


湖仓一体天花板,大数据一站式交互式SQL分析技术
本文分享自华为云社区《【华为云Stack】【大架光临】第7期:湖仓一体天花板,大数据一站式SQL分析技术实践》,作者:华为云HetuEngine首席架构师 武文博。
(一)背景
早在2020年5月华为云全球分析师大会中,华为率先提出“湖仓一体”概念,并落地在华为云FusionInsight智能数据湖解决方案中。其中,HetuEngine河图引擎承担一站式SQL分析引擎角色,使能跨源、跨域的一体化分析落地。基于云原生架构,让“逻辑数据湖”大规模数据融合分析提效50倍,本文将详细阐述HetuEngine在实现一站式SQL分析所面临的挑战、技术架构和案例。
(二)需求和挑战
我们调研了上千家客户,对于一站式SQL分析场景,客户提出了一些需求和期望:
-
跨域逻辑协同,通过计算去中心化,支持高度灵活、复杂拓扑的算力网络,并充分复用现网的硬件设备和数据资源,节省投资;
-
在跨源方面,打通数据源,将零散的数据,以高性价比的方式实现融合分析,减少ETL,节省时间成本;
-
云原生已是2021年的热词之一,大数据也不例外,跨源、跨域逻辑协同的数据虚拟化引擎也需要云原生的加持,以实现基于云的弹性伸缩、动态多租、统一入口;
正是因为政企业务爆发式增长,使其对大数据平台的性能要求越来越高,挑战也随之而来。
- 跨域要高效
在跨域协同计算时,临时性任务多,需灵活敏捷的SQL化跨域协同能力,以较小的数据成本和较短的耗时协同分析散落在不同机房、不同数据中心、不同数据源的数据,要求有如下特点:
• 一条SQL语句跨地域执行
业界现有的一些跨域协同方案并不是以SQL语句来实现的,而是在SQL引擎之上建设的一层非SQL接口的任务调度框架。这类实现方案技术难度较低,但是对于业务用户来说使用复杂,灵活性差,不可避免地存在多次数据落盘和拷贝,实时交互式查询场景无法满足时效性要求。
通过一条SQL语句实现跨地域分布式执行,从技术角度看,带给了业务用户优秀的用户体验和极低的学习门槛,接口简单扩展灵活。相应地,跨域协同SQL引擎本身就必须要克服一系列由此产生的困难与挑战。
• 提供近似本地使用体验
要实现跨域SQL访问,需要考虑的主要限制条件如下:
-
网络条件:跨域要面临的网络条件,往往要比本地网络条件劣化很多倍,客户经常碰到如高时延、低带宽、网络抖动、网络代理瓶颈、网段隔离等挑战;
-
SQL语法:如何在SQL语句层面很方便的表达出想要访问的数据中心下面的数据源的表?如何确保跨域SQL语句写法能够与本地SQL语句无缝衔接?
-
数据与系统安全:如何确保本地域以外的SQL用户只能感知到本地管理员对外开放的数据列表?如何做到本地域的计算资源、网络资源不被外部SQL请求所耗尽?
