

【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理(1)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度。有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可以识别手写数字,我们要采用卷积神经网络CNN来进行别呢?CNN到底是怎么识别的?用CNN有哪些优势呢?我们下面就来简单分析一下。在讲CNN之前,为避免完全零基础的人看不懂后面的讲解,我们先简单回顾一下传统的神经网络的基本知识。
神经网络的预备知识
为什么要用神经网络?
-
特征提取的高效性。
大家可能会疑惑,对于同一个分类任务,我们可以用机器学习的算法来做,为什么要用神经网络呢?大家回顾一下,一个分类任务,我们在用机器学习算法来做时,首先要明确feature和label,然后把这个数据"灌"到算法里去训练,最后保存模型,再来预测分类的准确性。但是这就有个问题,即我们需要实现确定好特征,每一个特征即为一个维度,特征数目过少,我们可能无法精确的分类出来,即我们所说的欠拟合,如果特征数目过多,可能会导致我们在分类过程中过于注重某个特征导致分类错误,即过拟合。
举个简单的例子,现在有一堆数据集,让我们分类出西瓜和冬瓜,如果只有两个特征:形状和颜色,可能没法分区来;如果特征的维度有:形状、颜色、瓜瓤颜色、瓜皮的花纹等等,可能很容易分类出来;如果我们的特征是:形状、颜色、瓜瓤颜色、瓜皮花纹、瓜蒂、瓜籽的数量,瓜籽的颜色、瓜籽的大小、瓜籽的分布情况、瓜籽的XXX等等,很有可能会过拟合,譬如有的冬瓜的瓜籽数量和西瓜的类似,模型训练后这类特征的权重较高,就很容易分错。这就导致我们在特征工程上需要花很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
-
数据格式的简易性
在一个传统的机器学习分类问题中,我们“灌”进去的数据是不能直接灌进去的,需要对数据进行一些处理,譬如量纲的归一化,格式的转化等等,不过在神经网络里我们不需要额外的对数据做过多的处理,具体原因可以看后面的详细推导。
-
参数数目的少量性
在面对一个分类问题时,如果用SVM来做,我们需要调整的参数需要调整核函数,惩罚因子,松弛变量等等,不同的参数组合对于模型的效果也不一样,想要迅速而又准确的调到最适合模型的参数需要对背后理论知识的深入了解(当然,如果你说全部都试一遍也是可以的,但是花的时间可能会更多),对于一个基本的三层神经网络来说(输入-隐含-输出),我们只需要初始化时给每一个神经元上随机的赋予一个权重w和偏置项b,在训练过程中,这两个参数会不断的修正,调整到最优质,使模型的误差最小。所以从这个角度来看,我们对于调参的背后理论知识并不需要过于精通(只不过做多了之后可能会有一些经验,在初始值时赋予的值更科学,收敛的更快罢了)
有哪些应用?
应用非常广,不过大家注意一点,我们现在所说的神经网络,并不能称之为深度学习,神经网络很早就出现了,只不过现在因为不断的加深了网络层,复杂化了网络结构,才成为深度学习,并在图像识别、图像检测、语音识别等等方面取得了不错的效果。
基本网络结构
一个神经网络最简单的结构包括输入层、隐含层和输出层,每一层网络有多个神经元,上一层的神经元通过激活函数映射到下一层神经元,每个神经元之间有相对应的权值,输出即为我们的分类类别。
详细数学推导
去年中旬我参考吴恩达的UFLDL和mattmazur的博客写了篇文章详细讲解了一个最简单的神经网络从前向传播到反向传播的直观推导,大家可以先看看这篇文章--一文弄懂神经网络中的反向传播法--BackPropagation。
优缺点
前面说了很多优点,这里就不多说了,简单说说缺点吧。我们试想一下如果加深我们的网络层,每一个网络层增加神经元的数量,那么参数的个数将是M*N(m为网络层数,N为每层神经元个数),所需的参数会非常多,参数一多,模型就复杂了,越是复杂的模型就越不好调参,也越容易过拟合。此外我们从神经网络的反向传播的过程来看,梯度在反向传播时,不断的迭代会导致梯度越来越小,即梯度消失的情况,梯度一旦趋于0,那么权值就无法更新,这个神经元相当于是不起作用了,也就很难导致收敛。尤其是在图像领域,用最基本的神经网络,是不太合适的。后面我们会详细讲讲为啥不合适。
为什么要用卷积神经网络?
