网络KPI异常检测之时序分解算法
时间序列数据伴随着我们的生活和工作。从牙牙学语时的“1, 2, 3, 4, 5, ……”到房价的走势变化,从金融领域的刷卡记录到运维领域的核心网性能指标。时间序列中的规律能加深我们对事物和场景的认识,时间序列中的异常能提醒我们某些部分可能出现问题。那么如何去发现时间序列中的规律、找出其中的异常点呢?接下来,我们将揭开这些问题的面纱。
什么是异常
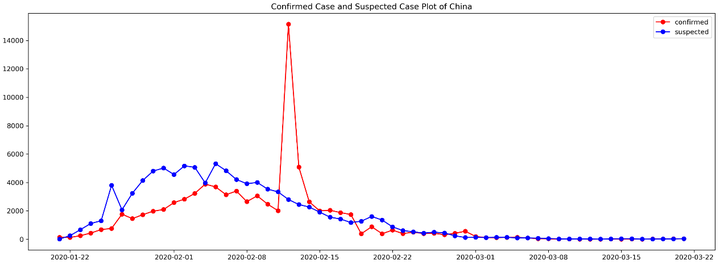
直观上讲,异常就是现实与心理预期产生较大差距的特殊情形。如2020年春节的新型肺炎(COVID-19,coronavirus disease 2019),可以看到2月12日有一个明显的确诊病例的升高,这就是一个异常点,如下图:
从统计上讲,严重偏离预期的点,常见的可以通过3-sigma准则来判定。
从数学上讲,它就是一个分段函数:

