博客园随笔备份Java脚本
前言
不知不觉已经写了104篇随笔了,为了避免发生意外造成博客丢失,我们写一个备份脚本对博客进行备份
1、备份格式我们选择md文档格式
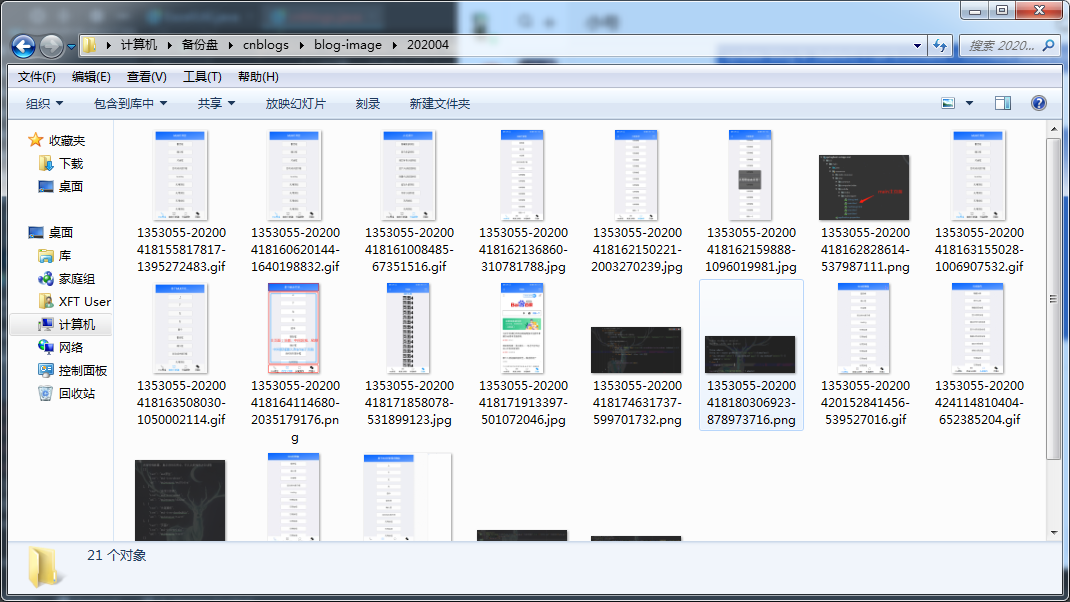
2、图片要下载到本地,方便我们统一上传图床
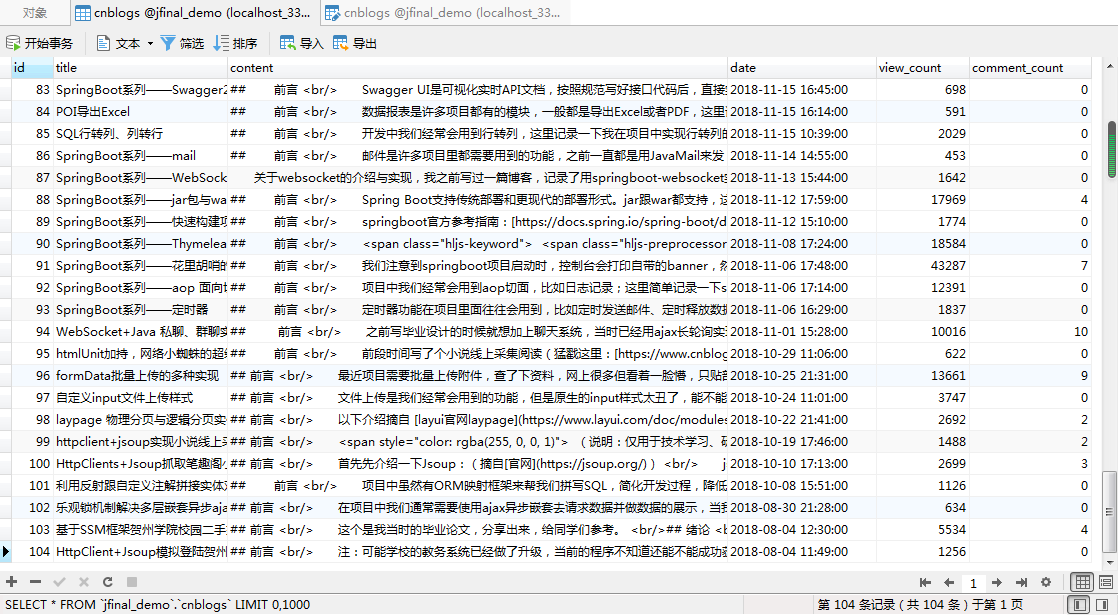
3、博客数据入库,可以用mysql
我们选用Java爬虫神器:HtmlUnit(详情请戳:htmlUnit加持,网络小蜘蛛的超级进化)进行文章的采集、html结构分析
博客结构分析
我们的文章结构还是挺简单的,主要就以下几个内容
0、文章标题,id=cb_post_title_url的a标签
1、文章内容,id=cnblogs_post_body的div标签
1】、二、三级标题,h2、h3标签
2】、代码,div标签
3】、表格,table标签
4】、其他,其他内容被p标签包成一行,按p标签内容可分成以下几种:
1)、图片,p标签内容里有img标签
2)、链接,p标签内容里有a标签
3)、标红文字,p标签内容里有span标签
4)、普通文字
对应md文档格式

代码编写
首先需要引入pom依赖、以及建表
<!-- htmlunit --> <dependency> <groupId>net.sourceforge.htmlunit</groupId> <artifactId>htmlunit</artifactId> <version>2.53.0</version> </dependency> <!-- mysql 驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> <!-- hutool-all --> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.4</version> </dependency>
CREATE TABLE `cnblogs` ( `id` int(4) NOT NULL COMMENT '表主键', `title` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '标题', `content` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT '内容(md文档格式)', `date` datetime NULL DEFAULT NULL COMMENT '发布时间', `view_count` int(7) NULL DEFAULT NULL COMMENT '阅读数', `comment_count` int(3) NULL DEFAULT NULL COMMENT '评论数', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '博客园博客备份表' ROW_FORMAT = Compact;
根据博客主页,抓取全部博客地址
/** * 获取所有博客地址 */ private static ArrayList<String> getUrls(WebClient webClient, String url,int pageNumber) throws IOException, InterruptedException { ArrayList<String> arrayList = new ArrayList<>(10); //发起请求 HtmlPage page = webClient.getPage(url + pageNumber); //获取URL for (DomNode domNode : page.querySelectorAll("div.postTitle")) { arrayList.add(domNode.querySelector("a.postTitle2").getAttributes().getNamedItem("href").getTextContent()); } //下一页 if(page.querySelector("div.topicListFooter").asNormalizedText().contains("下一页")){ //随机休眠 Thread.sleep(RandomUtil.randomInt(1000, 2000)); ArrayList<String> urls = getUrls(webClient,url,pageNumber+1); arrayList.addAll(urls); } return arrayList; }
调用
//获取所有博客链接 ArrayList<String> arrayList = getUrls(webClient, url + "/default.html?page=", 1);
根据URL获取博客内容,解析html转成md文档格式
/** * 根据URL获取博客内容,解析html转成md文档格式 * 1、下载保存图片 * 2、保存md文档 * 3、返回博客信息,如果需要可以存库 */ private static Map<Object, Object> task(WebClient webClient,String url) throws IOException, InterruptedException { //发起请求 HtmlPage page = webClient.getPage(url); //发布时间 DomNode postDate = page.querySelector("span#post-date"); String date = postDate.asNormalizedText(); //阅读数 DomNode postViewCount = page.querySelector("span#post_view_count"); String viewCount = postViewCount.asNormalizedText(); //评论数 DomNode postCommentCount = page.querySelector("span#post_comment_count"); String