传统神经网络的劣势
前面说到在图像领域,用传统的神经网络并不合适。我们知道,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色的图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有:784*15*10+15+10=117625个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。(评论中有同学对这个参数计算不太理解,我简单说一下:图片是由像素点组成的,用矩阵表示的,28*28的矩阵,肯定是没法直接放到神经元里的,我们得把它“拍平”,变成一个28*28=784 的一列向量,这一列向量和隐含层的15个神经元连接,就有784*15=11760个权重w,隐含层和最后的输出层的10个神经元连接,就有11760*10=117600个权重w,再加上隐含层的偏置项15个和输出层的偏置项10个,就是:117625个参数了)
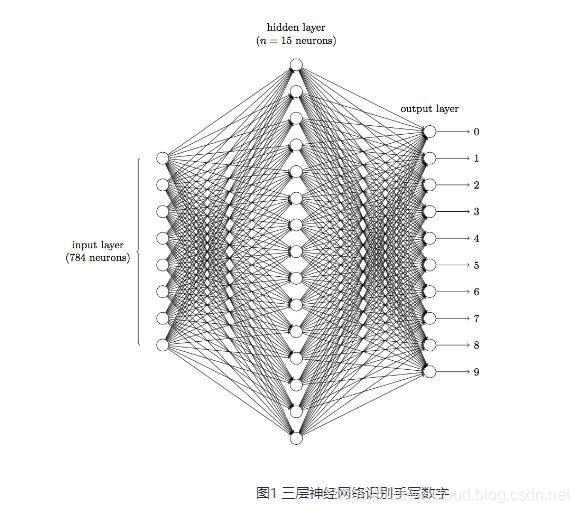
卷积神经网络是什么?
三个基本层
-
卷积层(Convolutional Layer)
上文提到我们用传统的三层神经网络需要大量的参数,原因在于每个神经元都和相邻层的神经元相连接,但是思考一下,这种连接方式是必须的吗?全连接层的方式对于图像数据来说似乎显得不这么友好,因为图像本身具有“二维空间特征”,通俗点说就是局部特性。譬如我们看一张猫的图片,可能看到猫的眼镜或者嘴巴就知道这是张猫片,而不需要说每个部分都看完了才知道,啊,原来这个是猫啊。所以如果我们可以用某种方式对一张图片的某个典型特征识别,那么这张图片的类别也就知道了。这个时候就产生了卷积的概念。举个例子,现在有一个4*4的图像,我们设计两个卷积核,看看运用卷积核后图片会变成什么样。
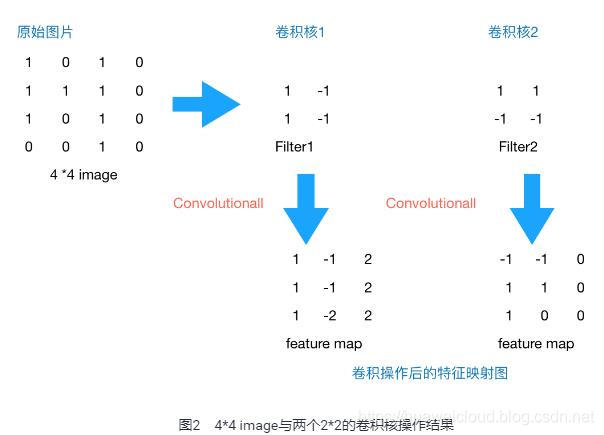
由上图可以看到,原始图片是一张灰度图片,每个位置表示的是像素值,0表示白色,1表示黑色,(0,1)区间的数值表示灰色。对于这个4*4的图像,我们采用两个2*2的卷积核来计算。设定步长为1,即每次以2*2的固定窗口往右滑动一个单位。以第一个卷积核filter1为例,计算过程如下:
1 feature_map1(1,1) = 1*1 + 0*(-1) + 1*1 + 1*(-1) = 1
2 feature_map1(1,2) = 0*1 + 1*(-1) + 1*1 + 1*(-1) = -1
3 ```
4 feature_map1(3,3) = 1*1 + 0*(-1) + 1*1 + 0*(-1) = 2可以看到这就是最简单的内积公式。feature_map1(1,1)表示在通过第一个卷积核计算完后得到的feature_map的第一行第一列的值,随着卷积核的窗口不断的滑动,我们可以计算出一个3*3的feature_map1;同理可以计算通过第二个卷积核进行卷积运算后的feature_map2,那么这一层卷积操作就完成了。feature_map尺寸计算公式:[ (原图片尺寸 -卷积核尺寸)/ 步长 ] + 1。这一层我们设定了两个2*2的卷积核,在paddlepaddle里是这样定义的:
conv_pool_1 = paddle.networks.simple_img_conv_pool(
input=img,
filter_size=3,
num_filters=2,
num_channel=1,
pool_stride=1,
act=paddle.activation.Relu())这里调用了networks里simple_img_conv_pool函数,激活函数是Relu(修正线性单元),我们来看一看源码里外层接口是如何定义的:
1 def simple_img_conv_pool(input,
2 filter_size,
3 num_filters,
4 pool_size,
5 name=None,
6 pool_type=None,
7 act=None,
8 groups=1,
9 conv_stride=1,
10 conv_padding=0,
11 bias_attr=None,
12 num_channel=None,
13 param_attr=None,
14 shared_bias=True,
15 conv_layer_attr=None,
16 pool_stride=1,
17 pool_padding=0,
18 pool_layer_attr=None):
19 """
