
Day05
一、数据类型的划分:
python中的数据类型划分为:
可变的数据类型: list , 字典,set(集合)
不可变的数据类型:元组 , int ,bool ,str (字符串是不可变的类型,因为对字符串的修改是创建了一个新的字符串,而不是在原有的字符串的基础上进行改变) 可哈希
二:字典简介
字典有键值对(键和值)组成,和数据库中的主键有些类似,一个键对应的一个值。
键:因为一个键确定值,所以键是不能改变的数据类型 (int ,bool ,str,元组) 都可以作为键的类型
值:字典的值可以是任何类型
优点:字典是无序的,但是字典中的键是有序排列的。而且,字典在查找的时候,在键中优先采用二分法进行查找,所以字典的查找速率很快。
特点:字典的存储是无序的,有点分布式数据库的意思。
三:字典的创建
字典的格式:一般用大括号括起来,键于值之间用冒号连接
1 dic = { 2 键1 :值1, 3 键2 : 值2, 4 }
代码演示:
1 dic = { 2 "name":["huao","zhao"], 3 '计科':[{"name":"胡澳",'age':18}, 4 {"name":"胡澳",'age':19} 5 ], 6 True:1, 7 (1,2,3):"胡澳", 8 2:"二哥" 9 } 10 print(dic)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py {'name': ['huao', 'zhao'], '计科': [{'name': '胡澳', 'age': 18}, {'name': '胡澳', 'age': 19}], True: 1, (1, 2, 3): '胡澳', 2: '二哥'} 进程已结束,退出代码0
解析:字典的创建中,键用了(str, bool,tuple,int )等一系列的不可变的数据类型
而值得创建则是用了不同得数据类型,任意得数据类型都可以。
四、字典的增删改查
增:
代码演示:
dic = {"name":"胡澳","age":20,"班级":"17级计科六班"}
dic["weigth"] = 120 #如果这个键值对没有的话,会直接添加到字典里面
dic["age"] = 19 #有这个键值对会直接覆盖掉原来的值
'''
def setdefault(self, *args, **kwargs): # real signature unknown
"""
Insert key with a value of default if key is not in the dictionary.
Return the value for key if key is in the dictionary, else default.
"""
pass
如果键不在字典中,则使用默认值进行插入。
如果键在字典中,则返回键的值,否则直接插入默认值
'''
dic.setdefault('weight') #字典中有weight这个键,但是没有指定值,所以直接用默认值添加(默认值就是None)
dic.setdefault("name","赵润全")
print(dic)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py {'name': '胡澳', 'age': 19, '班级': '17级计科六班', 'weigth': 120, 'weight': None} 进程已结束,退出代码0
分析:字典中的增加的方法大致上和列表差不多。
删:
pop(有键,删除并返回删除值。没键,报错):
代码演示:
1 dic = {"name":"胡澳","age":20,"班级":"17级计科六班"} 2 ''' 3 def pop(self, k, d=None): # real signature unknown; restored from __doc__ 4 """ 5 D.pop(k[,d]) -> v, remove specified key and return the corresponding value. 6 If key is not found, d is returned if given, otherwise KeyError is raised 7 """ 8 pass 9 找到了就删除并返回被删除的值。没有找到就报错 10 ''' 11 dic1 = dic.pop('name') # pop有返回值。返回的是被删除的键所对应的值。 12 dic2 = dic.pop('weight') #没有找到就报错了 13 print(dic1)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py Traceback (most recent call last): File "D:/学习资料/项目/练习/lianxi.py", line 11, in <module> dic2 = dic.pop('weight') KeyError: 'weight' 进程已结束,退出代码1
popitem(随机删除并返回键和值组成的元组,没找到键就进行报错):
代码演示:
