
1. 小括号在正则中:
1.1 小括号:表示分组
1.2 分组之后,,每个组都有一个序号,从左到右,依次为1,2,3.......;可以使用 RegExp.$1,RegExp.$2,RegExp.$3分别获取匹配后的各组的结果
1 <script> 2 // 小括号: 对匹配进行分组 3 // 分组之后, 每个组都有一个序号, 从左到右 依次为1, 2..... 4 var str = 'abca'; 5 // var re = /(a)(b)ca/; 6 var re = /(a)(b)c\1/; // 正则表达式同 /(a)(b)ca/ ; 7 console.log(str.match(re)); 8 //引用分组: \+组序号 引用子组的内容 9 console.log(RegExp.$1); // 获取第一个子组的匹配内容 ,结果为 a 10 console.log(RegExp.$2); // 获取第一个子组的匹配内容 结果为 b 11 </script>

2. 中括号[]:中括号里面的内容,作为一个整体,提配一个字符或者位置
2.1
1 <script> 2 // 中括号[]: 中括号里面的内容 是作为一个整体 匹配一个字符或者位置 3 var str = 'a%c'; 4 var re = /abc/; 5 console.log(re.test(str)); //false 6 var re = /a[bc]c/; 7 console.log(re.test(str)); //false 8 var re = /a[a-zA-Z0-9]c/; 9 console.log(re.test(str)); //false 10 //^:脱字符, 用在中括号中 表示非, 用在中括号外面 表示 以....开头 11 var re = /a[^a-zA-Z0-9]c/; 12 console.log(re.test(str)); //true 13 </script>

2.2
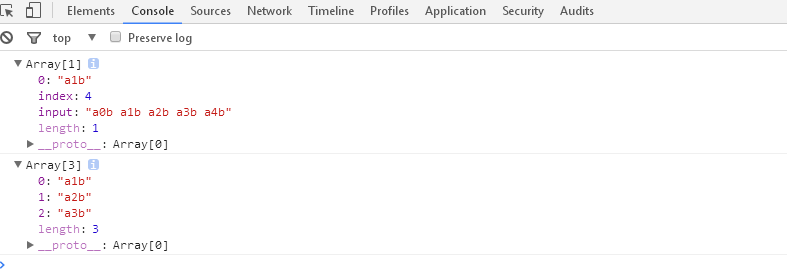
1 <script> 2 var regex1 = /a[123]b/; 3 var regex2 = /a[123]b/g; 4 var string = "a0b a1b a2b a3b a4b"; 5 console.log(string.match(regex1)); // ["a1b"] 6 console.log(string.match(regex2)); // ["a1b", "a2b", "a3b"] 7 </script>
3. 贪婪与惰性匹配
3.1 贪婪匹配
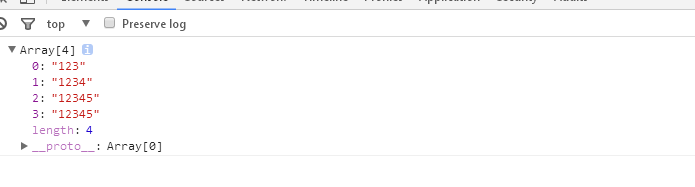
1 <script> 2 // 贪婪匹配,匹配全局 3 var regex = /\d{2,5}/g; //全局匹配2个到5个数字 4 var string = "123 1234 12345 123456"; 5 console.log(string.match(regex)); // ["123", "1234", "12345", "12345"] 6 </script>
3.2 惰性匹配:在正则表达式里加一个 “?”号
1 <script> 2 //?--> 懒惰,能匹配到2个, 我就不会去匹配5个 3 var regex = /\d{2,5}?/g; // 全局懒惰匹配,匹配2个到5个数字 4 var string = "1231234 123 451 23456"; 5 console.log(string.match(regex)); //["12","31","23","12","45","23","45"] 6 </script>