commentCount = postCommentCount.asNormalizedText(); //标题 DomNode postTitle = page.querySelector("a#cb_post_title_url"); String titleName = postTitle.asNormalizedText(); //内容 StringBuilder stringBuilder = new StringBuilder(); DomNodeList<DomNode> childNodes = page.querySelector("div#cnblogs_post_body").getChildNodes(); DomNode[] array = new DomNode[childNodes.size()]; array = childNodes.toArray(array); List<DomNode> psParamList = new ArrayList<>(Arrays.asList(array)); for (int i = 0; i < psParamList.size(); i++) { DomNode childNode = psParamList.get(i); //<div class="para"> Node aClass = childNode.getAttributes().getNamedItem("class"); if("div".equals(childNode.getNodeName()) && aClass != null && "para".equals(aClass.getTextContent())){ psParamList.addAll(i,childNode.getChildNodes()); psParamList.remove(childNode); i--; continue; } //h2,二级标题 if("h2".equals(childNode.getNodeName())){ String text = childNode.asNormalizedText(); if(!"".equals(text.trim().replaceAll(" ",""))){ stringBuilder.append("## ").append(text).append(" <br/>\n"); } continue; } //h3,三级标题 if("h3".equals(childNode.getNodeName())){ String text = childNode.asNormalizedText(); if(!"".equals(text.trim().replaceAll(" ",""))){ stringBuilder.append("### ").append(text).append(" <br/>\n"); } continue; } //div,代码内容 if("div".equals(childNode.getNodeName()) && aClass != null && "cnblogs_code".equals(aClass.getTextContent())){ stringBuilder.append("```").append("\n"); stringBuilder.append(childNode.asNormalizedText()).append("\n"); stringBuilder.append("```").append("\n"); continue; } //table,表格内容 if("table".equals(childNode.getNodeName())){ DomNodeList<DomNode> trDomNodes = childNode.querySelectorAll("tr"); stringBuilder.append("\n"); for (int j = 0; j < trDomNodes.size(); j++) { DomNode trDomNode = trDomNodes.get(j); DomNodeList<DomNode> tdDomNodes = trDomNode.querySelectorAll("td"); for (DomNode tdDomNode : tdDomNodes) { stringBuilder.append("|").append(tdDomNode.asNormalizedText()); } stringBuilder.append("|\n"); //标题 if(j == 0){ for (int k = 0; k < tdDomNodes.size(); k++) { stringBuilder.append("|:----:"); } stringBuilder.append("|\n"); } } stringBuilder.append(" <br/>\n"); continue; } //文本内容 //图片 if(childNode.asXml().contains("<img")){ DomNodeList<DomNode> imgDomNodes = childNode.querySelectorAll("img"); DomNode[] array1 = new DomNode[imgDomNodes.size()]; array1 = imgDomNodes.toArray(array1); List<DomNode> psParamList1 = new ArrayList<>(Arrays.asList(array1)); if(psParamList1.size() <= 0){ psParamList1.add(childNode); } for (DomNode imgDomNode : psParamList1) { Node srcItem = imgDomNode.getAttributes().getNamedItem("src"); if(srcItem == null){ break; } //得到图片网络地址 String src = srcItem.getTextContent(); //将文件下载后保存 