1 dic = {"name":"胡澳","age":20,"班级":"17级计科六班"} 2 dic.setdefault("weight",60) 3 ''' 4 def popitem(self): # real signature unknown; restored from __doc__ 5 """ 6 D.popitem() -> (k, v), remove and return some (key, value) pair as a 7 2-tuple; but raise KeyError if D is empty. 8 """ 9 pass 10 删除并且返回被删除的键和值。返回的是一个元组,里面包含键值对。 11 如果没有找到键,则会报错。 12 ''' 13 print(dic) 14 dic1 = dic.popitem() #随机删除(说着是随机删除,但实际上是删除最后一个) 15 print(dic) 16 print(dic1)
运行截图:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py {'name': '胡澳', 'age': 20, '班级': '17级计科六班', 'weight': 60} {'name': '胡澳', 'age': 20, '班级': '17级计科六班'} ('weight', 60) 进程已结束,退出代码0
del:
代码演示:
dic = {"name":"胡澳","age":20,"班级":"17级计科六班"}
del dic["name"]
print(dic)
del dic
print(dic)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py Traceback (most recent call last): File "D:/学习资料/项目/练习/lianxi.py", line 5, in <module> print(dic) {'age': 20, '班级': '17级计科六班'} NameError: name 'dic' is not defined 进程已结束,退出代码1
代码分析:del删除和在列表中的一样。在字典中的删除的时候,直接删除键就行,因为键是对应的映射到值上面的。
clear(直接就是清空字典):
代码演示:
dic = {"name":"胡澳","age":20,"班级":"17级计科六班"}
dic.clear()
print(dic)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py
{}
进程已结束,退出代码0
代码分析:运用clear进行删除的时候,完全删除后并不会直接进行报错,而是返回一个空的字符串。
改:
update(将dic1中的值更新到dic中,没有键的添加,有相同的键的进行覆盖):
代码演示:
dic = {"name":"胡澳","age":20,"班级":"17级计科六班"}
dic1 = {"name":"赵润全","weight":20}
dic.update(dic1)
print(dic)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py {'name': '赵润全', 'age': 20, '班级': '17级计科六班', 'weight': 20} 进程已结束,退出代码0
代码分析:dic1中有和dic中一样的键name,所以更新后就会覆盖dic中的值(胡澳)成为(赵润全)。dic中没有的键值对weight就直接添加到dic中。
查:
先介绍一下字典的常规查询。
代码演示:
1 dic = {"name":"胡澳","age":20,"班级":"17级计科六班"} 2 print(dic.keys(),type(dic.keys())) 3 print(dic.values(),type(dic.values())) 4 print(dic.items(),type(dic.items())) 5 6 for i in dic: 7 print(i)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py dict_keys(['name', 'age', '班级']) <class 'dict_keys'> dict_values(['胡澳', 20, '17级计科六班']) <class 'dict_values'> dict_items([('name', '胡澳'), ('age', 20), ('班级', '17级计科六班')]) <class 'dict_items'> name age 班级 进程已结束,退出代码0
代码分析:可以看出,字典中的键和值都是独立类型的存在。用for去遍历字典的时候,打印的是字典的键。字典的键和值打印出来也是列表,使用方法和列表一样。
交换赋值(a,b = b,a):
代码演示:
a = 10 b = 20 a,b = b,a print(a,b)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py 20 10 进程已结束,退出代码0
代码分析:在别的语言中交换两个变量的值得用三个变量,需要有一个中间变量进行过度。但是在python中直接交换就行。
因为在python中的存储如图:
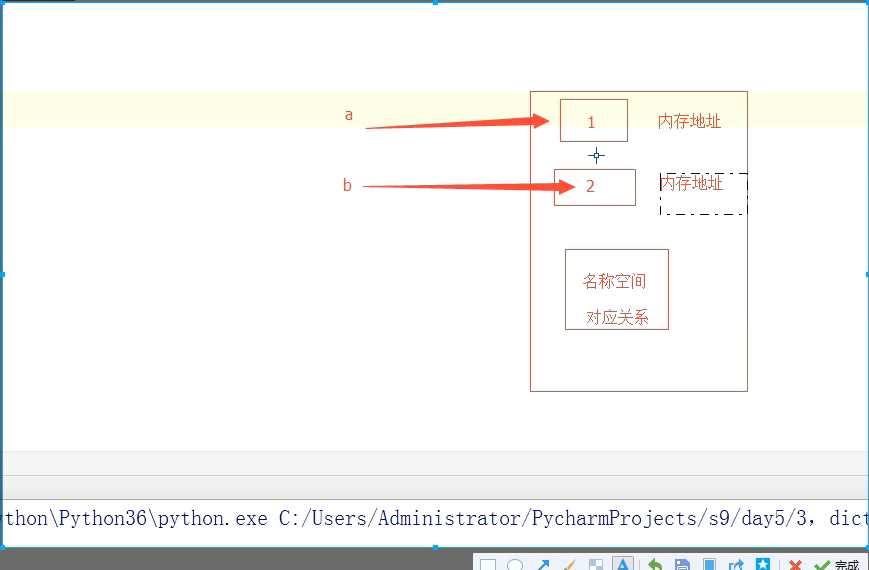
除了存储了每个变量的内存地址以外。还存储了变量的对应关系。所以在交换的时候,直接将变量的对应关系进行交换,然后在根据名字再去找对应的内存地址,就可以交换。实质上内存地址并没有变化,只是对应关系发生了变化。
