大数据预处理案例——600w+条短租房数据案例分析
1.1 数据集
本案例中的数据来自于爱彼迎(Airbnb)网站2018-2019年度的多伦多市的真实数据。
数据集中包含listings数据集,约有2万条数据,记录着所有的房屋信息,包括价格在内的几十项信息字段。
数据集中的另一个数据集是calendar,包含约650万条的租房交易数据,拥有每一天每一所住房的入驻信息。
1.2 数据分析思路梳理
常规数据分析,数据字段载入和常见数据ETL四板斧的清洗处理
方法1: .isnull().sum() 检查空值情况
方法2: .shape 检查数据尺寸
方法3: .describe() 查看数据字段数据类型
方法4: .value_counts() 查看数据集合数据分布情况
数据分析师最终是要把结果以可视化的方式进行呈现,所以对于分析得到的数据要进行图表化展示。由于本案例主要研究的目标是价格的依赖因素,所以我们采用价格和另一个因素的对比作图来观察。常见图形包括:
图形1: 柱状图,来观察数据的分布情况
图形2: 箱型图,来观察数据的范围
图形3: 散点矩阵图,来观察不同因素间的相互联系
图形4: 热力图,来快速筛选出高关联度的信息因素
传统的数据分析一般就会到此为止,但是对于探索试数据分析来说,事情才刚刚开始,为了更深入的进行数据分析,本案例开始引入机器学习模型,由于机器学习模型本质上就是数学模型,所以我们需要对数据集合进行特征工程,把数据集合变为方便模型识别的数组,本例中采用如下几个步骤:
步骤1:数据的标准化
步骤2:缺失数据的修复
步骤3:字符串类数据的编码化
步骤4:数据类型转换和单位统一
对于本例中的众多字段用简单的线性回归等模型已经不能很好的捕捉出数据的动态,所以我们采用一些符合机器学习模型,也就是利用一系列若关联的特性组合出强特性的模型,在本例中我们采用两个模型:
模型1 :随机森林模型,这个模型是一个复合模型,对特征和标签进行任意排列组合,然后通过概率方式进行建模,最大程度的降低过拟合的出现。
模型2 :微软的LightGBM模型也是最近几年非常火的复合模型,在本例中我们使用这个模型和随机森林进行模型对比,利用R2值来选出最合适的机器学习模型。
2 数据分析
2.1 数据加载
代码编写是在Anaconda集成环境下的jupyter notebook上进行,首先导入数据分析所需要的模块以及数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
calendar = pd.read_csv('toroto/calendar.csv.gz')
print('We have', calendar.date.nunique(), 'days and', calendar.listing_id.nunique(), 'unique listings in the calendar data.')
输出结果如下:(数据包含了365天共17333份房间信息,nunique()方法是进行字段的唯一值查询,返回字段中唯一元素的个数)

2.2 数据查看
(1)数据维度和字段信息
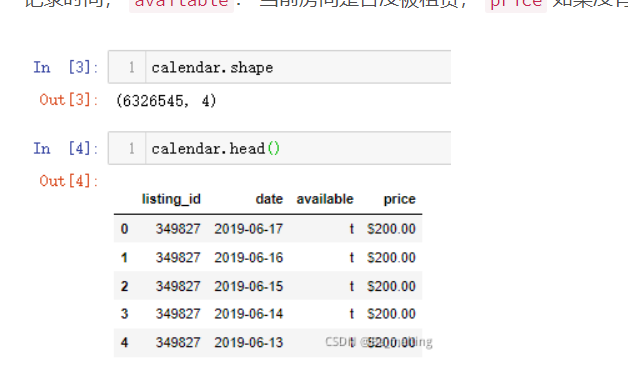
calendar.shape calendar.head()
输出结果如下:(共有630w+条交易记录,4个字段。listing_id: 房屋数据编号, date: 当前记录时间, available: 当前房间是否没被租赁, price 如果没有被租赁,则显示价格)
交易的起止日期
calendar.date.min(), calendar.date.max()
输出结果如下:(交易的时间范围是在2018年10月6号至2019年10月5号,整整一年的时间
calendar.isnull().sum() calendar.available.value_counts()
输出结果如下:(price字段,由于房子出租后,就没有价格显示,只有未出租才有价格,所以该字段存在着缺失值;available字段中f (false) 代表已经被租用 , t(true) 代表可以被出租)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号