HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言
首先先介绍一下Jsoup:(摘自官网)
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for extracting and manipulating data, using the best of DOM, CSS, and jquery-like methods.
Jsoup俗称“大杀器”,具体的使用大家可以看 jsoup中文文档
代码编写
首先maven引包:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.9</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
封装几个方法(思路大多都在注解里面,相信大家都看得懂):
/** * 创建.txt文件 * * @param fileName 文件名(小说名) * @return File对象 */ public static File createFile(String fileName) { //获取桌面路径 String comPath = FileSystemView.getFileSystemView().getHomeDirectory().getPath(); //创建空白文件夹:networkNovel File file = new File(comPath + "\\networkNovel\\" + fileName + ".txt"); try { //获取父目录 File fileParent = file.getParentFile(); if (!fileParent.exists()) { fileParent.mkdirs(); } //创建文件 if (!file.exists()) { file.createNewFile(); } } catch (Exception e) { file = null; System.err.println("新建文件操作出错"); e.printStackTrace(); } return file; } /** * 字符流写入文件 * * @param file file对象 * @param value 要写入的数据 */ public static void fileWriter(File file, String value) { //字符流 try { FileWriter resultFile = new FileWriter(file, true);//true,则追加写入 PrintWriter myFile = new PrintWriter(resultFile); //写入 myFile.println(value); myFile.println("\n"); myFile.close(); resultFile.close(); } catch (Exception e) { System.err.println("写入操作出错"); e.printStackTrace(); } } /** * 采集当前url完整response实体.toString() * * @param url url * @return response实体.toString() */ public static String gather(String url,String refererUrl) { String result = null; try { //创建httpclient对象 (这里设置成全局变量,相对于同一个请求session、cookie会跟着携带过去) CloseableHttpClient httpClient = HttpClients.createDefault(); //创建get方式请求对象 HttpGet httpGet = new HttpGet(url); httpGet.addHeader("Content-type", "application/json"); //包装一下 httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"); httpGet.addHeader("Referer", refererUrl); httpGet.addHeader("Connection", "keep-alive"); //通过请求对象获取响应对象 CloseableHttpResponse response = httpClient.execute(httpGet); //获取结果实体 if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) { result = EntityUtils.toString(response.getEntity(), "GBK"); } //释放链接 response.close(); } //这里还可以捕获超时异常,重新连接抓取 catch (Exception e) { result = null; System.err.println("采集操作出错"); e.printStackTrace(); } return result; } /** * 使用jsoup处理html字符串,根据规则,得到当前章节名以及完整内容跟下一章的链接地址 * 每个站点的代码风格都不一样,所以规则要根据不同的站点去修改