String[] split = src.split("/1353055/"); //图片保存路径,随机休眠1-2秒,重要:先下载到本地,再上传到图床 if(isDownloadImg){ File file = new File("F:/cnblogs/blog-image/" + split[1]); if(!file.exists()){ Thread.sleep(RandomUtil.randomInt(1000, 2000)); HttpUtil.downloadFile(src, file); } //写入新路径 stringBuilder.append(".append(imgPath).append(split[1]).append(")").append(" "); }else{ //写入src路径 stringBuilder.append(".append(src).append(")").append(" "); } } stringBuilder.append(" <br/>\n"); } //标注字体颜色 else if(childNode.getLastChild() != null && "span".equals(childNode.getLastChild().getNodeName())){ DomNode span = childNode.getLastChild(); stringBuilder.append(" ").append(span.asXml().replaceAll("\r","").replaceAll("\n","")).append(" <br/>\n"); } //包含a标签 else if(childNode.asXml().contains("</a>")){ String newPText = childNode.asNormalizedText(); DomNodeList<DomNode> aDomNodes = childNode.querySelectorAll("a"); for (DomNode aDomNode : aDomNodes) { String text = aDomNode.asNormalizedText(); String href = aDomNode.getAttributes().getNamedItem("href").getTextContent(); String newStr = "["+text+"]("+href+")"; newPText = newPText.replace(text,newStr); } //替换 stringBuilder.append(newPText).append(" <br/>\n"); } //普通文字 else{ String pText = childNode.asNormalizedText(); if(StrUtil.isBlankIfStr(pText)){ stringBuilder.append("\n"); }else{ //四个空格转换 stringBuilder.append(pText.replaceFirst(" "," ")).append(" <br/>\n"); } } } //生成md文档(文件名不能包含特殊字符:\,/,:,*,?,",<,>,|) String titleNameFileName = titleName .replaceAll("\\\\","_") .replaceAll("/","_") .replaceAll(":","_") .replaceAll("\\*","_") .replaceAll("\\?","_") .replaceAll("\"","_") .replaceAll("<","_") .replaceAll(">","_") .replaceAll("\\|","_") ; FileUtil.fileWriter(FileUtil.createFile("F:\\cnblogs\\《"+ titleNameFileName +"》.md"),stringBuilder); System.out.println("《"+titleName+"》备份完成!"); return MapUtil.builder() .put("title", titleName) .put("content", stringBuilder.toString()) .put("date", date) .put("view_count", viewCount) .put("comment_count", commentCount) .build(); }
然后再循环遍历所有博客链接
for (int i = 0; i < arrayList.size(); i++) { Map<Object, Object> paramMap =task(webClient,arrayList.get(i)); //新增入库 if(isPutDataBase){ paramMap.put("id",i+1); db.execute("insert into cnblogs values (:id, :title, :content, :date, :view_count, :comment_count)",paramMap); } //随机休眠5-10秒 Thread.sleep(RandomUtil.randomInt(5000, 10000)); }
下载图片用的是hutool库的HttpUtil.downloadFile方法
//得到图片网络地址 String src = srcItem.getTextContent(); //将文件下载后保存 String[] split = src.split("/1353055/"); //图片保存路径,随机休眠1-2秒,重要:先下载到本地,再上传到图床 if(isDownloadImg){ File file = new File("F:/cnblogs/blog-image/" + split[1]); if(!file.exists()){ Thread.sleep(RandomUtil.randomInt(1000, 2000)); HttpUtil.downloadFile(src, file); } //写入新路径 stringBuilder.append(".append(imgPath).append(split[1]).append(")").append(" "); }else{ //写入src路径 stringBuilder.append(".append(src).append(")").append(" "); }
