 这种方法解决不了与现存系统相关的问题。
3. 即使组织决定用这种方法构建数据湖,也缺乏明确的责任和关注点隔离(responsibility and separation of concerns)。
4. 这样的系统通常尝试一次性完成所有的工作,但是最终会随着数据事务、分析和处理需求的增加而分崩离析。
更好的构建数据湖的策略是将企业及其信息系统作为一个整体来看待,对数据拥有关系进行分类,定义统一的企业模型。
这种方法虽然可能存在流程相关的挑战,并且可能需要花费更多的精力来对系统元素进行定义,但是它仍然能够提供所需的灵活性、控制和清晰的数据定义以及企业中不同系统实体之间的关注点隔离。
这样的数据湖也可以有独立的机制来捕获、处理、分析数据,并为消费者应用程序提供数据服务。