那么我们有哪些方法来发现异常呢?异常分析的方法有很多,在本文中,我们主要讲解时间序列分解的算法。接下来,我们先从时间序列的定义开始讲起。
什么是时间序列
前面章节,我们列举了生活和工作中的一些时间序列的例子,但是并没有给出定义。在本节中,我们将首先给出时间序列的定义,然后给出时间序列的分类方法,最后再给大家展示常见的时间序列。
1.时间序列的定义
时间序列是不同时间点的一系列变量所组成的有序序列。例如北京市2013年4月每日的平均气温就构成了一个时间序列,为了方便,我们一般认为序列中相邻元素具有相同的时间间隔。
时间序列可以分为确定的和随机的。例如,一个1990年出生的人,从1990年到1999年年龄可以表述为{0,1,2,…,9},这个序列并没有任何随机因素。这是一个确定性的时间序列。现实生活中我们所面对的序列更多的是掺杂了随机因素的时间序列,例如气温、销售量等等,这些是带有随机性的例子。我们说的时间序列一般是指带有随机性的。
那么对于随机性的时间序列,又如何进行分类呢?
2.时间序列的分类
从研究对象上分,时间序列分为一元时间序列和多元时间序列,如新冠肺炎例子中,只看确诊病例的变化,它是一元时间序列。如果把确诊病例和疑似病例联合起来看,它是一个多元时间序列。
从时间参数上分,时间序列分为离散时间的时间序列和连续时间的时间序列。例如气温变化曲线,通常是按照天、小时进行预测、计算的,这个采集的时间是离散的,因此,它是一个离散时间的时间序列。再如花粉在水中呈现不规则的运动,它无时无刻不在运动,它是一个连续时间的时间序列,这就是大家众所周知的布朗运动。在我们的工作中,我们一般遇到的都是离散时间的时间序列。
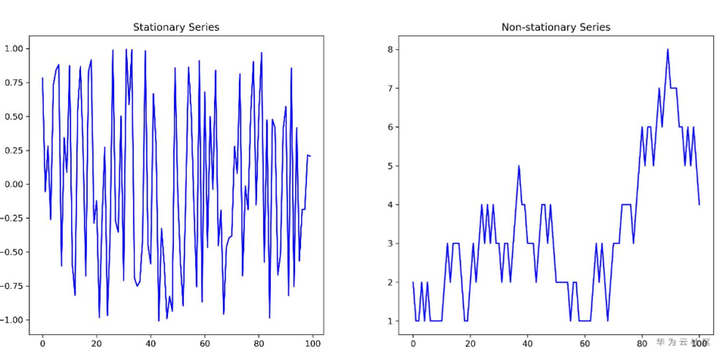
从统计特征上分,时间序列分为平稳时间序列和非平稳时间序列。平稳序列从直观上讲,均值和标准差不随着时间发生变化,而非平稳序列均值或者标准差一般会随着时间发生变化。下面两个图分别给出平稳序列和非平稳序列的例子。
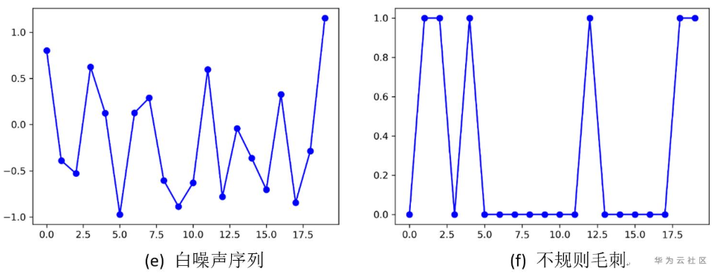
3.常见的时间序列
在本节,我们将给大家列举一些常见的时间序列,让大家对常见的时间序列有一个直观的概念。
时间序列的分解
前面给大家讲了异常和时间序列的概念,本章将给大家讲解时间序列分解技术。
1.目的
时间序列分解是探索时序变化规律的一种方法,主要探索周期性和趋势性。基于时序分解的结果,我们可以进行后续的时间预测和异常检测。
2.主要组成部分
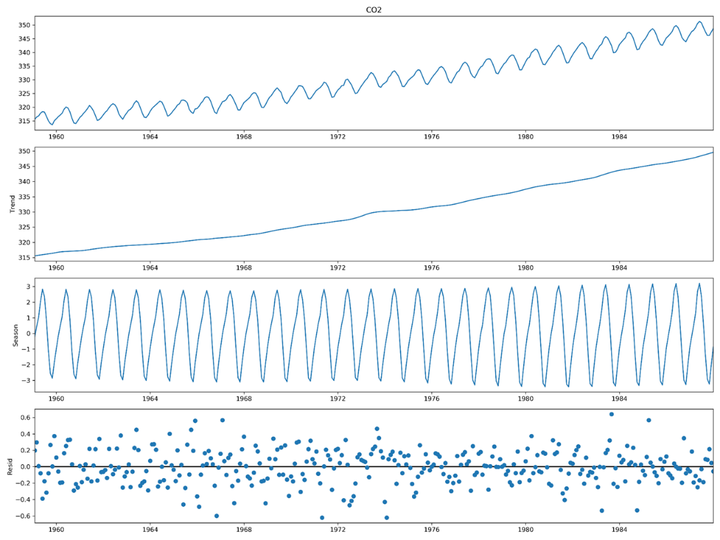
在时间序列分析中,我们经常要关注趋势和周期。因此,一般地,我们将时序分成三个部分:趋势部分、周期部分和残差部分。结合下图CO2含量的例子(见下图)对这三个主要部分进行解释:
1)趋势部分:展示了CO2含量逐年增加;
2)周期部分:反应了一年中CO2含量是周期波动的;
3)残差部分:趋势和周期部分不能解释的部分。
3.时序分解模型
时间序列分解基于分解模型的假设。通常,我们会考虑以下两种模型:

