Yolov4输入端创新
考虑到很多同学GPU显卡数量并不是很多,Yolov4对训练时的输入端进行改进,使得训练在单张GPU上也能有不错的成绩。比如数据增强Mosaic、cmBN、SAT自对抗训练。
但感觉cmBN和SAT影响并不是很大,所以这里主要讲解Mosaic数据增强。
(1)Mosaic数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。

这里首先要了解为什么要进行Mosaic数据增强呢?
在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。
首先看下小、中、大目标的定义:
2019年发布的论文《Augmentation for small object detection》对此进行了区分:
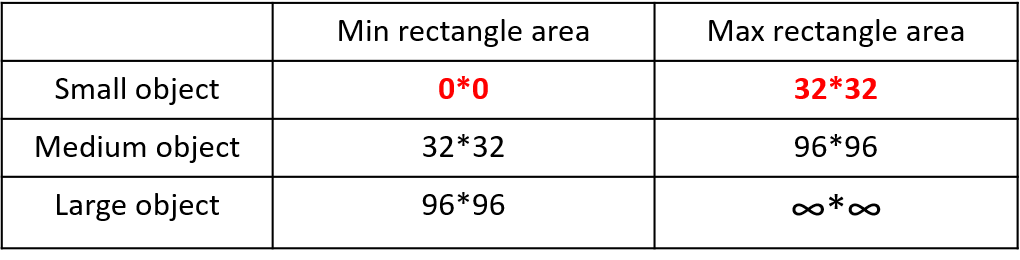
可以看到小目标的定义是目标框的长宽0×0~32×32之间的物体。
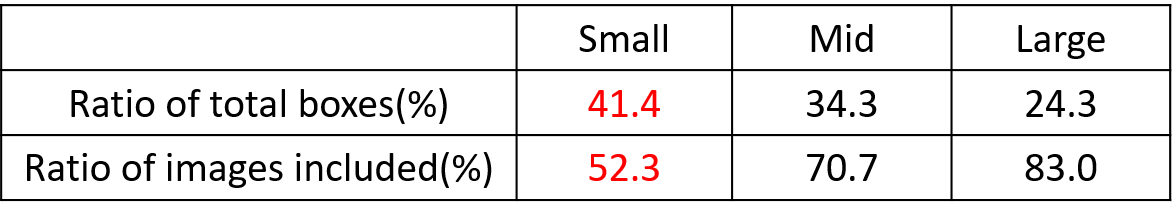
但在整体的数据集中,小、中、大目标的占比并不均衡。
如上表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。
但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。
主要有几个优点:
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
此外,发现另一研究者的训练方式也值得借鉴,采用的数据增强和Mosaic比较类似,也是使用4张图片(不是随机分布),但训练计算loss时,采用“缺啥补啥”的思路:
如果上一个iteration中,小物体产生的loss不足(比如小于某一个阈值),则下一个iteration就用拼接图;否则就用正常图片训练,也很有意思。
参考链接:https://www.zhihu.com/question/3901

 浙公网安备 33010602011771号
浙公网安备 33010602011771号