数据入库,用的是hutool库封装的jdbc方法
public static void main(String[] args) { //hutool工具类,使用jdbc进行查询 try { // Oracle //SimpleDataSource ds = new SimpleDataSource("jdbc:oracle:thin:@localhost:1521:orcl", "test", "test"); // MySQL SimpleDataSource ds = new SimpleDataSource("jdbc:mysql://localhost/jfinal_demo", "root", "123456"); //使用简单 Db use = Db.use(ds); //查询 List<Entity> result = use.query("select * from user where name like ?","%张三%"); for (Entity entity : result) { System.out.println(JSONUtil.toJsonStr(entity)); } //更新 Map<Object, Object> paramMap = MapUtil.builder() .put("name", "张三") .put("id", 3) .build(); use.execute("update user set name = :name where id = :id", paramMap); //关闭连接 use.closeConnection(use.getConnection()); } catch (SQLException e) { e.printStackTrace(); } //hutool工具类,使用jdbc进行查询 try { // Oracle //SimpleDataSource ds = new SimpleDataSource("jdbc:oracle:thin:@localhost:1521:orcl", "test", "test"); // MySQL SimpleDataSource ds = new SimpleDataSource("jdbc:mysql://localhost/jfinal_demo", "root", "123456"); //带事务 Session session = Session.create(ds); List<Entity> result1 = session.query("select * from user where name like ?", "%张三%"); for (Entity entity : result1) { System.out.println(JSONUtil.toJsonStr(entity)); } for (int i = 0; i < 10; i++) { session.execute("update user set name = ? where id = ?","name"+i,i); } session.commit(); //关闭连接 session.closeConnection(session.getConnection()); } catch (SQLException e) { e.printStackTrace(); } }
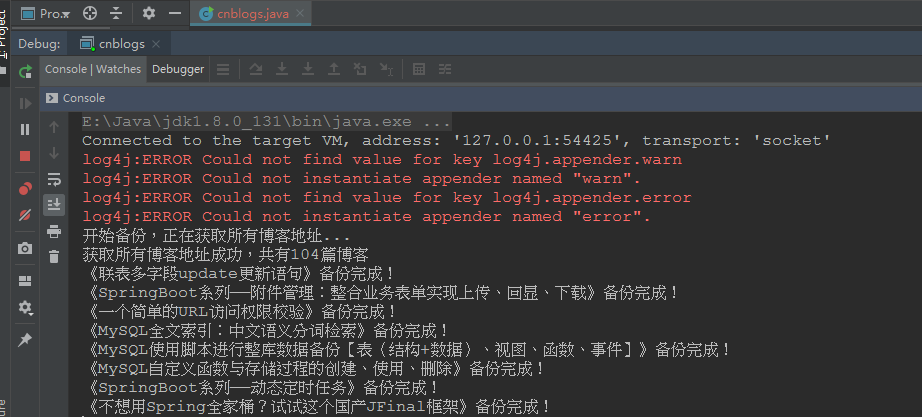
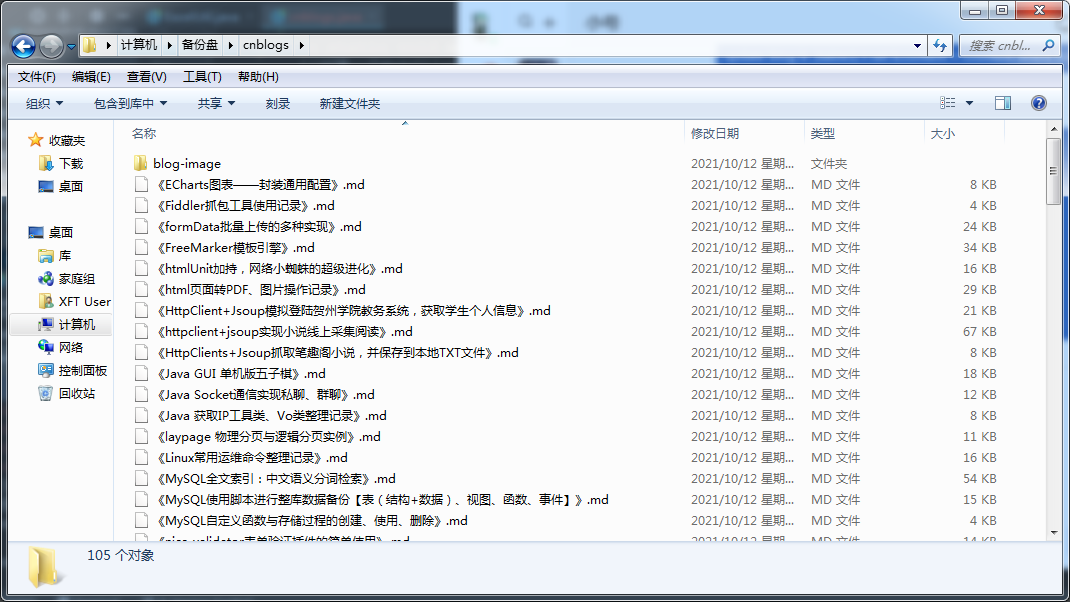
效果演示
直接运行main入口函数


后记
pom引入依赖


<!-- htmlunit -->
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.53.0</version>
</dependency>
<!-- mysql 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
<!-- hutool-all -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.4</version>
</dependency>
建表sql语句
CREATE TABLE `cnblogs` ( `id` int(4) NOT NULL COMMENT '表主键', `title` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '标题', `content` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT '内容(md文档格式)', `date` datetime NULL DEFAULT NULL COMMENT '发布时间', `view_count` int(7) NULL DEFAULT NULL COMMENT '阅读数', `comment_count` int(3) NULL DEFAULT NULL COMMENT '评论数', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '博客园博客备份表' ROW_FORMAT = Compact;
完整Java脚本代码
