

http://deeplearning.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95
反向传播算法的思路如下:给定一个样例 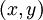 ,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括
,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括 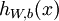 的输出值。之后,针对第
的输出值。之后,针对第  层的每一个节点
层的每一个节点  ,我们计算出其“残差”
,我们计算出其“残差” 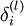 ,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为 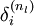 (第
(第 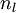 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第
层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 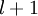 层节点)残差的加权平均值计算 ,这些节点以
层节点)残差的加权平均值计算 ,这些节点以 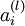 作为输入。
作为输入。
$ \delta 3=\frac{d Error}{d x_3}=frac{d 1/2*(t-y_3)^2}{d x} =-(t-y_3)*y_{3}^{'} $
$ \delta 2=\frac{d Error}{d x_2}=\frac{d E}{d x_3} \frac{d x_3}{d y_2} \frac{d y_2}{d x_2}= \delta 3*w2*y_{2}^{'} $
计算我们需要的偏导数,计算方法如下:
($a^(l)_j$是activation, j是前一层,i是后一层)
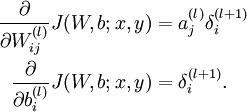

是sum上面一层,而forward是sum下面一层。

若不是sigmoid,则$\Delta wi=exi$
还有一个问题,当f(x)接近1或接近0时,gradient非常小,几乎为0,这时没法更新weight,错误无法修正

tj只有当是结果是才为1,其余时候为0.