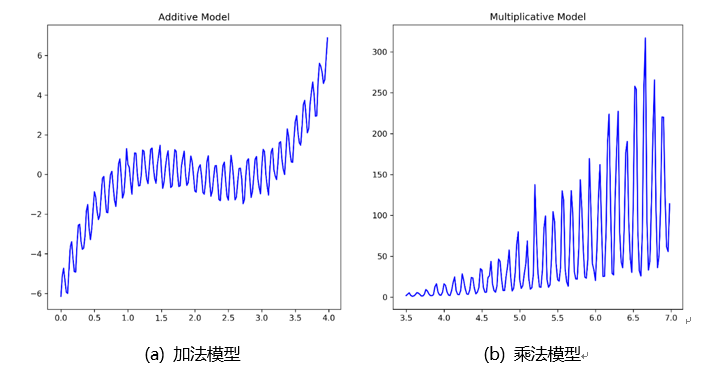
加法模型适用于以下场景:
- 当周期性不随着趋势发生变化时,首选加法模型,如下图(a);
- 当目标存在负值时,应选择加法模型;
乘法模型适用于以下场景:
- 周期随着随时发生变化时,首选乘法模型,如下图(b);
- 经济数据,首选乘法模型(增长率、可解释)。
另外,当我们不清楚选择哪个模型时,可以两个模型都使用,选择误差最小的那一个。
由于乘法模型与加法模型可以相互转化,我们后面仅以加法模型来进行介绍。
4.时序分解算法
基于周期、趋势分解的时序分解算法主要有经典时序分解算法、Holt-Winters算法和STL算法。经典时序分解算法起源于20世纪20年代,方法较简单。Holt-Winters算法于1960年由Holt的学生 Peter Winters 提出,能够适应随着时间变化的季节项。STL(Seasonal and Trend decomposition using Loess)分解法,由Cleveland 等于1990年提出,比较通用,且较为稳健。三者之间的关系,如下图所示:

4.1经典时序分解算法
经典时序分解算法是最简单的一种分解算法,它是很多其他分解算法的基础。该算法基于“季节部分不随着时间发生变化”这一假设,且需要知道序列的周期。另外,该算法基于滑动平均技术。
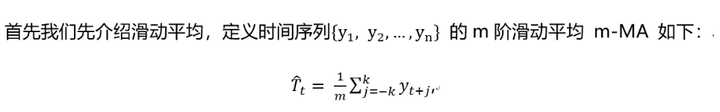
其中,m=2k+1. 也就是说,时刻t的趋势项的估计值可以通过前后k个时刻内的平均值得到。阶数 m 越大,趋势越光滑。由上面的公式可以看出,m一般取奇数,这保证了对称性。但是在很多场景下,周期是偶数,例如一年有4个季度,则周期为4,是偶数。此时,需要做先做一个4阶滑动平均(4-MA),再对所得结果做一个2阶滑动平均(2-MA),整个过程记为 。这样处理后的结果是对称的,即加权的滑动平均,数学表达如下:
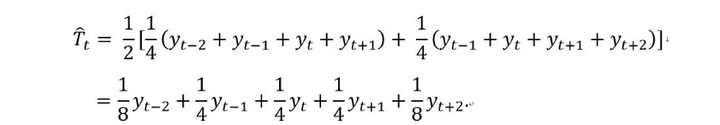
下面我们将讲解经典时序分解算法的计算步骤。

经典时序分解算法虽然简单、应用广泛,但是也存在一些问题:
1) 无法估计序列最前面几个和最后面几个的趋势和周期部分,例如若m=4,则无法估计前2个和后2个观测的趋势和周期的部分;
2) 严重依赖“季节性部分每个周期都是相同的”这一假设;
3) 过度光滑趋势部分。
4.2Holt-Winters算法
在上一节中,我们介绍了经典时序分解算法,但是它严重依赖“季节性部分每个周期都是相同的”这一假设。为了能够适应季节部分随时间发生变化,Holt-Winters算法被提出。Holt-Winters算法是基于简单指数光滑技术。首先,我们先介绍简单指数光滑技术。
简单指数光滑的思想主要是以下两点:
- 对未来的预测:用当前的水平对下一时刻的点进行预测;
- 当前水平的估计:使用当前时刻的观测值和预测值(基于历史观测数据的预测值,即上一时刻的水平)的加权平均作为当前水平的估计。
简单指数光滑的模型比较简单,如下:
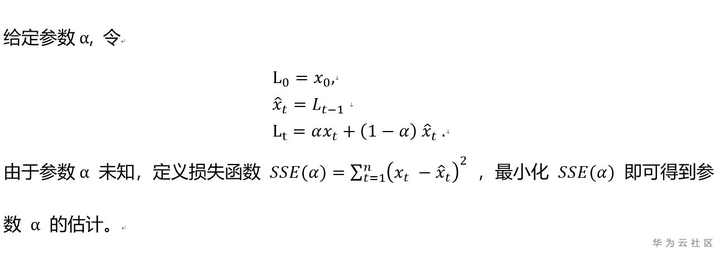
Holt-Winters算法是简单指数光滑在趋势(可理解为水平的变化率)和季节性上的推广,主要包括水平(前文中的趋势项)、趋势项和季节项三个部分。