import cn.hutool.core.date.DateUtil; import cn.hutool.core.date.TimeInterval; import cn.hutool.core.map.MapUtil; import cn.hutool.core.util.RandomUtil; import cn.hutool.core.util.StrUtil; import cn.hutool.db.Db; import cn.hutool.db.ds.simple.SimpleDataSource; import cn.hutool.http.HttpUtil; import com.gargoylesoftware.htmlunit.BrowserVersion; import com.gargoylesoftware.htmlunit.WebClient; import com.gargoylesoftware.htmlunit.html.DomNode; import com.gargoylesoftware.htmlunit.html.DomNodeList; import com.gargoylesoftware.htmlunit.html.HtmlPage; import org.w3c.dom.Node; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.io.PrintWriter; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.Map; /** * 博客园随笔备份Java脚本 * * 需要提前设置博客主页地址(用于获取全部博客地址)、图床路径(生成的md文档中,图片的路径将会替换成我们的图床路径) * 匹配规则不一样全部适用,需要对task方法进行针对性调整 */ /* 需要引入依赖 <!-- htmlunit 2.53.0 --> <dependency> <groupId>net.sourceforge.htmlunit</groupId> <artifactId>htmlunit</artifactId> <version>2.53.0</version> </dependency> <!-- mysql 驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> <!-- oracle 驱动 --> <!--<dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>11.2.0.3</version> </dependency>--> <!-- hutool-all --> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.4</version> </dependency> 建表SQL语句 CREATE TABLE `cnblogs` ( `id` int(4) NOT NULL COMMENT '表主键', `title` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '标题', `content` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT '内容(md文档格式)', `date` datetime NULL DEFAULT NULL COMMENT '发布时间', `view_count` int(7) NULL DEFAULT NULL COMMENT '阅读数', `comment_count` int(3) NULL DEFAULT NULL COMMENT '评论数', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '博客园博客备份表' ROW_FORMAT = Compact; */ public class cnblogs { /** * 可以先测试一篇博客 * urlByTest不为空则仅进行备份测试,为空则进行正式备份 */ private static String urlByTest = null; static{ // urlByTest = "https://www.cnblogs.com/huanzi-qch/p/9930390.html"; } /** * 博客主页地址 */ private static String url = "https://www.cnblogs.com/huanzi-qch"; /** * 图床地址 * PS:如果下载图片到本地,则需要配置图床地址 */ private static String imgPath = ""; /** * 是否下载图片到本地 */ private static boolean isDownloadImg = false; /** * 是否入库 */ private static boolean isPutDataBase = false; /** * main入口函数 */ public static void main(String[] args) { //创建一个WebClient,并模拟特定的浏览器 try (WebClient webClient = new WebClient(BrowserVersion.FIREFOX_78)) { webClient.getOptions().setJavaScriptEnabled(false);//禁用js webClient.getOptions().setCssEnabled(false);//禁用css webClient.getOptions().setTimeout(10000); //设置连接超时时间 // hutool工具类,使用jdbc进行操作 SimpleDataSource ds; Db db = null; if(isPutDataBase){ ds = new SimpleDataSource("jdbc:mysql://localhost/jfinal_demo", "root", "123456"); // ds = new SimpleDataSource("jdbc:oracle:thin:@localhost:1521:orcl", "test", "test"); db = Db.use(ds); } //测试备份一篇 if(urlByTest != null){ Map<Object, Object> paramMap =task(webClient,urlByTest); //新增入库 if(isPutDataBase){ paramMap.put("id",RandomUtil.randomInt(1, 10000)); db.execute("insert into cnblogs values (:id, :title, :content, :date, :view_count, :comment_count)",paramMap); } System.out.println("测试备份完成!"); return; } //计时器 TimeInterval timer = DateUtil.timer(); System.out.println("开始备份,正在获取所有博客地址..."); //获取所有博客链接 ArrayList<String> arrayList = getUrls(webClient, url + "/default.html?page=", 1); System.out.println("获取所有博客地址成功,共有"+arrayList.size()+"篇博客"); //清空表 if(isPutDataBase) { db.execute("truncate table cnblogs"); } for (int i = 0; i < arrayList.size(); i++) { Map<Object, Object> paramMap =task(webClient,arrayList.get(i)); //新增入库 if(isPutDataBase){ paramMap.put("id",i+1); db.execute("insert into cnblogs values (:id, :title, :content, :date, :view_count, :comment_count)",paramMap); } //随机休眠 Thread.sleep(RandomUtil.randomInt(1000, 2000)); } System.out.println(arrayList.size()+"篇博客备份全部完成!耗时:"+(timer.intervalMinute()) + "分钟"); }catch (Exception e){ System.err.println("备份出错!!"); e.printStackTrace(); } } /** * file工具类 */ private static class FileUtil { /** * 创建文件 * * @param pathNameAndFileName 路径跟文件名 * @return File对象 */ private static File createFile(String pathNameAndFileName) { File file = new File(pathNameAndFileName); try { //获取父目录 File fileParent = file.getParentFile(); if (!fileParent.exists()) { fileParent.mkdirs(); } //创建文件 if (!file.exists()) { file.createNewFile(); } } catch (Exception e) { file = null; System.err.println("新建文件操作出错"); e.printStackTrace(); } return file; } /** * 字符流写入文件 * * @param file file对象 * @param stringBuilder 要写入的数据 */ private static void fileWriter(File file, StringBuilder stringBuilder) { //字符流 try { FileWriter resultFile = new FileWriter(file, false);//true,则追加写入 false,则覆盖写入 PrintWriter myFile = new PrintWriter(resultFile); //写入 myFile.println(stringBuilder.toString()); myFile.close(); resultFile.close(); } catch (Exception e) { System.err.println("写入操作出错"); e.printStackTrace(); } } } /** * 根据URL获取博客内容,解析html转成md文档格式 * 1、下载保存图片 * 2、保存md文档 * 3、返回博客信息,如果需要可以存库 */ private static Map<Object, Object> task(WebClient webClient,String url) throws IOException, InterruptedException { //发起请求 HtmlPage page = webClient.getPage(url); //发布时间 DomNode postDate = page.querySelector("span#post-date"); String date = postDate.asNormalizedText(); //阅读数 DomNode postViewCount = page.querySelector("span#post_view_count"); String viewCount = postViewCount.asNormalizedText(); //评论数 DomNode postCommentCount = page.querySelector("span#post_comment_count"); String commentCount = postCommentCount.asNormalizedText(); //标题 DomNode postTitle = page.querySelector("a#cb_post_title_url"); String titleName = postTitle.asNormalizedText(); //内容 StringBuilder stringBuilder = new StringBuilder(); DomNodeList<DomNode> childNodes = page.querySelector("div#cnblogs_post_body").getChildNodes(); DomNode[] array = new DomNode[childNodes.size()]; array = childNodes.toArray(array); List<DomNode> psParamList = new ArrayList<>(Arrays.asList(array)); for (int i = 0; i < psParamList.size(); i++) { DomNode childNode = psParamList.get(i); //<div class="para"> Node aClass = childNode.getAttributes().getNamedItem("class"); if("div".equals(childNode.getNodeName()) && aClass != null && "para".equals(aClass.getTextContent())){ psParamList.addAll(i,childNode.getChildNodes()); psParamList.remove(childNode); i--; continue; } //h2,二级标题 if("h2".equals(childNode.getNodeName())){ String text = childNode.asNormalizedText(); if(!"".equals(text.trim().replaceAll(" ",""))){ stringBuilder.append("## ").append(text).append(" <br/>\n"); } continue; } //h3,三级标题 if("h3".equals(childNode.getNodeName())){ String text = childNode.asNormalizedText(); if(!"".equals(text.trim().replaceAll(" ",""))){ stringBuilder.append("### ").append(text).append(" <br/>\n"); } continue; } //div,代码内容 if("div".equals(childNode.getNodeName()) && aClass != null && "cnblogs_code".equals(aClass.getTextContent())){ stringBuilder.append("```").append("\n"); stringBuilder.append(childNode.asNormalizedText()).append("\n"); stringBuilder.append("```").append("\n"); continue; } //table,表格内容 if("table".equals(childNode.getNodeName())){ DomNodeList<DomNode> trDomNodes = childNode.querySelectorAll("tr"); stringBuilder.append("\n"); for (int j = 0; j < trDomNodes.size(); j++) { DomNode trDomNode = trDomNodes.get(j); DomNodeList<DomNode> tdDomNodes = trDomNode.querySelectorAll("td"); for (DomNode tdDomNode : tdDomNodes) { stringBuilder.append("|").append(tdDomNode.asNormalizedText()); } stringBuilder.append("|\n"); //标题 if(j == 0){ for (int k = 0; k < tdDomNodes.size(); k++) { stringBuilder.append("|:----:"); } stringBuilder.append("|\n"); } } stringBuilder.append(" <br/>\n"); continue; } //文本内容 //图片 if(childNode.asXml().contains("<img")){ DomNodeList<DomNode> imgDomNodes = childNode.querySelectorAll("img"); DomNode[] array1 = new DomNode[imgDomNodes.size()]; array1 = imgDomNodes.toArray(array1); List<DomNode> psParamList1 = new ArrayList<>(Arrays.asList(array1)); if(psParamList1.size() <= 0){ psParamList1.add(childNode); } for (DomNode imgDomNode : psParamList1) { Node srcItem = imgDomNode.getAttributes().getNamedItem("src"); if(srcItem == null){ break; } //得到图片网络地址 String src = srcItem.getTextContent(); //将文件下载后保存 String[] split = src.split("/1353055/"); //图片保存路径,随机休眠1-2秒,重要:先下载到本地,再上传到图床 if(isDownloadImg){ File file = new File("F:/cnblogs/blog-image/" + split[1]); if(!file.exists()){ Thread.sleep(RandomUtil.randomInt(1000, 2000)); HttpUtil.downloadFile(src, file); } //写入新路径 stringBuilder.append(".append(imgPath).append(split[1]).append(")").append(" "); }else{ //写入src路径 stringBuilder.append(".append(src).append(")").append(" "); } } stringBuilder.append(" <br/>\n"); } //标注字体颜色 else if(childNode.getLastChild() != null && "span".equals(childNode.getLastChild().getNodeName())){ DomNode span = childNode.getLastChild(); stringBuilder.append(" ").append(span.asXml().replaceAll("\r","").replaceAll("\n","")).append(" <br/>\n"); } //包含a标签 else if(childNode.asXml().contains("</a>")){ String newPText = childNode.asNormalizedText(); DomNodeList<DomNode> aDomNodes = childNode.querySelectorAll("a"); for (DomNode aDomNode : aDomNodes) { String text = aDomNode.asNormalizedText(); String href = aDomNode.getAttributes().getNamedItem("href").getTextContent(); String newStr = "["+text+"]("+href+")"; newPText = newPText.replace(text,newStr); } //替换 stringBuilder.append(newPText).append(" <br/>\n"); } //普通文字 else{ String pText = childNode.asNormalizedText(); if(StrUtil.isBlankIfStr(pText)){ stringBuilder.append("\n"); }else{ //四个空格转换 stringBuilder.append(pText.replaceFirst(" "," ")).append(" <br/>\n"); } } } //生成md文档(文件名不能包含特殊字符:\,/,:,*,?,",<,>,|) String titleNameFileName = titleName .replaceAll("\\\\","_") .replaceAll("/","_") .replaceAll(":","_") .replaceAll("\\*","_") .replaceAll("\\?","_") .replaceAll("\"","_") .replaceAll("<","_") .replaceAll(">","_") .replaceAll("\\|","_") ; FileUtil.fileWriter(FileUtil.createFile("F:\\cnblogs\\《"+ titleNameFileName +"》.md"),stringBuilder); System.out.println("《"+titleName+"》备份完成!"); return MapUtil.builder() .put("title", titleName) .put("content", stringBuilder.toString()) .put("date", date) .put("view_count", viewCount) .put("comment_count", commentCount) .build(); } /** * 获取所有博客地址 */ private static ArrayList<String> getUrls(WebClient webClient, String url,int pageNumber) throws IOException, InterruptedException { ArrayList<String> arrayList = new ArrayList<>(10); //发起请求 HtmlPage page = webClient.getPage(url + pageNumber); //获取URL for (DomNode domNode : page.querySelectorAll("div.postTitle")) { arrayList.add(domNode.querySelector("a.postTitle2").getAttributes().getNamedItem("href").getTextContent()); } //下一页 if(page.querySelector("div.topicListFooter").asNormalizedText().contains("下一页")){ //随机休眠 Thread.sleep(RandomUtil.randomInt(1000, 2000)); ArrayList<String> urls = getUrls(webClient,url,pageNumber+1); arrayList.addAll(urls); } return arrayList; } }
几点注意事项:
0、Java备份脚本使用要遵纪守法,备份下来的博客数据仅用于数据备份,备份设置5-10秒间隙,不要影响到网站的正常使用
1、文件名不能有特殊字符
2、数据库表的内容字段,字符集要utf8mb4,类型要mediumtext

代码开源
代码已经开源、托管到我的GitHub、码云:
版权声明
捐献、打赏

支付宝

微信
交流群



