BERT 对句子进行分类
介绍如何使用不同的 BERT 对句子进行分类。本文中的例子深入浅出,也足以展示 BERT 使用过程中所涉及的关键概念。
除了这篇博文,我还准备了一份对应的 notebook 代码,链接如下:
你也可以在 colab 中运行这份代码:
数据集:SST2
本文示例中使用的数据集为「SST2」,该数据集收集了一些影评中的句子,每个句子都有标注,好评被标注为 1,差评标注为 0。
sentencelabela stirring , funny and finally transporting re imagining of beauty and the beast and 1930s horror films1apparently reassembled from the cutting room floor of any given daytime soap0they presume their audience won't sit still for a sociology lesson0this is a visually stunning rumination on love , memory , history and the war between art and commerce1jonathan parker 's bartleby should have been the be all end all of the modern office anomie films1
模型:句子情感分类
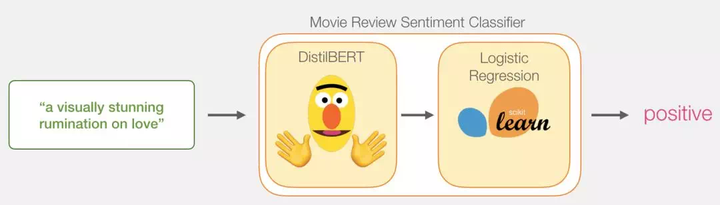
我们的目标是创建一个分类器,它的输入是一句话(即类似于数据集中的句子),并输出一个 1(表示这句话体现出了积极的情感)或是 0(表示这句话体现出了消极的情感)。整体的框架如下图所示:

实际上,整个模型由两个子模型组成:
- DistilBERT 先对句子进行处理,并将它提取到的信息传给下个模型。DistilBERT 是 BERT 的缩小版,它是由 HuggingFace 的一个团队开发并开源的。它是一种更轻量级并且运行速度更快的模型,同时基本达到了 BERT 原有的性能。