4.分支:
4.1
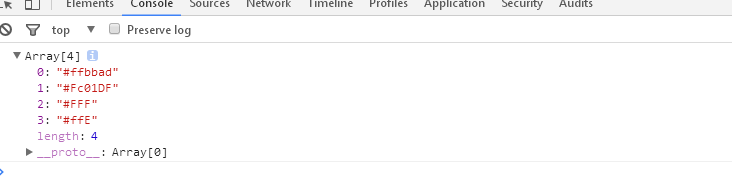
1 <script> 2 // \b: 边界( 空格 ) 3 // 分析: 4 // 1,先分析一个字符串的 所有位置上的 字符组成的可能性 5 // 2,再分析 整体组合规则, 一般在这个时候, 碰到最多的情况就是分组 6 // 3,再思考每个分支的具体条件 7 8 var regex = /#([0-9a-fA-F]{6}\b|[0-9a-fA-F]{3}\b)/g; 9 var string = "#ffbbad #Fc01DF #FFF #ffE #f38a 222 33355462"; 10 console.log(string.match(regex)); //["#ffbbad", "#Fc01DF", "#FFF", "#ffE"] 11 </script>
4.2
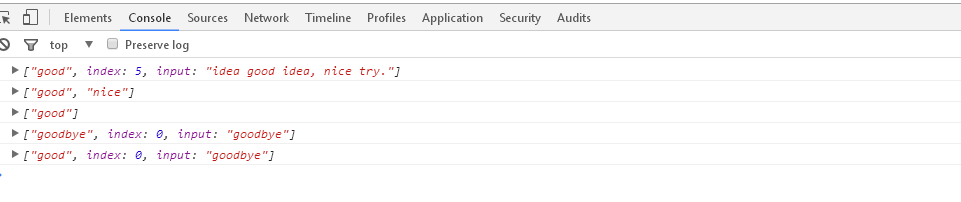
1 <script> 2 var regex = /nice|good/; 3 var regex1 = /nice|good/g; 4 var string = "idea good idea, nice try."; 5 console.log(string.match(regex)); // ["good", index: 5, input: "idea good idea, nice try."] 6 console.log(string.match(regex1)); // ["good", "nice"] 7 8 var regex3 = /good|goodbye/g; 9 var string = "goodbye"; 10 console.log(string.match(regex3)); // ["good"] 11 12 var regex4 = /goodbye|good/; 13 var regex5 = /good|goodbye/; 14 //因为goodbye包含good, 如果想匹配goodbye, 需要把goodbye写在左边 15 var string = "goodbye"; 16 console.log(string.match(regex4)); //["goodbye", index: 0, input: "goodbye"] 17 console.log(string.match(regex5)); //["good", index: 0, input: "goodbye"] 18 </script>
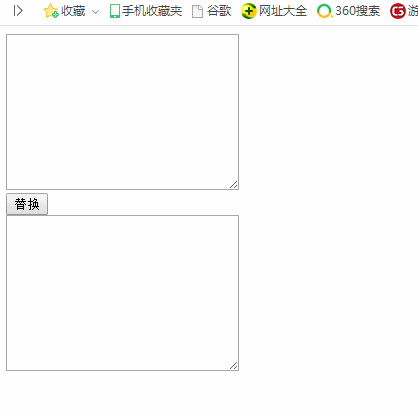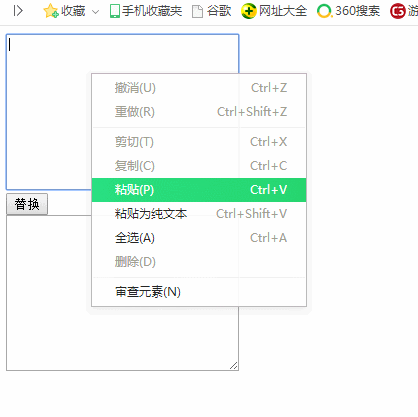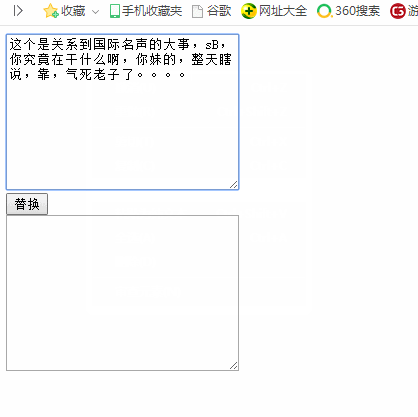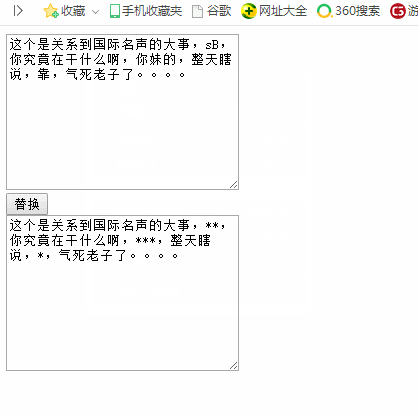
5. 敏感词过滤:
1 <!DOCTYPE html> 2 <html lang="en"> 3 4 <head> 5 <meta charset="UTF-8"> 6 <meta name="viewport" content="width=device-width, initial-scale=1.0"> 7 <meta http-equiv="X-UA-Compatible" content="ie=edge"> 8 <title>Document</title> 9 <script> 10 window.onload = function() { 11 var aT = document.querySelectorAll("textarea"); 12 var oBtn = document.querySelector("input"); 13 oBtn.onclick = function() { 14 //| 叫做分支 15 var re = /Sb|你妹的|靠/ig; 16 // repalce 第一个参数 代表要匹配的正则表达式 17 // replace 第二个参数 function 18 aT[1].value = aT[0].value.replace(re, function(s, s1, s2) { 19 // replace()的function(s,s1,s2)中有三个参数,第一个是传入的待提换的字符串s,第二个是该字符串在整体字符串中的位置s1,第三个是整个字符串s2 20 var temp = ""; 21 for (var i = 0; i < s.length; i++) { 22 temp += "*"; 23 } 24 return temp; 25 }); 26 } 27 } 28 </script> 29 </head> 30 31 <body> 32 <textarea name="" id="" cols="30" rows="10"></textarea> 33 <br> 34 <input type="button" value="替换"> 35 <br> 36 <textarea name="" id="" cols="30" rows="10"></textarea> 37 <br> 38 </body> 39 40 </html>
运行结果:
http://www.cnblogs.com/huanying2015 博客随笔大多数文章均属原创,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利