第1个问题直接关系到跨域协同的性能体验,第2个问题直接关系到跨域联邦SQL能否易落地、容易被业务用户所接受,第3个问题决定了跨源联邦SQL引擎能否成功上线。
如果跨域联邦SQL引擎无法做到高吞吐(单服务IP端口达到1GB/s的传输能力)、高性能(1000公里距离内100ms响应,亿行数据秒级拉取),那么很难认为这个跨域联邦SQL引擎达到真实商用水平。
• 动态感知不同地域的元数据
在早期的业界跨域方案中经常提到集中管理的全局元数据。这类方案的本质还是依靠中心化的主SQL引擎+集中存储的中心元数据来实现跨地的数据访问,通过繁琐、复杂的全局元数据采集、汇总来回避了改造传统SQL引擎内核所面临巨大技术挑战。相应地,这类方案上线后,需要持续投入管理运维人力进行跨地域的元数据汇总,每次上线或者下线一个数据中心都会牵一发而动全身,成为一个浩大、旷日持久的改造工程。
为了彻底解决上述方案的弊端,新一代的跨域联邦SQL引擎要具备跨域动态感知元数据的能力。客户通过简单部署配置即可直接上线,无需介入类似元数据管理等与业务强耦合的复杂准备工作中。反之,通过修改配置即可让一个Region/DC脱离联邦SQL查询网络。

- 跨源要易用
跨源分析中首要问题是如何实现多源异构SQL化分析,目前,市场上真正满足客户需求的引擎并不多,主要是因为:
• 一条SQL访问多个异构数据源
要实现这个目标,降低客户使用大数据的门槛,简而言之要做4个“一”:一个SQL语句,一个元数据模型,一个访问入口,一个鉴权体系。既要实现对多源异构数据的统一SQL查询和分析,又要保持与传统数据库的SQL语法体验一致。
• 跨源保障高性能
在跨源访问方面,要解决两个关键问题:
-
如何尽可能地降低被访问的数据源的出口数据量和数据传输损耗;
-
如何尽可能地降低跨源SQL引擎的计算工作量和导入数据量。
• 数据源信息可自定义,可实时刷新,关键敏感信息自动加密
这一点的必要性对于业务管理员来说不言而喻,但是往往被开源社区或尚未达到商用水平的跨源引擎所忽略。要做好这一点,需要从部署、元数据管理、服务化等多个角度进行建设。从对外接口类型看,跨域、跨源分析引擎要具备两个类型的接口:
• 业务接口
面向普通SQL用户,提供统一的服务化访问入口,屏蔽后方的多个计算实例细节信息,提供与传统OLAP引擎一致的业务交互体验;
• 管理接口
面向平台、业务管理员,提供常见的运维管理配置服务,涉及——用户认证、资源调配、数据源信息集中管理、业务访问权限定义等能力。这些业务配置信息需要完善的后台系统提供加解密管理和持久化存储。
上述两个接口面向不同的角色开放,不同的角色的用户感知不到其它角色的行为。从而实现信息隔离和高水平的服务化。
总之,理想的效果是——不论用户正在访问的是跨域的数据,还是跨源的数据,我们都要让业务用户的使用体验与传统的OLAP引擎体验保持一致。这也正是数据虚拟化力求达到的效果。
- 引擎云原生化
近年来,云原生技术方兴未艾,一大批云原生的数仓、OLAP引擎、湖仓一体引擎正在迅猛发展,有影响力的分析引擎都已搬迁上云。其中海外提供云原生大数据服务,比较有代表性的有Databricks、Snowflake等,其市值已达千亿美元。

我们认为,一款云原生的分析引擎至少要具备以下能力:
• 租户资源隔离化
云原生状态下,要求实现租户之间资源完全隔离,通过资源隔离消除运行风险,提升数据安全。
• 资源策略灵活化