20 Simple image convolution and pooling group.
21 Img input => Conv => Pooling => Output.
22 :param name: group name.
23 :type name: basestring
24 :param input: input layer.
25 :type input: LayerOutput
26 :param filter_size: see img_conv_layer for details.
27 :type filter_size: int
28 :param num_filters: see img_conv_layer for details.
29 :type num_filters: int
30 :param pool_size: see img_pool_layer for details.
31 :type pool_size: int
32 :param pool_type: see img_pool_layer for details.
33 :type pool_type: BasePoolingType
34 :param act: see img_conv_layer for details.
35 :type act: BaseActivation
36 :param groups: see img_conv_layer for details.
37 :type groups: int
38 :param conv_stride: see img_conv_layer for details.
39 :type conv_stride: int
40 :param conv_padding: see img_conv_layer for details.
41 :type conv_padding: int
42 :param bias_attr: see img_conv_layer for details.
43 :type bias_attr: ParameterAttribute
44 :param num_channel: see img_conv_layer for details.
45 :type num_channel: int
46 :param param_attr: see img_conv_layer for details.
47 :type param_attr: ParameterAttribute
48 :param shared_bias: see img_conv_layer for details.
49 :type shared_bias: bool
50 :param conv_layer_attr: see img_conv_layer for details.
51 :type conv_layer_attr: ExtraLayerAttribute
52 :param pool_stride: see img_pool_layer for details.
53 :type pool_stride: int
54 :param pool_padding: see img_pool_layer for details.
55 :type pool_padding: int
56 :param pool_layer_attr: see img_pool_layer for details.
57 :type pool_layer_attr: ExtraLayerAttribute
58 :return: layer's output
59 :rtype: LayerOutput
60 """
61 _conv_ = img_conv_layer(
62 name="%s_conv" % name,
63 input=input,
64 filter_size=filter_size,
65 num_filters=num_filters,
66 num_channels=num_channel,
67 act=act,
68 groups=groups,
69 stride=conv_stride,
70 padding=conv_padding,
71 bias_attr=bias_attr,
72 param_attr=param_attr,
73 shared_biases=shared_bias,
74 layer_attr=conv_layer_attr)
75 return img_pool_layer(
76 name="%s_pool" % name,
77 input=_conv_,
78 pool_size=pool_size,
79 pool_type=pool_type,
80 stride=pool_stride,
81 padding=pool_padding,
82 layer_attr=pool_layer_attr)我们在Paddle/python/paddle/v2/framework/nets.py 里可以看到simple_img_conv_pool这个函数的定义:
1 def simple_img_conv_pool(input,
2 num_filters,
3 filter_size,
4 pool_size,
5 pool_stride,
6 act,
7 pool_type='max',
8 main_program=None,
9 startup_program=None):
10 conv_out = layers.conv2d(
11 input=input,
12 num_filters=num_filters,
13 filter_size=filter_size,
14 act=act,
15 main_program=main_program,
16 startup_program=startup_program)
17
18 pool_out = layers.pool2d(
19 input=conv_out,
20 pool_size=pool_size,
21 pool_type=pool_type,
22 pool_stride=pool_stride,
23 main_program=main_program,
24 startup_program=startup_program)
25 return pool_out
可以看到这里面有两个输出,conv_out是卷积输出值,pool_out是池化输出值,最后只返回池化输出的值。conv_out和pool_out分别又调用了layers.py的conv2d和pool2d,去layers.py里我们可以看到conv2d和pool2d是如何实现的:
conv2d:
def conv2d(input,
num_filters,
name=None,
filter_size=[1, 1],
act=None,
groups=None,
stride=[1, 1],
padding=None,
bias_attr=None,
param_attr=None,
main_program=None,
startup_program=None):
helper = LayerHelper('conv2d', **locals())
dtype = helper.input_dtype()
num_channels = input.shape[1]
if groups is None:
num_filter_channels = num_channels
else:
if num_channels % groups is not 0:
raise ValueError("num_channels must be divisible by groups.")
