大数据预处理--特征工程
以上的内容就是传统的数据分析要完成的内容,分析的过程依赖于数据分析师本身的经验,而且结果都是以图表的形式进行展现,有一个痛点就是字段较多时候,要进行分析时就需要很多很多的图像,比如三个字段的分析,热力图就需要很多很多。此时就可以借助机器学习模型来探究,但是探究之前需要处理字段数据,进行特征工程。为了防止内存不足,建议在进行特征工程之前重新restart一下kernel,保证后续程序的正常运行,否则会提醒内存不足,程序报错
import pandas as pd
listings = pd.read_csv('toroto/listings.csv/listings.csv')
listings['price'] = listings['price'].str.replace(',', '')
listings['price'] = listings['price'].str.replace('$', '')
listings['price'] = listings['price'].astype(float)
listings = listings.loc[(listings.price <= 600) & (listings.price > 0)]
listings.amenities = listings.amenities.str.replace("[{}]", "").str.replace('"', "")
listings.amenities.head()
输出结果如下:(数据读取之后将价格字段和设施字段还按照之前的处理方式进行预处理,注意这里程序运行后的标号,是restart之后的再次运行)
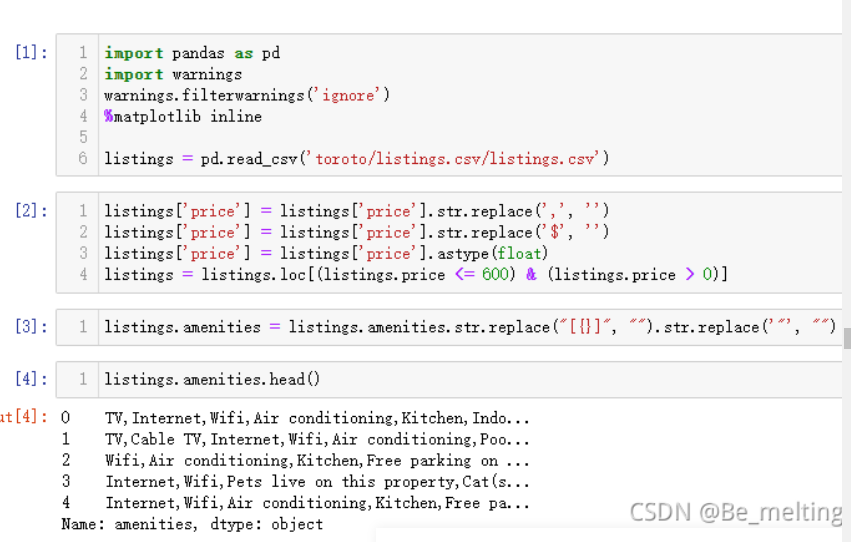
然后进行特征工程,先处理文本数据,将文本数据特征化,导入处理文本数据的模块,进行词向量转化
from sklearn.feature_extraction.text import CountVectorizer
count_vectorizer = CountVectorizer(tokenizer=lambda x: x.split(','))
amenities = count_vectorizer.fit_transform(listings['amenities'])
df_amenities = pd.DataFrame(amenities.toarray(), columns=count_vectorizer.get_feature_names())
df_amenities = df_amenities.drop('',1)
输出结果如下:(这一过程就是将amenities字段中所有的分类进行独热编码,然后形成DataFrame数据类型)
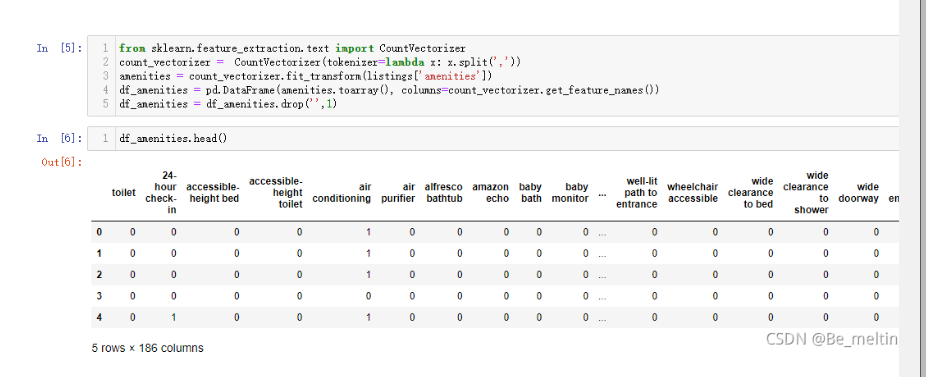
接着处理二分类字段,将true和false的分类替换成计算机识别的1和0分类。当存在多个二分类字段时候可以进行for循环统一进行数据转化,代码操作如下
columns = ['host_is_superhost', 'host_identity_verified', 'host_has_profile_pic',
'is_location_exact', 'requires_license', 'instant_bookable',
'require_guest_profile_picture', 'require_guest_phone_verification']
for c in columns:
listings[c] = listings[c].replace('f',0,regex=True)
listings[c] = listings[c].replace('t',1,regex=True)
接着对价钱相关的字段进行缺失值填充和噪音数据的清洗,最后不要忘记将数值的字段转化为浮点数。代码操作如下