4.3 STL算法
STL(Seasonal and Trend decomposition using Loess)是一个非常通用的、稳健性强的时序分解方法,其中Loess是一种估算非线性关系的方法。STL分解法由 Cleveland et al. (1990) 提出。
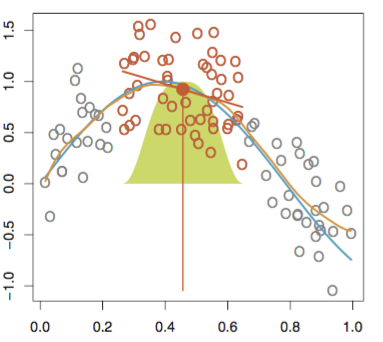
STL算法中最主要的是局部光滑技术 (locally weighted scatterplot smoothing, LOWESS or LOESS),有时也称为局部多项式回归拟合。它是对两维散点图进行平滑的常用方法,它结合了传统线性回归的简洁性和非线性回归的灵活性。当要估计某个响应变量值时,先从其预测点附近取一个数据子集(如下图实点 是要预测的点,选取周围的需点来进行拟合),然后对该子集进行线性回归或二次回归,回归时采用加权最小二乘法(如下图,采用的是高斯核进行加权),即越靠近估计点的值其权重越大,最后利用得到的局部回归模型来估计响应变量的值。用这种方法进行逐点运算得到整条拟合曲线。
STL算法的主要环节包含内循环、外循环和季节项后平滑三个部分:
- 内循环:

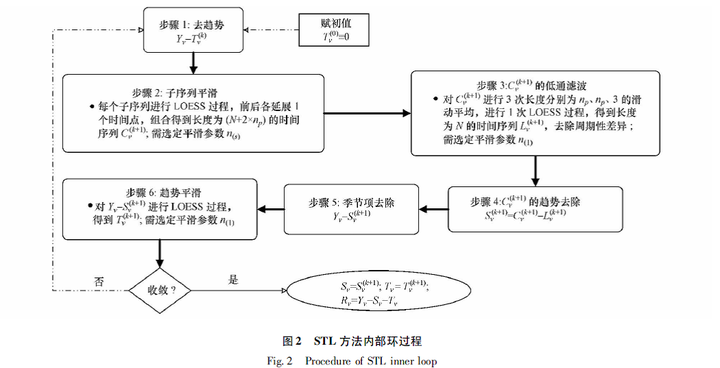
- 外循环:
外循环主要作用则是引入了一个稳健性权重项,以控制数据中异常值产生的影响,这一项将会考虑到下一阶段内循环的临近权重中去。
- 季节项后平滑:
趋势分量和季节分量都是在内循环中得到的。循环完后,季节项将出现一定程度的毛刺现象,因为在内循环中平滑时是在每一个截口中进行的,因此,在按照时间序列重排后,就无法保证相邻时段的平滑了,为此,还需要进行季节项的后平滑,后平滑基于局部二次拟合,并且不再需要在loess中进行稳健性迭代。
异常判断的准则
对于异常的判断,我们常用的有 n-sigma 准则和boxplot准则(箱线图准则)。那这些准备是如何计算的,有哪些区别和联系呢?
1.n-sigma 准则