- 另外一个模型,是 scikit learn 中的 Logistic 回归模型,它会接收 DistilBERT 处理后的结果,并将句子分类为积极或消极(0 或 1)。
我们在两个模型之间传递的数据是 768 维的向量。我们可以把这个向量看做能够用于分类任务的句子嵌入。
如果你读过我以前写的关于 Iluustrated BERT 的文章(https://jalammar.github.io/illustrated-bert/),这个向量其实就是以词 [CLS] 为输入的第一个位置上的结果。
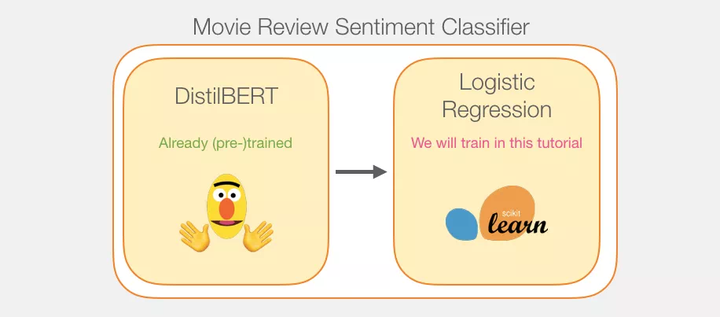
模型训练
尽管整个模型包含了两个子模型,但是我们只需要训练 logistic 回归模型。至于 DistillBERT,我们会直接使用已经在英文上预训练好的模型。然而,这个模型不需要被训练,也不需要微调,就可以进行句子分类。BERT 训练时的一般目标让我们已经有一定的句子分类能力了,尤其是 BERT 对于第一个位置的输出(也就是与 [CLS] 对应的输出)。我觉得这主要得益于 BERT 的第二个训练目标——次句预测(Next sentence classification)。该目标似乎使得它第一个位置的输出封装了句子级的信息。Transformers 库给我们提供了 DistilBERT 的一种实现以及预训练好的模型。
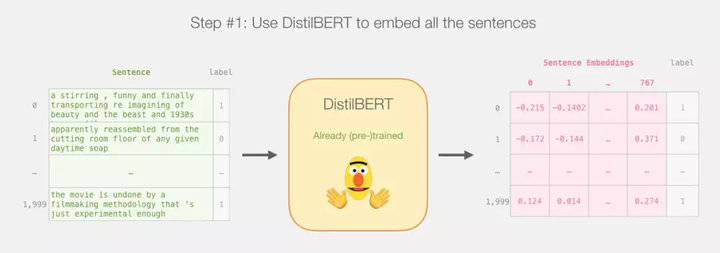
教程概览
这篇教程的计划如下:我们首先用预训练好的 distilBERT 来生成 2,000 个句子的嵌入。
后面我们就不会再涉及 distilBERT 了。剩下的都是 Scikit Learn 的工作了,我们接下来要做的就是将数据集分成训练集和测试集。
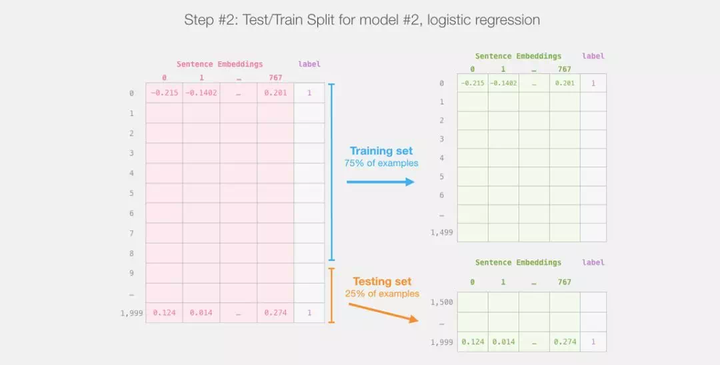
将 distilBert(模型 #1)的输出划分为训练集和测试集后,就得到了我们训练和评估 logistic 回归(模型 #2)的数据集了。请注意,在现实中,sklearn 在将数据划分为训练集和测试集之前,会将样本打乱,而不是直接按照数据原来的顺序取前 75%。
接下来,我们要在训练集上训练逻辑 logistic 回归模型了:
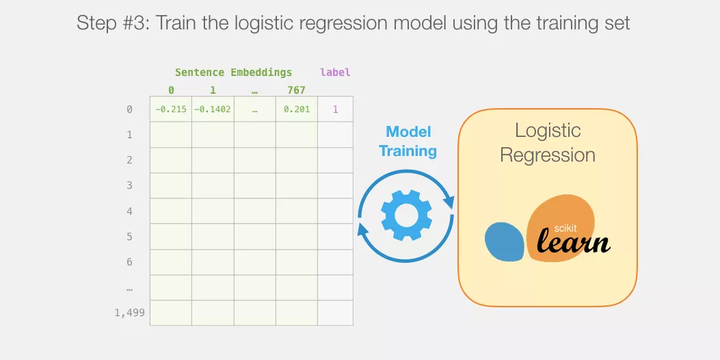
每个预测值是怎么计算出来的?