灵活的资源策略有助于降低运营成本,常见的资源策略包括——动态资源分配实时生效,支持动态、静态部署方式,单个租户实例要支持无损业务的弹性伸缩。
• 故障快速自动恢复,在线滚动重启
云原生动态部署在带来灵活性的同时,也造成了单个实例的实际运行物理位置的随机性。万一发生故障时,需要整个系统具备自动检测、自动重新部署实现快速恢复。同时,在线滚动重启也是当下云原生引擎的标配。
(三)数据虚拟化引擎HetuEngine
随着大数据平台在各行业的快速发展,大数据集群呈现零散式建设、湖仓割裂、来回搬迁等新挑战,客户对于跨域高效、跨源易用、云原生化提出了更高的要求。
传统方案普遍涉及了下图中的1、2点。对于单企业、小规模业务场景而言,在业务发展初期基本可满足需求,但是对技术开发、维护人员的技能要求较高,一旦业务发生变化就需要重新定制开发,手工变更部署方案,易造成信息泄露。
为了打造一款成熟、可商用的虚拟化引擎,我们需要站在客户实际使用场景角度出发,系统性、端到端地设计一款安全、易用、易运维、可扩展的数据虚拟化引擎。
实践经验表明,上图中3、4、5、6点是决定一款数据虚拟化引擎能否满足业务实际需求、能否高效上线业务的关键。
HetuEngine架构
HetuEngine是华为云FusionInsight团队自研的一款高性能分布式SQL查询&数据虚拟化引擎,可与大数据生态无缝融合,实现海量数据秒级查询;支持多源异构协同,使能数据湖内/湖间/湖仓一站式SQL融合分析。
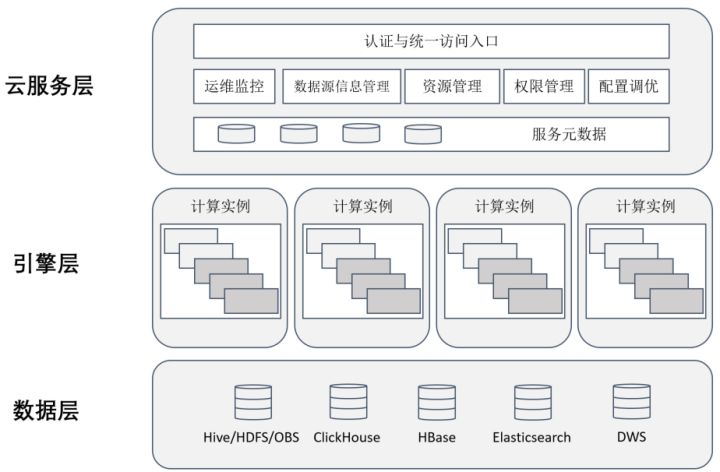
图 HetuEngine架构图
我们完全基于云原生2.0的技术理念实施了HetuEngine顶层架构设计,这一点决定了HetuEngine从一开始就是为云服务化、“湖仓一体”而生。统一的云服务层在带来极简操作和极致运维体验的同时,也为引擎层的多实例、弹性伸缩、跨域跨源统一访问入口、数据虚拟化等能力奠定了软件架构基础。
面向跨域、跨源、云原生三大维度,HetuEngine分别具有如下架构优势:
- 跨域联邦分析:SQL化、一致性体验、动态感知
HetuEngine对外提供标准、统一的SQL访问入口,同时通过后台管理接口的实现在线、实时、无损业务的运维变更操作,并保证所有变更操作能够快速同步到每一个计算实例,从而保证了SQL入口的一致性体验。

与此同时,跨域联邦查询场景中,每个地域的HetuEngine能够做到自动感知其它地域对外开放的元数据信息,按需动态实时感知和获取,从而降低了跨域元数据同步的安全风险和负载压力。
HetuEngine内置提供了高性能安全加密传输通道,使得跨地域间网络通信问题迎刃而解。该跨域联邦SQL分析方案安全高效,适用于公网、专网等多种网络类型混合组网,支持穿透NAT。支持亿级数据秒级跨域,支持去中心化跨域组网,支持受控对外开放数据,跨域协同效率提升50倍。
- 跨源协同分析:低门槛、高性能、安全可靠
HetuEngine提供可视化的数据源信息管理页面,实现一站式数据源信息配置和实时在线生效,避免了每次做数据源信息变更需要重启计算引擎实例的麻烦。针对不同数据源类型,HetuEngine会针对性提供不同的性能优化配置参数,并支持设置与具体业务环境需求强相关的个性化配置参数,通过前台页面一站式完成配置,免去了95%的运维负担。
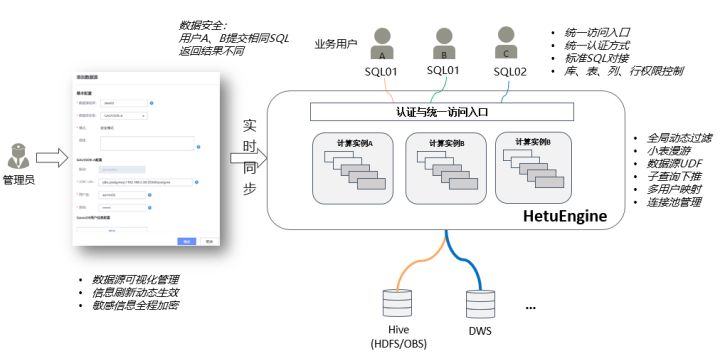