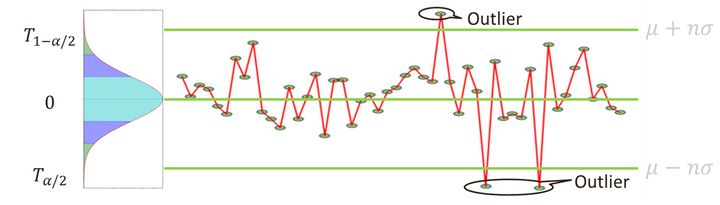
n-sigma准则有计算简单、效率高且有很强的理论支撑,但是需要近似正态的假设,且均值和标准差的计算用到了全部的数据,因此,受异常点的影响较大。
2.boxplot 准则
为了降低异常点的影响,boxplot准则被提出。boxplot(箱线图)是一种用作显示一组数据分散情况的统计图,经常用于异常检测。BoxPlot的核心在于计算一组数据的中位数、两个四分位数、上限和下限,基于这些统计值画出箱线图。

根据上面的统计值就可以画出下面的图,超过上限的点或这个低于下限的点都可以认为是异常点。
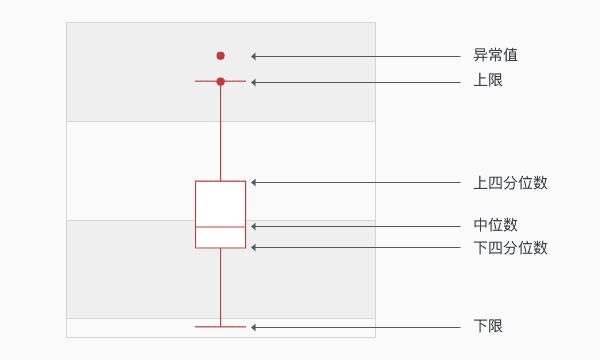
从上面的计算上可以看出,boxplot对异常点是稳健的。
基于时序分解的异常检测算法
在前面的章节,我们了解了时序分解的算法,也学习了异常判断的准则,那么如何基于时序分解进行异常检测呢?在本章,我们将首先给出异常检测算法的原理,再给出基于时序分解的异常检测算法步骤。
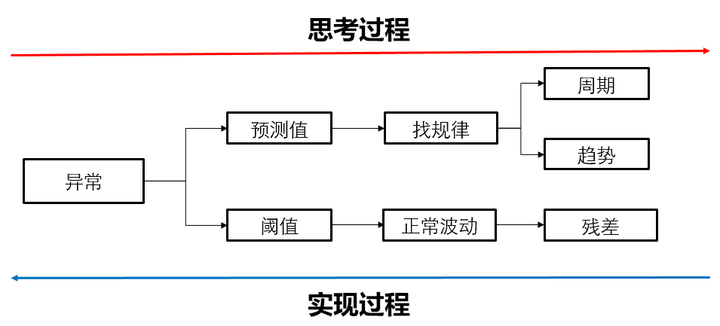
1.异常检测算法原理
回顾一下异常的定义,它是一个分段函数:
我们可以看到预测值(拟合值)和阈值是不知道的。对于预测值,我们可以通过找规律来猜这个预测值是多少,本章我们可以通过时序分解找周期和趋势的规律,进而得到预测值。对于阈值,我们可以看到阈值是针对真实值和预测值的差值设置的,目的是把异常值找到,因此我们只要找到正常值的残差和异常值的残差的边界即可。而我们n-sigma准则和boxplot准则就可以根据残差把边界找出来,即阈值。这个思考和实现的过程示意图如下:
2.基于时序分解的异常检测算法

Demo代码下载地址 ,本文主要是想记录基于时间序列的异常检测方法,希望能够帮到你。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号