listings['security_deposit'] = listings['security_deposit'].fillna(value=0) listings['security_deposit'] = listings['security_deposit'].replace( '[\$,)]','', regex=True ).astype(float) listings['cleaning_fee'] = listings['cleaning_fee'].fillna(value=0) listings['cleaning_fee'] = listings['cleaning_fee'].replace( '[\$,)]','', regex=True ).astype(float)
并不是读取数据中的所有字段都有作用,比如在进行热力图判断字段之间的相关关系时,有些字段之间的相关关系的都是0,这些字段就可以直接被舍弃,选取有相关关系的字段重新组成一个数据集
listings_new = listings[['host_is_superhost', 'host_identity_verified', 'host_has_profile_pic','is_location_exact',
'requires_license', 'instant_bookable', 'require_guest_profile_picture',
'require_guest_phone_verification', 'security_deposit', 'cleaning_fee',
'host_listings_count', 'host_total_listings_count', 'minimum_nights',
'bathrooms', 'bedrooms', 'guests_included', 'number_of_reviews','review_scores_rating', 'price']]
接着就看一下这些字段中是不是还存在缺失值,上面只是进行了部分字段的处理,这里重现选取字段后仍然要进行缺失值的处理
for col in listings_new.columns[listings_new.isnull().any()]:
print(col)
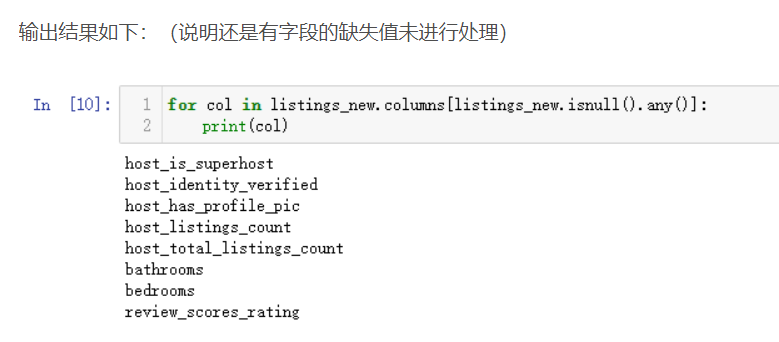
接着处理这部分字段的缺失值,按照中位数进行填充。当字段为分类字段时,填充的方式为中位数填充,前面处理的价格字段为连续字段,使用均值进行填充
for col in listings_new.columns[listings_new.isnull().any()]:
listings_new[col] = listings_new[col].fillna(listings_new[col].median())
然后对分类字段进行独热编码处理,并将编码后的结果与新数据进行合并
for cat_feature in ['zipcode', 'property_type', 'room_type', 'cancellation_policy', 'neighbourhood_cleansed', 'bed_type']:
listings_new = pd.concat([listings_new, pd.get_dummies(listings[cat_feature])], axis=1)
此时不要忘记最开始对文本编码的DataFrame数据,也需要进行合并,合并的方式为取交集,最终得到特征工程处理后的数据
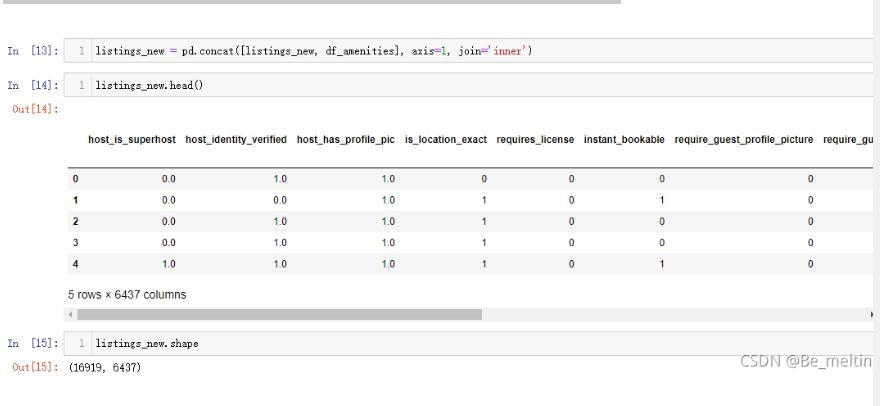
listings_new = pd.concat([listings_new, df_amenities], axis=1, join='inner') listings_new.head() listings_new.shape
输出结果如下:(数据只剩下约1.7w,但是字段数量增加到了6000+)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号