num_filter_channels = num_channels / groups
if isinstance(filter_size, int):
filter_size = [filter_size, filter_size]
if isinstance(stride, int):
stride = [stride, stride]
if isinstance(padding, int):
padding = [padding, padding]
input_shape = input.shape
filter_shape = [num_filters, num_filter_channels] + filter_size
std = (2.0 / (filter_size[0]**2 * num_channels))**0.5
filter = helper.create_parameter(
attr=helper.param_attr,
shape=filter_shape,
dtype=dtype,
initializer=NormalInitializer(0.0, std, 0))
pre_bias = helper.create_tmp_variable(dtype)
helper.append_op(
type='conv2d',
inputs={
'Input': input,
'Filter': filter,
},
outputs={"Output": pre_bias},
attrs={'strides': stride,
'paddings': padding,
'groups': groups})
pre_act = helper.append_bias_op(pre_bias, 1)
return helper.append_activation(pre_act)pool2d:
def pool2d(input,
2 pool_size,
3 pool_type,
4 pool_stride=[1, 1],
5 pool_padding=[0, 0],
6 global_pooling=False,
7 main_program=None,
8 startup_program=None):
9 if pool_type not in ["max", "avg"]:
10 raise ValueError(
11 "Unknown pool_type: '%s'. It can only be 'max' or 'avg'.",
12 str(pool_type))
13 if isinstance(pool_size, int):
14 pool_size = [pool_size, pool_size]
15 if isinstance(pool_stride, int):
16 pool_stride = [pool_stride, pool_stride]
17 if isinstance(pool_padding, int):
18 pool_padding = [pool_padding, pool_padding]
19
20 helper = LayerHelper('pool2d', **locals())
21 dtype = helper.input_dtype()
22 pool_out = helper.create_tmp_variable(dtype)
23
24 helper.append_op(
25 type="pool2d",
26 inputs={"X": input},
27 outputs={"Out": pool_out},
28 attrs={
29 "poolingType": pool_type,
30 "ksize": pool_size,
31 "globalPooling": global_pooling,
32 "strides": pool_stride,
33 "paddings": pool_padding
34 })
35大家可以看到,具体的实现方式还调用了layers_helper.py:
1 import copy
2 import itertools
3
4 from paddle.v2.framework.framework import Variable, g_main_program, \
5 g_startup_program, unique_name, Program
6 from paddle.v2.framework.initializer import ConstantInitializer, \
7 UniformInitializer
8
9
10 class LayerHelper(object):
11 def __init__(self, layer_type, **kwargs):
12 self.kwargs = kwargs
13 self.layer_type = layer_type
14 name = self.kwargs.get('name', None)
15 if name is None:
16 self.kwargs['name'] = unique_name(self.layer_type)
17
18 @property
19 def name(self):
20 return self.kwargs['name']
21
22 @property
23 def main_program(self):
24 prog = self.kwargs.get('main_program', None)
25 if prog is None:
26 return g_main_program
27 else:
28 return prog
29
30 @property
31 def startup_program(self):
32 prog = self.kwargs.get('startup_program', None)
33 if prog is None:
34 return g_startup_program
35 else:
36 return prog
37
38 def append_op(self, *args, **kwargs):
39 return self.main_program.current_block().append_op(*args, **kwargs)
40
41 def multiple_input(self, input_param_name='input'):
42 inputs = self.kwargs.get(input_param_name, [])
43 type_error = TypeError(
44 "Input of {0} layer should be Variable or sequence of Variable".
