

机器学习笔记(三)---- 逻辑回归(二分类)
逻辑回归基本概念
前面提到过线性模型也可以用来做分类任务,但线性模型的预测输出 y = wx + b 可能是(-∞,+∞)范围内的任意实数,而二分类任务的输出y={0,1},如何在这之间做转换呢?答案就是找一个单调可微函数将分类任务输出y和线性回归模型联系起来,对数几率函数(Sigmoid函数)可以很好地胜任这个工作,函数图形如下,预测值z大于零判为正例,z小于零判为负例,z等于零处在临界值可任意判别。
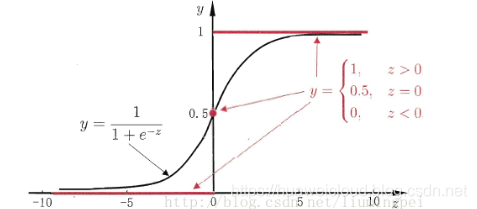
将对数几率函数作为判别函数代入线性回归模型中,就得到逻辑回归的模型如下,x不管怎么变化,预测输出y总是在[0,1]范围内,实际上给出的是y=1的概率,这样通过对数几率函数就将线性回归模型的预测输出从(-∞,+∞)压缩到[0,1],符合二分类问题的预测输出,所以逻辑回归也叫做对数几率回归,虽然名称上有“回归”二字,但实际上是分类模型。
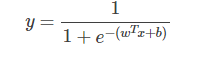
逻辑回归代价函数
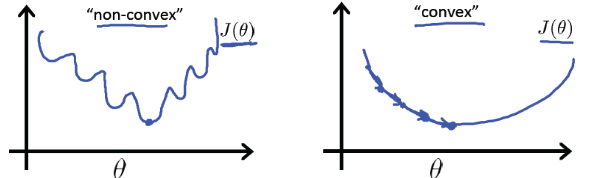
机器学习模型的代价函数要求是凸函数,左下图就是非凸函数,存在多个局部最小值,不利于求解全局最小值。而右下图则是凸函数的图形,可以保证局部最小点就是全局最小点,利用梯度下降算法可以很快地找到最小值。
这里略掉代价函数的推导过程,直接给出逻辑回归的代价函数:
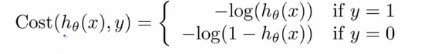
分析下这个函数,h(x)是预测输出(输出范围[0,1]),y为真实分类,代价函数也称为损失函数(loss funciton),预测和真实分类越吻合,代价函数越小,反之,代价函数越大。
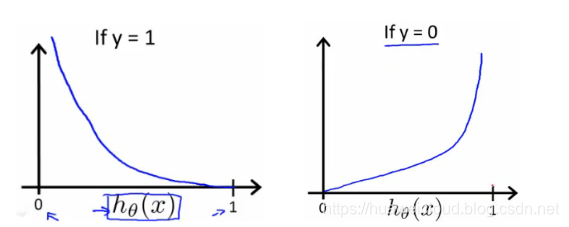
(1)y = 1时,Cost(h(x), y) = -log(h(x)),函数图形如左下图,h(x)的值趋近于1时,Cost趋近于0,说明预测和真实分类趋于一致,代价函数越小;h(x)趋近于0,说明预测和真实分类相反,则Cost越来越大。
(2)y =0时,Cost(h(x), y) = -log(1-h(x)),函数图形如右下图,h(x)的值趋近于1时,Cost趋近于无穷大,说明预测和真实分类相反;h(x)趋近于0时,预测和真实分类趋于一致,Cost的值趋近于0。
逻辑回归特点
- 模型简单,易于理解和实现,计算复杂度低;
- 直接对分类可能性进行建模,无需事先假设数据分布,避免假设分布不准确带来的问题;
- 不仅可以预测分类,还可以得到近似概率,对于辅助决策很有用;
- 广泛应用于工业问题上,如垃圾邮件分类等;
- 当特征属性很多,而数据量较小时,性能不太好;
逻辑回归练习
sklearn中自带有breast数据集,是一组关于威斯康辛州的乳腺癌诊断数据库,共有569条数据,30个属性特征,分类输出为两类(良性、恶性),是一个可以用来做逻辑回归的简单例子。随机抽取十分之一的数据作为测试数据集,剩下的作为训练数据。
import pandas as pd
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn import preprocessing
breast_data = datasets.load_breast_cancer()
data = pd.DataFrame(datasets.load_breast_cancer().data)
data.columns = breast_data['feature_names']
data_np = breast_data['data']
target_np = breast_data['target']
train_X,test_X, train_y, test_y = train_test_split(data_np,target_np,test_size = 0.1,random_state = 0)
model = LogisticRegression(C=1.0, tol=1e-6)
model.fit(train_X, train_y)
y_pred = model.predict(test_X)
print(accuracy_score(test_y, y_pred))
-----------------------------------------
0.9649122807017544上面是直接将原始数据直接灌入模型,细心的读者可能会问,各维度数据的量纲、取值区间差异这么大,有的特征属性数据取值都在1000以上,而有的特征属性取值却小于1,这样直接输入模型可以么?其实在训练前,还应该对数据进行标准化。数据标准化主要是将各维度数据按比例进行缩放,使之落入一个特定的区间内,同时去除数据的单位限制,转为为无量纲数据,便于不同单位或量级的特征能够进行加权和比较。
归一化是一种最常用的数据标准化方法,将数值变为[0,1]之间的小数,方法是将每个特征属性(列)的数据减去均值,并除以方差。对于每个特征属性来说,所有数据都聚集在[0,1]范围内,方差为1。sklearn中数据归一化可以使用 preprocessing.scale(X),在本例中,数据归一化后预测结果正确率可达100%。
作者:华为云专家周捷


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南