在我们深入研究训练模型的代码前,让我们先看一下训练好的模型是如何计算出其预测值的。假设我们正在对句子「a visually stunning rumination on love」进行分类。第一步要做的就是用 BERT 分词器(tokenizer)将这些单词(word)划分成词(token)。然后,我们再加入句子分类所需的特殊词(在句子开始加入 [CLS],末端加入 [SEP])。

分词器要做的第三步就是查表,将这些词(token)替换为嵌入表中对应的编号,我们可以从预训练模型中得到这张嵌入表。如果对词嵌入不太了解,请参阅「The Illustrated Word2vec」:
https://jalammar.github.io/illustrated-word2vec/。

注意,只需要一行代码就可以完成分词器的所有工作:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)现在,我们输入的句子是可以传递给 DistilBERT 的形式。
如果你读过「Illustrated BERT」(https://jalammar.github.io/illustrated-bert/),这一步也可以被可视化为下图:
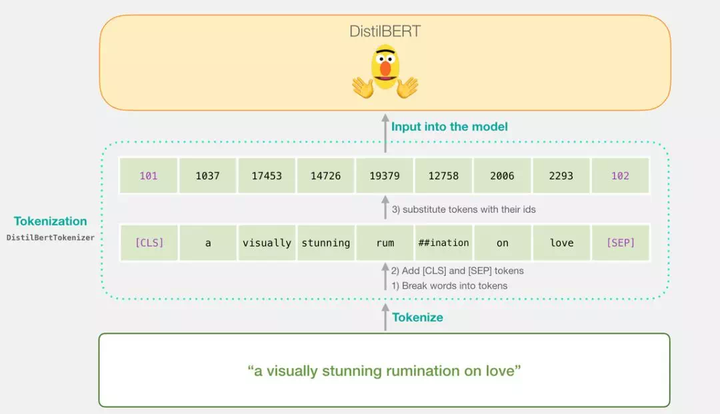
DistilBERT 的数据流
将输入向量传递给 DistilBert 之后的工作方式就跟在 BERT 中一样,每个输入的词都会得到一个由 768 个浮点数组成的输出向量。
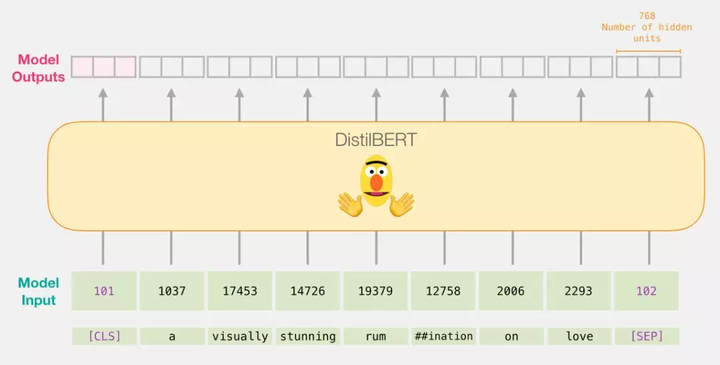
由于这是个句子分类任务,我们只关心第一个向量(与 [CLS] 对应的向量)。
该向量就是我们输入给 logistic 回归模型的向量。
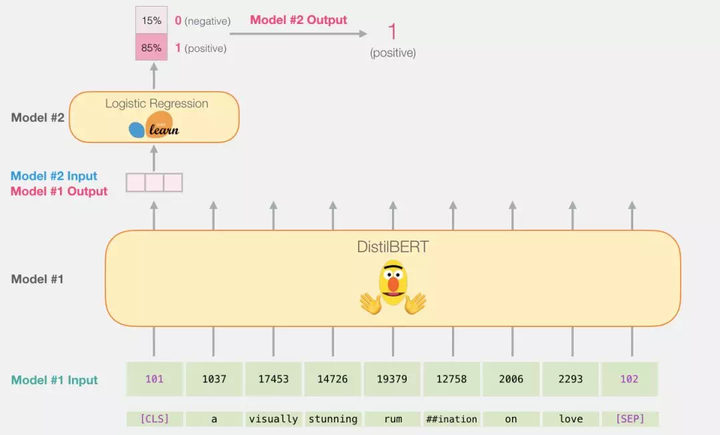
从这一步开始,logistic 回归模型的任务就是:根据它在训练阶段学到的经验,对这个向量进行分类。我们可以把整个预测过程想象成这样:
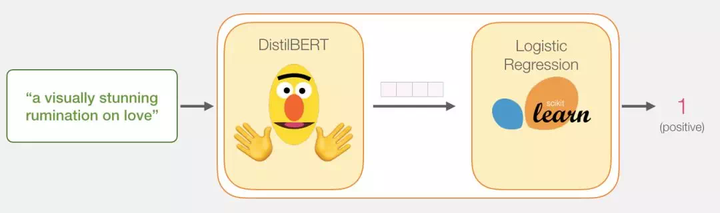
我们将在下一节中讨论整个训练过程及其相关代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号