

机器学习笔记(十)---- KNN(K Nearst Neighbor)
KNN是一种常见的监督学习算法,工作机制很好理解:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。总结一句话就是“近朱者赤,近墨者黑”。
KNN可用作分类也可用于回归,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为测试结果;在回归任务中可使用“平均法”将这k个样本的标记平均值作为预测结果;还可以基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
KNN和之前介绍的监督学习算法有一个很大的不同,它没有前期的训练过程,是一种“懒惰学习”的算法,只有收到测试样本后,再和训练样本进行比较处理。
初学者容易把KNN和K-means搞混淆,虽然都有K,:-)但这是两种不同的算法,二者区别如下:
| KNN | K-Means | |
| 不同点 | 是一种分类算法,属于监督学习的范畴,训练数据是带有label的 | 是一种聚类算法,属于非监督学习的范畴,训练数据没有label,杂乱无章的 |
| 没有明显的训练过程,属于lazy learning | 有明确的训练过程 | |
| K的含义:与预测样本距离最近的K个样本 | K的含义:K是事前人工定好的参数,假设数据集可分为K个簇 | |
| 相同点 | 都用到了NN(nearst Neighbor)算法,一般用KD树来实现。 | |
--KNN算法基本原理
KNN算法简单的步骤如下:
(1)计算距离:给定测试对象,计算它与训练集中每个对象的距离,空间距离的计算方法有多种,有欧式距离、夹角余弦(多在文本分类中使用)等。
(2)找邻居:圈定距离最近的k个对象,作为测试对象的近邻。
(3)做分类:根据这k个近邻归属的主要类别,对测试对象进行分类。
下面通过一个简单的示例说明下KNN算法是怎么进行分类的:
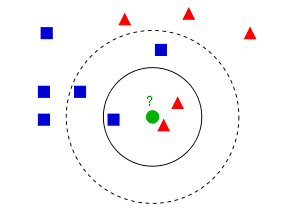
上图的蓝色方块和红色三角是已经打好label的数据,绿色圆圈是待分类的测试数据。
如果我们让K=3,那么上图实心圆圈中的两个三角和一个方块就是离测试数据最近的3个点,那么通过投票法则,测试数据会被分类为红色三角;
如果我们让K=5,那么上图虚线圆圈中的两个三角和三个方块就是离测试数据最近的5个点,通过投票法则,测试数据则会被分类为蓝色方块;
整个算法的原理是不是很简单?但实际上并没有那么简单,K如何选择?数据之间的距离怎么计算?
--K值的选择
如果K值太小,整体模型会变得复杂,容易发生过拟合,容易将一些噪声学习进来,二忽略数据的真实分布。
如果K值过大,模型会变得相对简单,可以减少学习的估计误差,但近似误差会变大,比如极端情况下K=N(N维训练样本数),则不论预测对象是什么,预测结果都将是训练集中最多的类型,这显然是一个过渡简化的模型,无法实际应用。
k值一般采用交叉验证或者Grid Search的方法确定。
--距离计算
提取数据的特征值,根据特征值组成一个n维实数向量空间(特征空间),然后计算向量之间的空间距离,如欧式距离、余弦相似度等。
对于数据![]() 和
和![]() ,其特征空间为n维实数向量空间:
,其特征空间为n维实数向量空间:![]() ,
,![]()
欧式距离计算公式为: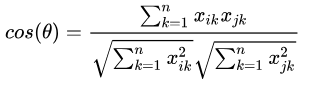
余弦相似度计算公式为: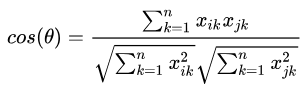
余弦相似度的值越接近1表示其越相似,接近0表示其差异越大。余弦相似度更多应用在文本类任务中。
--代码示例
依旧以sklearn中的cancer数据集为例,做一个通过30维特征判断是否患癌症的示例,示例中数据量很少,只有569条数据,每条数据各有30个特征数值。采用sklearn中的KNN分类器,除k外都采用默认参数,距离度量采用欧式距离 。通过交叉验证法来确定最佳的K值,从下图可见,K=14时,验证准确率最高。

__author__ = 'z00421185'
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
breast_data = datasets.load_breast_cancer()
data = pd.DataFrame(datasets.load_breast_cancer().data)
data.columns = breast_data['feature_names']
data_np = breast_data['data']
target_np = breast_data['target']
print(data_np.shape)
x_train, x_test, y_train, y_test = train_test_split(data_np, target_np, test_size=0.3, random_state=0)
# 设定交叉验证k的范围,一般从1~样本数的开方
k_range = range(1, 24)
scores = []
for k in k_range:
knn = KNeighborsClassifier(k, metric='euclidean')
score = cross_val_score(knn, x_train, y_train, cv=10, scoring='accuracy')
scores.append(score.mean())
# 从折线图上看最佳K取值
plt.plot(k_range, scores)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()
model = KNeighborsClassifier(n_neighbors=13)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
---------------------------------
0.9649122807017544作者:华为云专家 周捷


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南