45 format(self.layer_type))
46 if isinstance(inputs, Variable):
47 inputs = [inputs]
48 elif not isinstance(inputs, list) and not isinstance(inputs, tuple):
49 raise type_error
50 else:
51 for each in inputs:
52 if not isinstance(each, Variable):
53 raise type_error
54 return inputs
55
56 def input(self, input_param_name='input'):
57 inputs = self.multiple_input(input_param_name)
58 if len(inputs) != 1:
59 raise "{0} layer only takes one input".format(self.layer_type)
60 return inputs[0]
61
62 @property
63 def param_attr(self):
64 default = {'name': None, 'initializer': UniformInitializer()}
65 actual = self.kwargs.get('param_attr', None)
66 if actual is None:
67 actual = default
68 for default_field in default.keys():
69 if default_field not in actual:
70 actual[default_field] = default[default_field]
71 return actual
72
73 def bias_attr(self):
74 default = {'name': None, 'initializer': ConstantInitializer()}
75 bias_attr = self.kwargs.get('bias_attr', None)
76 if bias_attr is True:
77 bias_attr = default
78
79 if isinstance(bias_attr, dict):
80 for default_field in default.keys():
81 if default_field not in bias_attr:
82 bias_attr[default_field] = default[default_field]
83 return bias_attr
84
85 def multiple_param_attr(self, length):
86 param_attr = self.param_attr
87 if isinstance(param_attr, dict):
88 param_attr = [param_attr]
89
90 if len(param_attr) != 1 and len(param_attr) != length:
91 raise ValueError("parameter number mismatch")
92 elif len(param_attr) == 1 and length != 1:
93 tmp = [None] * length
94 for i in xrange(length):
95 tmp[i] = copy.deepcopy(param_attr[0])
96 param_attr = tmp
97 return param_attr
98
99 def iter_inputs_and_params(self, input_param_name='input'):
100 inputs = self.multiple_input(input_param_name)
101 param_attrs = self.multiple_param_attr(len(inputs))
102 for ipt, param_attr in itertools.izip(inputs, param_attrs):
103 yield ipt, param_attr
104
105 def input_dtype(self, input_param_name='input'):
106 inputs = self.multiple_input(input_param_name)
107 dtype = None
108 for each in inputs:
109 if dtype is None:
110 dtype = each.data_type
111 elif dtype != each.data_type:
112 raise ValueError("Data Type mismatch")
113 return dtype
114
115 def create_parameter(self, attr, shape, dtype, suffix='w',
116 initializer=None):
117 # Deepcopy the attr so that parameters can be shared in program
118 attr_copy = copy.deepcopy(attr)
119 if initializer is not None:
120 attr_copy['initializer'] = initializer
121 if attr_copy['name'] is None:
122 attr_copy['name'] = unique_name(".".join([self.name, suffix]))
123 self.startup_program.global_block().create_parameter(
124 dtype=dtype, shape=shape, **attr_copy)
125 return self.main_program.global_block().create_parameter(
126 name=attr_copy['name'], dtype=dtype, shape=shape)
127
128 def create_tmp_variable(self, dtype):
129 return self.main_program.current_block().create_var(
130 name=unique_name(".".join([self.name, 'tmp'])),
131 dtype=dtype,
132 persistable=False)
133
134 def create_variable(self, *args, **kwargs):
135 return self.main_program.current_block().create_var(*args, **kwargs)
136
137 def create_global_variable(self, persistable=False, *args, **kwargs):
138 return self.main_program.global_block().create_var(
139 *args, persistable=persistable, **kwargs)
140
141 def set_variable_initializer(self, var, initializer):
142 assert isinstance(var, Variable)
143 self.startup_program.global_block().create_var(
144 name=var.name,
145 type=var.type,
146 dtype=var.data_type,
147 shape=var.shape,
148 persistable=True,
149 initializer=initializer)
150
151 def append_bias_op(self, input_var, num_flatten_dims=None):
152 """
153 Append bias operator and return its output. If the user does not set
154 bias_attr, append_bias_op will return input_var
155
156 :param input_var: the input variable. The len(input_var.shape) is larger
157 or equal than 2.
158 :param num_flatten_dims: The input tensor will be flatten as a matrix
159 when adding bias.
160 `matrix.shape = product(input_var.shape[0:num_flatten_dims]), product(
161 input_var.shape[num_flatten_dims:])`
162 """
163 if num_flatten_dims is None:
164 num_flatten_dims = self.kwargs.get('num_flatten_dims', None)
165 if num_flatten_dims is None:
166 num_flatten_dims = 1
167
168 size = list(input_var.shape[num_flatten_dims:])
169 bias_attr = self.bias_attr()
170 if not bias_attr:
171 return input_var
172
173 b = self.create_parameter(
174 attr=bias_attr, shape=size, dtype=input_var.data_type, suffix='b')
175 tmp = self.create_tmp_variable(dtype=input_var.data_type)
176 self.append_op(
177 type='elementwise_add',
178 inputs={'X': [input_var],
179 'Y': [b]},
180 outputs={'Out': [tmp]})
181 return tmp
182
183 def append_activation(self, input_var):
184 act = self.kwargs.get('act', None)
185 if act is None:
186 return input_var
187 if isinstance(act, basestring):
188 act = {'type': act}
189 tmp = self.create_tmp_variable(dtype=input_var.data_type)
190 act_type = act.pop('type')
191 self.append_op(
192 type=act_type,
193 inputs={"X": [input_var]},
194 outputs={"Y": [tmp]},
195 attrs=act)
196 return tmp
详细的源码细节我们下一节会讲这里指写一下实现的方式和调用的函数。
作者:Charlotte77


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南