在性能方面,HetuEngine加强了对DWS、ES等数据源的计算下推能力,实现了相对开源软件提速5倍的高性能跨源协同分析效果。同时,HetuEngine完成了对Hive SQL语法兼容性增强,在支持100% Presto SQL语法的同时,还可支撑90%的HQL业务平滑迁移。
- 云原生加持:弹性伸缩、动态多租、统一入口
得益于云原生技术架构,HetuEngine允许管理员通过后台接口进行可视化的统一运维操作,从而完成一键式动态部署、多计算实例在线滚动重启、人工/全自动触发的计算实例弹性伸缩(无损业务),完成多租户的资源配置变更及动态生效。
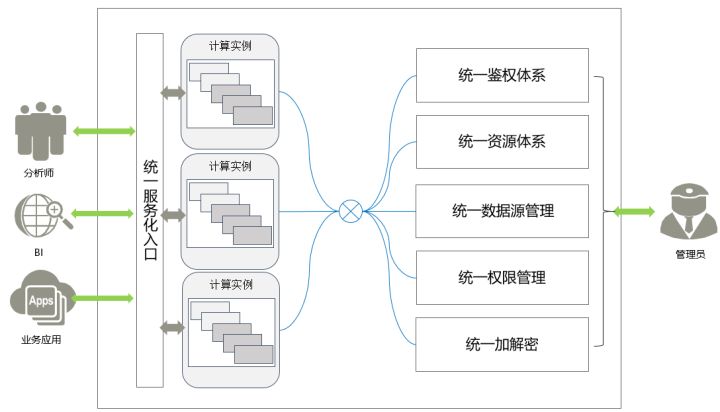
HetuEngine的统一服务化入口可以很容易帮助用户实现SQL客户端的接入和业务请求的提交,极大降低了业务用户的学习成本和开发成本。同时也帮助业务应用开发人员实现将业务层与后台服务层解耦的目的,为后期的持续扩容与升级变更操作带来的隐形福利。
HetuEngine的多计算实例架构天然具备横向扩展的优势,可以满足“湖仓一体”对海量数据、多实例、高并发的长远需求。
(四)最佳实践
随着金融业的快速发展和大数据技术生态的不断完善,近年来工行与华为持续联合创新,通过引入FusionInsight智能数据湖,工行大数据技术从仅对大数据批量加工,已延展到大数据实时计算、联机查询、数据可视化、安全管控等金融应用场景,不断提升工行服务实体经济的能力,倾力打造服务于经济高质量发展的数字工行。 目前工行已建成同业最大的单集群,已部署上线的FusionInsight MRS云原生数据湖和DWS云数据仓库集群规模达2000+节点,支撑了300+总行应用、分行及集团子公司的平台化大数据应用开发,日均承载批量计算作业数达20万+,强力支撑了行内、行外的金融数据服务。

中国工商银行大数据平台支撑了全行约13000名数据分析师的交互式查询业务场景,原先通过离线计算引擎来支撑,分析师普遍反映响应时间过长。从2021年工行开始引入交互式查询引擎(HetuEngine),使得分析师灵活查询的响应时间从平均1000秒降低至20秒,提效50倍,目前已将HetuEngine面向全行推广。
(五)写在最后
在业界现有的跨域、跨源分析引擎中,能够同时做到以下几点的,当前已知的仅有HetuEngine,这得益于:
• 三位一体:跨域、跨源、交互式查询一体化;
• 云原生:动态多租户、弹性伸缩、统一入口;
• 规模商用:提供端到端的安全解决方案;
目前,HetuEngine已经在政务、金融、运营商、大企业行业规模交付,对原有交互式查询、跨源跨域分析业务提升倍数,并驱动客户业务持续创新。
未来,HetuEngine还将在自学习优化、SQL安全、物化视图、索引、存储等维度,继续构筑核心竞争力,加速客户“湖仓一体”架构落地和数字化转型。
华为云FusionInsight MRS云原生数据湖提供一个架构实现三种数据湖,即离线数据湖,一站式提供AI、BI多引擎,规模最大支持6万+;实时数据湖,分钟级供数,全自助分析,时效从T+1到T+0;逻辑数据湖,HetuEngine实现跨湖、跨仓协同提效50倍。目前FusionInsight MRS已经用于60多个国家和地区,联合800+ISV服务于3000+政务、金融、运营商、泛企业客户,助力客户构建一企一湖,一城一湖。在2021年12月27日发布的IDC中国2021H1大数据市场报告中,华为云FusionInsight取得市场第一,更多信息请关注华为云社区。
本文由华为云发布。