* 比如这里的文章内容直接用一个div包起来,而有些站点是每个段落用p标签包起来 * @param html html字符串 * @return Map<String,String> */ public static Map<String, String> processor(String html) { HashMap<String, String> map = new HashMap<>(); String chapterName;//章节名 String chapter = null;//完整章节(包括章节名) String next = null;//下一章链接地址 try { //解析html格式的字符串成一个Document Document doc = Jsoup.parse(html); //章节名称 Elements bookname = doc.select("div.bookname > h1"); chapterName = bookname.text().trim(); chapter = chapterName +"\n"; //文章内容 Elements content = doc.select("div#content"); String replaceText = content.text().replace(" ", "\n"); chapter = chapter + replaceText; //下一章 Elements nextText = doc.select("a:matches((?i)下一章)"); if (nextText.size() > 0) { next = nextText.attr("href"); } map.put("chapterName", chapterName);//章节名称 map.put("chapter", chapter);//完整章节内容 map.put("next", next);//下一章链接地址 } catch (Exception e) { map = null; System.err.println("处理数据操作出错"); e.printStackTrace(); } return map; } /** * 递归写入完整的一本书 * @param file file * @param baseUrl 基础url * @param url 当前url * @param refererUrl refererUrl */ public static void mergeBook(File file, String baseUrl, String url, String refererUrl) { String html = gather(baseUrl + url,baseUrl +refererUrl); Map<String, String> map = processor(html); //追加写入 fileWriter(file, map.get("chapter")); System.out.println(map.get("chapterName") + " --100%"); if (!StringUtils.isEmpty(map.get("next"))) {
//递归 mergeBook(file, baseUrl, map.get("next"),url); } }
main测试:
public static void main(String[] args) { //需要提供的条件:站点;小说名;第一章的链接;refererUrl String baseUrl = "http://www.biquge.com.tw"; File file = createFile("斗破苍穹"); mergeBook(file, baseUrl, "/1_1999/1179371.html","/1_1999/"); }
效果
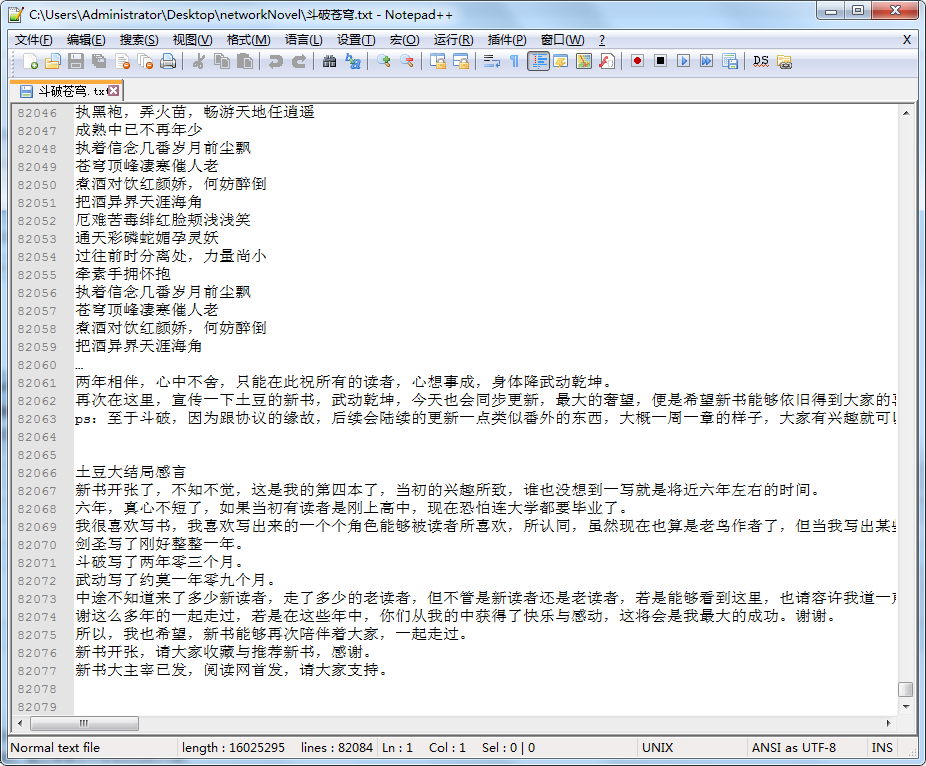
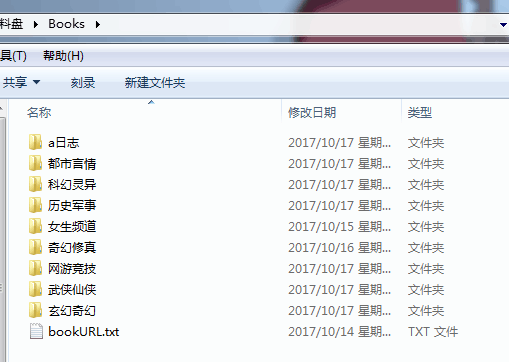
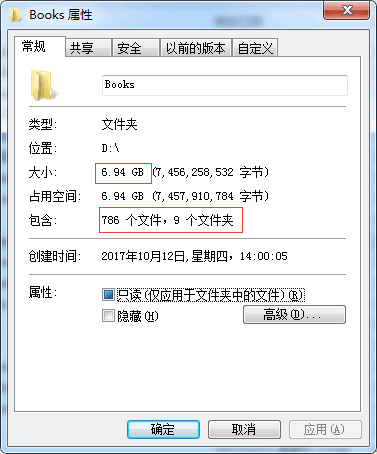
给大家看一下我之前爬取的数据,多开几个进程,挂机爬,差不多七个G,七百八十多部小说
代码开源
代码已经开源、托管到我的GitHub、码云:
版权声明
作者:huanzi-qch
若标题中有“转载”字样,则本文版权归原作者所有。若无转载字样,本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利.
捐献、打赏
请注意:相应的资金支持能更好的持续开源和创作,如果喜欢这篇文章,请随意打赏!

支付宝

微信
交流群
有事请加群,有问题进群大家一起交流!