而在python中这一交换的特性被放大:
代码演示:
a,b = [1,2,3],[4,5,6] print(a) print(b) a,b = (2,3) print(a) print(b)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py 20 10 [1, 2, 3] [4, 5, 6] 2 3 进程已结束,退出代码0
代码分析:可以看出,a,b两边都可以进行配对,只要是对应的,左边变量数量和右边的相等就行。
分别打印键和值:
代码演示:
dict = {"name":"胡澳","age":10,"班级":"计算机与技术专业"}
for k,v in dict.items():
print(k,v)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py name 胡澳 age 10 班级 计算机与技术专业 进程已结束,退出代码0
通过键值直接查询:
代码演示:
dict = {"name":"胡澳","age":10,"班级":"计算机与技术专业"}
a = dict["name"]
print(a)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py
胡澳
进程已结束,退出代码0
但是没有找到键值的话就会报错。
dict = {"name":"胡澳","age":10,"班级":"计算机与技术专业"}
a = dict["weight"]
print(a)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py Traceback (most recent call last): File "D:/学习资料/项目/练习/lianxi.py", line 2, in <module> a = dict["weight"] KeyError: 'weight' 进程已结束,退出代码1
Get :get的出现缓解了报错的现象
代码演示:
dict = {"name":"胡澳","age":10,"班级":"计算机与技术专业"}
'''
def get(self, *args, **kwargs): # real signature unknown
""" Return the value for key if key is in the dictionary, else default. """
pass
如果找到了键就返回值,如果没有就返回默认值
'''
a1 = dict.get("name")
print(a1)
a2 = dict.get("weight")
print(a2)
a3 = dict.get("weight","没有这个键")
print(a3)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py
胡澳
None
没有这个键
进程已结束,退出代码0
代码分析:可以看出get的返回值是None,也可以字节在后面设一个返回的默认值。这就比较好的解决了报错的问题。因为你有时也不知道,拿过来的数据有没有这个键。
五、字典的嵌套:
字典的嵌套和列表的嵌套一样,找准当前是在哪一个层次上面,出来的是列表还是字典,运用相关的方法进行操作就行。
代码演示:
dict = { "name":["胡澳","赵润全","丁瑶","陈毅"], "计科六班":{ "people1":{"name":"胡澳","age":19,"班级":"计算机科学与技术"}, "people2":{"name":"赵润全","age":19,"班级":"计算机科学与技术"} }, "age":19 } #将name中的胡澳替换成huao dict["name"][0] = "huao" print(dict) #在people1中加入爱好 dict["计科六班"]["people1"].setdefault("兴趣爱好","打篮球") print(dict)
运行结果:
D:\常用软件\Python3.7\python文件\python.exe D:/学习资料/项目/练习/lianxi.py {'name': ['huao', '赵润全', '丁瑶', '陈毅'], '计科六班': {'people1': {'name': '胡澳', 'age': 19, '班级': '计算机科学与技术'}, 'people2': {'name': '赵润全', 'age': 19, '班级': '计算机科学与技术'}}, 'age': 19} {'name': ['huao', '赵润全', '丁瑶', '陈毅'], '计科六班': {'people1': {'name': '胡澳', 'age': 19, '班级': '计算机科学与技术', '兴趣爱好': '打篮球'}, 'people2': {'name': '赵润全', 'age': 19, '班级': '计算机科学与技术'}}, 'age': 19} 进程已结束,退出代码0
代码分析:字典的嵌套和列表的嵌套其实相差不大,关键值找准在哪一个层次上,当前层次是那个类型,有什么方法。
本文来自博客园,作者:江湖混子,转载请注明原文链接:https://www.cnblogs.com/huao990928/p/11686451.html

